 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025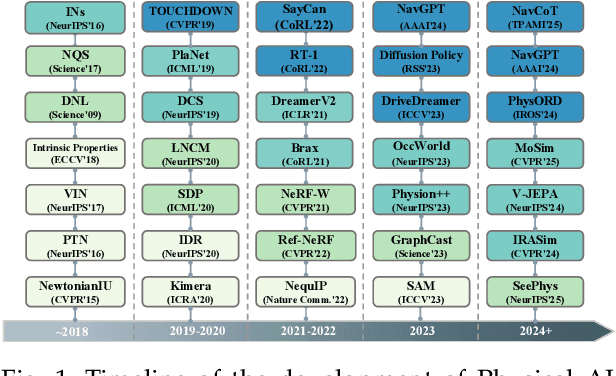
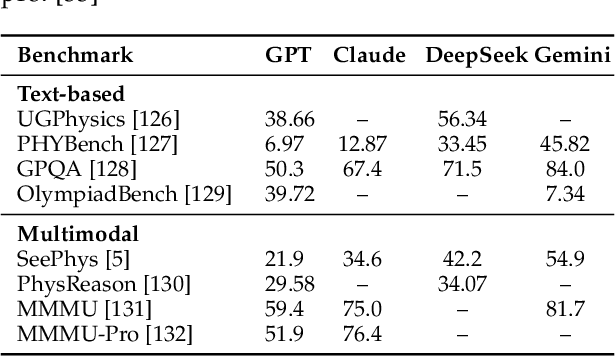
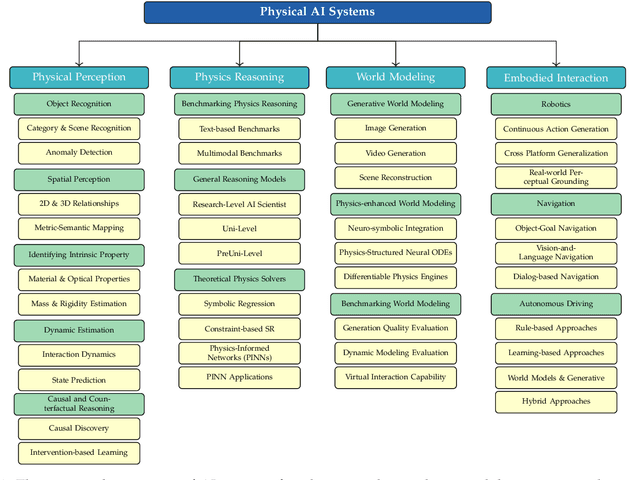
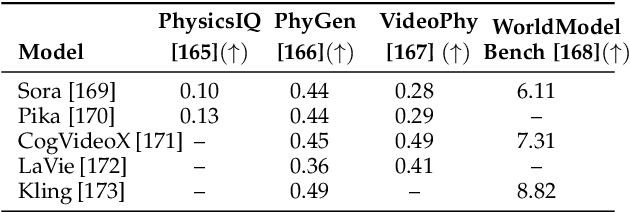
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
LaVieID: Local Autoregressive Diffusion Transformers for Identity-Preserving Video Creation
Aug 11, 2025

