 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocSelect: Target Speaker Localization with an Auditory Selective Hearing Mechanism
Oct 17, 2023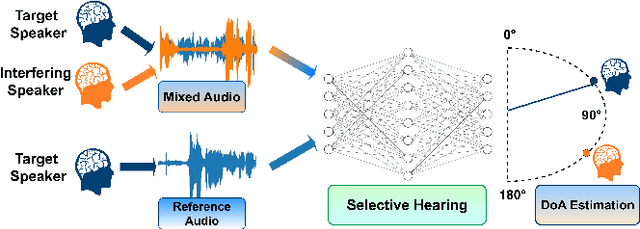
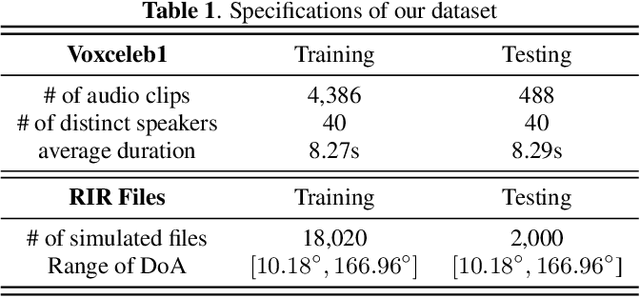
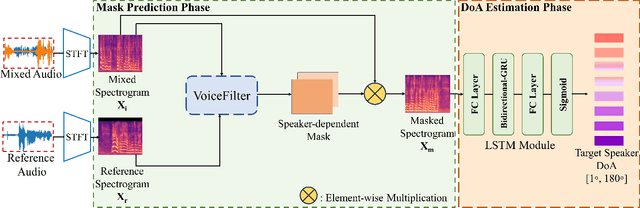
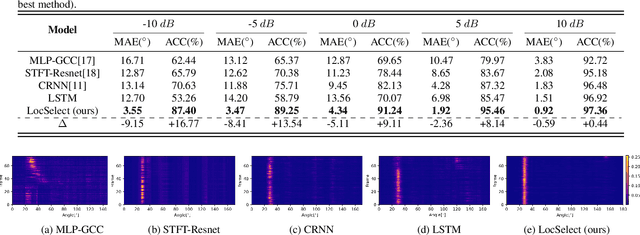
The prevailing noise-resistant and reverberation-resistant localization algorithms primarily emphasize separating and providing directional output for each speaker in multi-speaker scenarios, without association with the identity of speakers. In this paper, we present a target speaker localization algorithm with a selective hearing mechanism. Given a reference speech of the target speaker, we first produce a speaker-dependent spectrogram mask to eliminate interfering speakers' speech. Subsequently, a Long short-term memory (LSTM) network is employed to extract the target speaker's location from the filtered spectrogram. Experiments validate the superiority of our proposed method over the existing algorithms for different scale invariant signal-to-noise ratios (SNR) conditions. Specifically, at SNR = -10 dB, our proposed network LocSelect achieves a mean absolute error (MAE) of 3.55 and an accuracy (ACC) of 87.40%.
UNO-DST: Leveraging Unlabelled Data in Zero-Shot Dialogue State Tracking
Oct 16, 2023Previous zero-shot dialogue state tracking (DST) methods only apply transfer learning, but ignore unlabelled data in the target domain. We transform zero-shot DST into few-shot DST by utilising such unlabelled data via joint and self-training methods. Our method incorporates auxiliary tasks that generate slot types as inverse prompts for main tasks, creating slot values during joint training. Cycle consistency between these two tasks enables the generation and selection of quality samples in unknown target domains for subsequent fine-tuning. This approach also facilitates automatic label creation, thereby optimizing the training and fine-tuning of DST models. We demonstrate this method's effectiveness on large language models in zero-shot scenarios, improving average joint goal accuracy by $8\%$ across all domains in MultiWOZ.
xDial-Eval: A Multilingual Open-Domain Dialogue Evaluation Benchmark
Oct 13, 2023



