 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical and Geometry-Aware Graph Representations for Text-to-CAD
Apr 11, 2026Text-to-CAD code generation is a long-horizon task that translates textual instructions into long sequences of interdependent operations. Existing methods typically decode text directly into executable code (e.g., bpy) without explicitly modeling assembly hierarchy or geometric constraints, which enlarges the search space, accumulates local errors, and often causes cascading failures in complex assemblies. To address this issue, we propose a hierarchical and geometry-aware graph as an intermediate representation. The graph models multi-level parts and components as nodes and encodes explicit geometric constraints as edges. Instead of mapping text directly to code, our framework first predicts structure and constraints, then conditions action sequencing and code generation, thereby improving geometric fidelity and constraint satisfaction. We further introduce a structure-aware progressive curriculum learning strategy that constructs graded tasks through controlled structural edits, explores the model's capability boundary, and synthesizes boundary examples for iterative training. In addition, we build a 12K dataset with instructions, decomposition graphs, action sequences, and bpy code, together with graph- and constraint-oriented evaluation metrics. Extensive experiments show that our method consistently outperforms existing approaches in both geometric fidelity and accurate satisfaction of geometric constraints.
Monocular and Generalizable Gaussian Talking Head Animation
Apr 01, 2025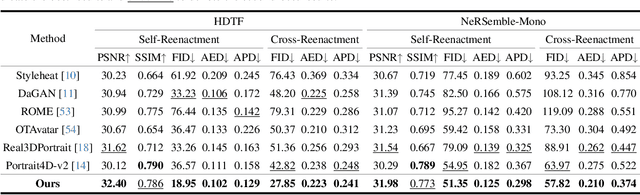
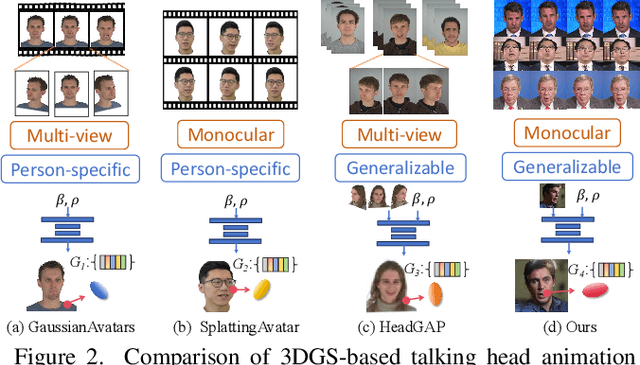
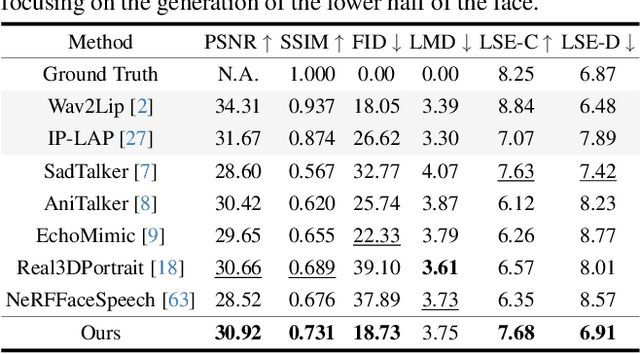
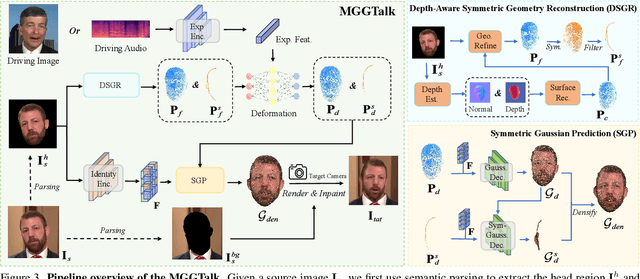
In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.
KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Sep 02, 2024We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: \url{https://github.com/ffxzh/KMTalk}.