 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuraMark: Duration-Embedded Watermarking in LLM-based TTS
Jun 13, 2026Large language model (LLM)-based text-to-speech (TTS) models have achieved remarkable voice cloning capabilities, raising concerns about potential deepfake misuse. Speech watermarking mitigates this by embedding traceable information into generated speech. Mainstream watermarking methods operate at the signal level (waveform or spectrogram), rendering the watermark vulnerable to generative attacks (e.g., neural codec and vocoder). To address this, we propose DuraMark, a robust information-level watermarking framework. It utilizes syllable duration editing to achieve watermark embedding. Specifically, DuraMark integrates a duration-controllable LLM-based TTS model to edit syllable durations during synthesis, coupled with a duration extractor to extract these durations for detection. Experiments demonstrate DuraMark's superior robustness against generative attacks, significantly outperforming signal-level baselines. Audio samples are available at https://muzw.github.io/duramark_demo/.
SpeakerCard-1M: An Evidence-Grounded Speaker Card Corpus for In-the-Wild Speaker Verification
Jun 03, 2026Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, and provide limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker-centric resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the "-1M" suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach: ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7K Speaker Card records over 10.2K speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training increases VoxCeleb1-O EER by 0.31% absolute over the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify under two-way forced choice, compared with 88.66% reached by our dual encoder.
RADAR Challenge 2026: Robust Audio Deepfake Recognition under Media Transformations
May 10, 2026RADAR Challenge 2026 is an APSIPA Grand Challenge on Robust Audio Deepfake Recognition under Media Transformations, designed to simulate realistic media conditions in real-world audio distribution pipelines, including compression, resampling, noise, and reverberation. It consists of two phases: an English development phase with labeled data for analysis and paper writing, and a multilingual evaluation phase containing more than 100,000 utterances in English, Singapore English, Mandarin Chinese, Taiwanese Mandarin, Japanese, and Vietnamese. Systems are evaluated using equal error rate (EER) for binary real/fake classification. This paper describes the challenge task, the construction of the data set, the evaluation protocol, and the overall results. During the challenge, 33 teams submitted to the development phase and 22 teams submitted to the final evaluation phase. The reported results highlight the remaining challenges of robust audio deepfake detection under multilingual and media-transformed conditions.
UNet-Based Fusion and Exponential Moving Average Adaptation for Noise-Robust Speaker Recognition
Apr 28, 2026The joint training of speech enhancement and speaker embedding networks for speaker recognition is widely adopted under noisy acoustic environments. While effective, this paradigm often fails to leverage the generalization and robustness benefits inherent in large-scale speech enhancement pre-training. Moreover, maintaining the speaker information in the denoised speech is not an explicit objective of the speech enhancement process. To address these limitations, we proposed a scalable \textbf{U}Net-based \textbf{F}usion framework (UF-EMA) that considers the noisy and enhanced speech as a multi-channel input, thereby enabling the speaker encoder to exploit speaker information effectively. In addition, an \textbf{E}xponential \textbf{M}oving \textbf{A}verage strategy is applied to a speaker encoder pre-trained on clean speech to mitigate overfitting and facilitate a smooth transition from clean to noisy conditions. Experimental results on multiple noise-contaminated test sets showcase the superiority of the proposed approach.
ProSDD: Learning Prosodic Representations for Speech Deepfake Detection against Expressive and Emotional Attacks
Apr 14, 2026Speech deepfake detection (SDD) systems perform well on standard benchmarks datasets but often fail to generalize to expressive and emotional spoofing attacks. Many methods rely on spoof-heavy training data, learning dataset-specific artifacts rather than transferable cues of natural speech. In contrast, humans internalize variability in real speech and detect fakes as deviations from it. We introduce ProSDD, a two-stage framework that enriches model embeddings through supervised masked prediction of speaker-conditioned prosodic variation based on pitch, voice activity, and energy. Stage I learns prosodic variability from real speech, and Stage II jointly optimizes this objective with spoof classification. ProSDD consistently outperforms baselines under both ASVspoof 2019 and 2024 training, reducing ASVspoof 2024 EER from 25.43% to 16.14% (2019-trained) and from 39.62% to 7.38% (2024-trained), while achieving 50% relative reductions on EmoFake and EmoSpoof-TTS.