Recent advancements in reference-free learned metrics for open-domain dialogue evaluation have been driven by the progress in pre-trained language models and the availability of dialogue data with high-quality human annotations. However, current studies predominantly concentrate on English dialogues, and the generalization of these metrics to other languages has not been fully examined. This is largely due to the absence of a multilingual dialogue evaluation benchmark. To address the issue, we introduce xDial-Eval, built on top of open-source English dialogue evaluation datasets. xDial-Eval includes 12 turn-level and 6 dialogue-level English datasets, comprising 14930 annotated turns and 8691 annotated dialogues respectively. The English dialogue data are extended to nine other languages with commercial machine translation systems. On xDial-Eval, we conduct comprehensive analyses of previous BERT-based metrics and the recently-emerged large language models. Lastly, we establish strong self-supervised and multilingual baselines. In terms of average Pearson correlations over all datasets and languages, the best baseline outperforms OpenAI's ChatGPT by absolute improvements of 6.5% and 4.6% at the turn and dialogue levels respectively, albeit with much fewer parameters. The data and code are publicly available at https://github.com/e0397123/xDial-Eval.
Disentangling Voice and Content with Self-Supervision for Speaker Recognition
Oct 02, 2023For speaker recognition, it is difficult to extract an accurate speaker representation from speech because of its mixture of speaker traits and content. This paper proposes a disentanglement framework that simultaneously models speaker traits and content variability in speech. It is realized with the use of three Gaussian inference layers, each consisting of a learnable transition model that extracts distinct speech components. Notably, a strengthened transition model is specifically designed to model complex speech dynamics. We also propose a self-supervision method to dynamically disentangle content without the use of labels other than speaker identities. The efficacy of the proposed framework is validated via experiments conducted on the VoxCeleb and SITW datasets with 9.56% and 8.24% average reductions in EER and minDCF, respectively. Since neither additional model training nor data is specifically needed, it is easily applicable in practical use.
Leveraging In-the-Wild Data for Effective Self-Supervised Pretraining in Speaker Recognition
Sep 27, 2023Current speaker recognition systems primarily rely on supervised approaches, constrained by the scale of labeled datasets. To boost the system performance, researchers leverage large pretrained models such as WavLM to transfer learned high-level features to the downstream speaker recognition task. However, this approach introduces extra parameters as the pretrained model remains in the inference stage. Another group of researchers directly apply self-supervised methods such as DINO to speaker embedding learning, yet they have not explored its potential on large-scale in-the-wild datasets. In this paper, we present the effectiveness of DINO training on the large-scale WenetSpeech dataset and its transferability in enhancing the supervised system performance on the CNCeleb dataset. Additionally, we introduce a confidence-based data filtering algorithm to remove unreliable data from the pretraining dataset, leading to better performance with less training data. The associated pretrained models, confidence files, pretraining and finetuning scripts will be made available in the Wespeaker toolkit.
FluentEditor: Text-based Speech Editing by Considering Acoustic and Prosody Consistency
Sep 22, 2023



Text-based speech editing (TSE) techniques are designed to enable users to edit the output audio by modifying the input text transcript instead of the audio itself. Despite much progress in neural network-based TSE techniques, the current techniques have focused on reducing the difference between the generated speech segment and the reference target in the editing region, ignoring its local and global fluency in the context and original utterance. To maintain the speech fluency, we propose a fluency speech editing model, termed \textit{FluentEditor}, by considering fluency-aware training criterion in the TSE training. Specifically, the \textit{acoustic consistency constraint} aims to smooth the transition between the edited region and its neighboring acoustic segments consistent with the ground truth, while the \textit{prosody consistency constraint} seeks to ensure that the prosody attributes within the edited regions remain consistent with the overall style of the original utterance. The subjective and objective experimental results on VCTK demonstrate that our \textit{FluentEditor} outperforms all advanced baselines in terms of naturalness and fluency. The audio samples and code are available at \url{https://github.com/Ai-S2-Lab/FluentEditor}.
AceGPT, Localizing Large Language Models in Arabic
Sep 22, 2023