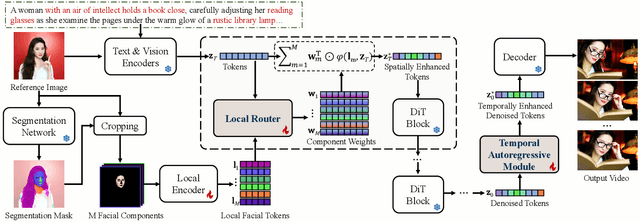

In this paper, we present LaVieID, a novel \underline{l}ocal \underline{a}utoregressive \underline{vi}d\underline{e}o diffusion framework designed to tackle the challenging \underline{id}entity-preserving text-to-video task. The key idea of LaVieID is to mitigate the loss of identity information inherent in the stochastic global generation process of diffusion transformers (DiTs) from both spatial and temporal perspectives. Specifically, unlike the global and unstructured modeling of facial latent states in existing DiTs, LaVieID introduces a local router to explicitly represent latent states by weighted combinations of fine-grained local facial structures. This alleviates undesirable feature interference and encourages DiTs to capture distinctive facial characteristics. Furthermore, a temporal autoregressive module is integrated into LaVieID to refine denoised latent tokens before video decoding. This module divides latent tokens temporally into chunks, exploiting their long-range temporal dependencies to predict biases for rectifying tokens, thereby significantly enhancing inter-frame identity consistency. Consequently, LaVieID can generate high-fidelity personalized videos and achieve state-of-the-art performance. Our code and models are available at https://github.com/ssugarwh/LaVieID.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025



Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
SeePhys: Does Seeing Help Thinking? -- Benchmarking Vision-Based Physics Reasoning
May 25, 2025We present SeePhys, a large-scale multimodal benchmark for LLM reasoning grounded in physics questions ranging from middle school to PhD qualifying exams. The benchmark covers 7 fundamental domains spanning the physics discipline, incorporating 21 categories of highly heterogeneous diagrams. In contrast to prior works where visual elements mainly serve auxiliary purposes, our benchmark features a substantial proportion of vision-essential problems (75\%) that mandate visual information extraction for correct solutions. Through extensive evaluation, we observe that even the most advanced visual reasoning models (e.g., Gemini-2.5-pro and o4-mini) achieve sub-60\% accuracy on our benchmark. These results reveal fundamental challenges in current large language models' visual understanding capabilities, particularly in: (i) establishing rigorous coupling between diagram interpretation and physics reasoning, and (ii) overcoming their persistent reliance on textual cues as cognitive shortcuts.
FireEdit: Fine-grained Instruction-based Image Editing via Region-aware Vision Language Model
Mar 25, 2025Currently, instruction-based image editing methods have made significant progress by leveraging the powerful cross-modal understanding capabilities of vision language models (VLMs). However, they still face challenges in three key areas: 1) complex scenarios; 2) semantic consistency; and 3) fine-grained editing. To address these issues, we propose FireEdit, an innovative Fine-grained Instruction-based image editing framework that exploits a REgion-aware VLM. FireEdit is designed to accurately comprehend user instructions and ensure effective control over the editing process. Specifically, we enhance the fine-grained visual perception capabilities of the VLM by introducing additional region tokens. Relying solely on the output of the LLM to guide the diffusion model may lead to suboptimal editing results. Therefore, we propose a Time-Aware Target Injection module and a Hybrid Visual Cross Attention module. The former dynamically adjusts the guidance strength at various denoising stages by integrating timestep embeddings with the text embeddings. The latter enhances visual details for image editing, thereby preserving semantic consistency between the edited result and the source image. By combining the VLM enhanced with fine-grained region tokens and the time-dependent diffusion model, FireEdit demonstrates significant advantages in comprehending editing instructions and maintaining high semantic consistency. Extensive experiments indicate that our approach surpasses the state-of-the-art instruction-based image editing methods. Our project is available at https://zjgans.github.io/fireedit.github.io.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning
Nov 18, 2024



In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of ``slow thinking" into multimodal large language models (MLLMs). Contrary to existing methods that rely on direct or fast thinking, our key idea is to construct long chains of thought (CoT) consisting of atomic actions in a step-by-step manner, guiding MLLMs to perform complex reasoning. To this end, we design a novel AtomThink framework composed of three key modules: (i) a CoT annotation engine that automatically generates high-quality CoT annotations to address the lack of high-quality visual mathematical data; (ii) an atomic step fine-tuning strategy that jointly optimizes an MLLM and a policy reward model (PRM) for step-wise reasoning; and (iii) four different search strategies that can be applied with the PRM to complete reasoning. Additionally, we propose AtomMATH, a large-scale multimodal dataset of long CoTs, and an atomic capability evaluation metric for mathematical tasks. Extensive experimental results show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving approximately 50\% relative accuracy gains on MathVista and 120\% on MathVerse. To support the advancement of multimodal slow-thinking models, we will make our code and dataset publicly available on https://github.com/Quinn777/AtomThink.
Learning Interaction-aware 3D Gaussian Splatting for One-shot Hand Avatars
Oct 11, 2024