This paper explores the imperative need and methodology for developing a localized Large Language Model (LLM) tailored for Arabic, a language with unique cultural characteristics that are not adequately addressed by current mainstream models like ChatGPT. Key concerns additionally arise when considering cultural sensitivity and local values. To this end, the paper outlines a packaged solution, including further pre-training with Arabic texts, supervised fine-tuning (SFT) using native Arabic instructions and GPT-4 responses in Arabic, and reinforcement learning with AI feedback (RLAIF) using a reward model that is sensitive to local culture and values. The objective is to train culturally aware and value-aligned Arabic LLMs that can serve the diverse application-specific needs of Arabic-speaking communities. Extensive evaluations demonstrated that the resulting LLM called `AceGPT' is the SOTA open Arabic LLM in various benchmarks, including instruction-following benchmark (i.e., Arabic Vicuna-80 and Arabic AlpacaEval), knowledge benchmark (i.e., Arabic MMLU and EXAMs), as well as the newly-proposed Arabic cultural \& value alignment benchmark. Notably, AceGPT outperforms ChatGPT in the popular Vicuna-80 benchmark when evaluated with GPT-4, despite the benchmark's limited scale. % Natural Language Understanding (NLU) benchmark (i.e., ALUE) Codes, data, and models are in https://github.com/FreedomIntelligence/AceGPT.
Emotion-Aware Prosodic Phrasing for Expressive Text-to-Speech
Sep 21, 2023Prosodic phrasing is crucial to the naturalness and intelligibility of end-to-end Text-to-Speech (TTS). There exist both linguistic and emotional prosody in natural speech. As the study of prosodic phrasing has been linguistically motivated, prosodic phrasing for expressive emotion rendering has not been well studied. In this paper, we propose an emotion-aware prosodic phrasing model, termed \textit{EmoPP}, to mine the emotional cues of utterance accurately and predict appropriate phrase breaks. We first conduct objective observations on the ESD dataset to validate the strong correlation between emotion and prosodic phrasing. Then the objective and subjective evaluations show that the EmoPP outperforms all baselines and achieves remarkable performance in terms of emotion expressiveness. The audio samples and the code are available at \url{https://github.com/AI-S2-Lab/EmoPP}.
USED: Universal Speaker Extraction and Diarization
Sep 19, 2023



Speaker extraction and diarization are two crucial enabling techniques for speech applications. Speaker extraction aims to extract a target speaker's voice from a multi-talk mixture, while speaker diarization demarcates speech segments by speaker, identifying `who spoke when'. The previous studies have typically treated the two tasks independently. However, the two tasks share a similar objective, that is to disentangle the speakers in the spectral domain for the former but in the temporal domain for the latter. It is logical to believe that the speaker turns obtained from speaker diarization can benefit speaker extraction, while the extracted speech offers more accurate speaker turns than the mixture speech. In this paper, we propose a unified framework called Universal Speaker Extraction and Diarization (USED). We extend the existing speaker extraction model to simultaneously extract the waveforms of all speakers. We also employ a scenario-aware differentiated loss function to address the problem of sparsely overlapped speech in real-world conversations. We show that the USED model significantly outperforms the baselines for both speaker extraction and diarization tasks, in both highly overlapped and sparsely overlapped scenarios. Audio samples are available at https://ajyy.github.io/demo/USED/.
Spiking-LEAF: A Learnable Auditory front-end for Spiking Neural Networks
Sep 18, 2023



Brain-inspired spiking neural networks (SNNs) have demonstrated great potential for temporal signal processing. However, their performance in speech processing remains limited due to the lack of an effective auditory front-end. To address this limitation, we introduce Spiking-LEAF, a learnable auditory front-end meticulously designed for SNN-based speech processing. Spiking-LEAF combines a learnable filter bank with a novel two-compartment spiking neuron model called IHC-LIF. The IHC-LIF neurons draw inspiration from the structure of inner hair cells (IHC) and they leverage segregated dendritic and somatic compartments to effectively capture multi-scale temporal dynamics of speech signals. Additionally, the IHC-LIF neurons incorporate the lateral feedback mechanism along with spike regularization loss to enhance spike encoding efficiency. On keyword spotting and speaker identification tasks, the proposed Spiking-LEAF outperforms both SOTA spiking auditory front-ends and conventional real-valued acoustic features in terms of classification accuracy, noise robustness, and encoding efficiency.