In this paper, we propose to create animatable avatars for interacting hands with 3D Gaussian Splatting (GS) and single-image inputs. Existing GS-based methods designed for single subjects often yield unsatisfactory results due to limited input views, various hand poses, and occlusions. To address these challenges, we introduce a novel two-stage interaction-aware GS framework that exploits cross-subject hand priors and refines 3D Gaussians in interacting areas. Particularly, to handle hand variations, we disentangle the 3D presentation of hands into optimization-based identity maps and learning-based latent geometric features and neural texture maps. Learning-based features are captured by trained networks to provide reliable priors for poses, shapes, and textures, while optimization-based identity maps enable efficient one-shot fitting of out-of-distribution hands. Furthermore, we devise an interaction-aware attention module and a self-adaptive Gaussian refinement module. These modules enhance image rendering quality in areas with intra- and inter-hand interactions, overcoming the limitations of existing GS-based methods. Our proposed method is validated via extensive experiments on the large-scale InterHand2.6M dataset, and it significantly improves the state-of-the-art performance in image quality. Project Page: \url{https://github.com/XuanHuang0/GuassianHand}.
GarmentAligner: Text-to-Garment Generation via Retrieval-augmented Multi-level Corrections
Aug 23, 2024



General text-to-image models bring revolutionary innovation to the fields of arts, design, and media. However, when applied to garment generation, even the state-of-the-art text-to-image models suffer from fine-grained semantic misalignment, particularly concerning the quantity, position, and interrelations of garment components. Addressing this, we propose GarmentAligner, a text-to-garment diffusion model trained with retrieval-augmented multi-level corrections. To achieve semantic alignment at the component level, we introduce an automatic component extraction pipeline to obtain spatial and quantitative information of garment components from corresponding images and captions. Subsequently, to exploit component relationships within the garment images, we construct retrieval subsets for each garment by retrieval augmentation based on component-level similarity ranking and conduct contrastive learning to enhance the model perception of components from positive and negative samples. To further enhance the alignment of components across semantic, spatial, and quantitative granularities, we propose the utilization of multi-level correction losses that leverage detailed component information. The experimental findings demonstrate that GarmentAligner achieves superior fidelity and fine-grained semantic alignment when compared to existing competitors.
AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation
Jun 03, 2024As cutting-edge Text-to-Image (T2I) generation models already excel at producing remarkable single images, an even more challenging task, i.e., multi-turn interactive image generation begins to attract the attention of related research communities. This task requires models to interact with users over multiple turns to generate a coherent sequence of images. However, since users may switch subjects frequently, current efforts struggle to maintain subject consistency while generating diverse images. To address this issue, we introduce a training-free multi-agent framework called AutoStudio. AutoStudio employs three agents based on large language models (LLMs) to handle interactions, along with a stable diffusion (SD) based agent for generating high-quality images. Specifically, AutoStudio consists of (i) a subject manager to interpret interaction dialogues and manage the context of each subject, (ii) a layout generator to generate fine-grained bounding boxes to control subject locations, (iii) a supervisor to provide suggestions for layout refinements, and (iv) a drawer to complete image generation. Furthermore, we introduce a Parallel-UNet to replace the original UNet in the drawer, which employs two parallel cross-attention modules for exploiting subject-aware features. We also introduce a subject-initialized generation method to better preserve small subjects. Our AutoStudio hereby can generate a sequence of multi-subject images interactively and consistently. Extensive experiments on the public CMIGBench benchmark and human evaluations show that AutoStudio maintains multi-subject consistency across multiple turns well, and it also raises the state-of-the-art performance by 13.65% in average Frechet Inception Distance and 2.83% in average character-character similarity.