Privacy-Preserving End-to-End Full-Duplex Speech Dialogue Models
Mar 09, 2026End-to-end full-duplex speech models feed user audio through an always-on LLM backbone, yet the speaker privacy implications of their hidden representations remain unexamined. Following the VoicePrivacy 2024 protocol with a lazy-informed attacker, we show that the hidden states of SALM-Duplex and Moshi leak substantial speaker identity across all transformer layers. Layer-wise and turn-wise analyses reveal that leakage persists across all layers, with SALM-Duplex showing stronger leakage in early layers while Moshi leaks uniformly, and that Linkability rises sharply within the first few turns. We propose two streaming anonymization setups using Stream-Voice-Anon: a waveform-level front-end (Anon-W2W) and a feature-domain replacement (Anon-W2F). Anon-W2F raises EER by over 3.5x relative to the discrete encoder baseline (11.2% to 41.0%), approaching the 50% random-chance ceiling, while Anon-W2W retains 78-93% of baseline sBERT across setups with sub-second response latency (FRL under 0.8 s).
Stream-Voice-Anon: Enhancing Utility of Real-Time Speaker Anonymization via Neural Audio Codec and Language Models
Jan 20, 2026Protecting speaker identity is crucial for online voice applications, yet streaming speaker anonymization (SA) remains underexplored. Recent research has demonstrated that neural audio codec (NAC) provides superior speaker feature disentanglement and linguistic fidelity. NAC can also be used with causal language models (LM) to enhance linguistic fidelity and prompt control for streaming tasks. However, existing NAC-based online LM systems are designed for voice conversion (VC) rather than anonymization, lacking the techniques required for privacy protection. Building on these advances, we present Stream-Voice-Anon, which adapts modern causal LM-based NAC architectures specifically for streaming SA by integrating anonymization techniques. Our anonymization approach incorporates pseudo-speaker representation sampling, a speaker embedding mixing and diverse prompt selection strategies for LM conditioning that leverage the disentanglement properties of quantized content codes to prevent speaker information leakage. Additionally, we compare dynamic and fixed delay configurations to explore latency-privacy trade-offs in real-time scenarios. Under the VoicePrivacy 2024 Challenge protocol, Stream-Voice-Anon achieves substantial improvements in intelligibility (up to 46% relative WER reduction) and emotion preservation (up to 28% UAR relative) compared to the previous state-of-the-art streaming method DarkStream while maintaining comparable latency (180ms vs 200ms) and privacy protection against lazy-informed attackers, though showing 15% relative degradation against semi-informed attackers.
ASVspoof 5: Evaluation of Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Jan 07, 2026ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake detection solutions. A significant change from previous challenge editions is a new crowdsourced database collected from a substantially greater number of speakers under diverse recording conditions, and a mix of cutting-edge and legacy generative speech technology. With the new database described elsewhere, we provide in this paper an overview of the ASVspoof 5 challenge results for the submissions of 53 participating teams. While many solutions perform well, performance degrades under adversarial attacks and the application of neural encoding/compression schemes. Together with a review of post-challenge results, we also report a study of calibration in addition to other principal challenges and outline a road-map for the future of ASVspoof.
IDMap: A Pseudo-Speaker Generator Framework Based on Speaker Identity Index to Vector Mapping
Nov 09, 2025Facilitated by the speech generation framework that disentangles speech into content, speaker, and prosody, voice anonymization is accomplished by substituting the original speaker embedding vector with that of a pseudo-speaker. In this framework, the pseudo-speaker generation forms a fundamental challenge. Current pseudo-speaker generation methods demonstrate limitations in the uniqueness of pseudo-speakers, consequently restricting their effectiveness in voice privacy protection. Besides, existing model-based methods suffer from heavy computation costs. Especially, in the large-scale scenario where a huge number of pseudo-speakers are generated, the limitations of uniqueness and computational inefficiency become more significant. To this end, this paper proposes a framework for pseudo-speaker generation, which establishes a mapping from speaker identity index to speaker vector in the feedforward architecture, termed IDMap. Specifically, the framework is specified into two models: IDMap-MLP and IDMap-Diff. Experiments were conducted on both small- and large-scale evaluation datasets. Small-scale evaluations on the LibriSpeech dataset validated the effectiveness of the proposed IDMap framework in enhancing the uniqueness of pseudo-speakers, thereby improving voice privacy protection, while at a reduced computational cost. Large-scale evaluations on the MLS and Common Voice datasets further justified the superiority of the IDMap framework regarding the stability of the voice privacy protection capability as the number of pseudo-speakers increased. Audio samples and open-source code can be found in https://github.com/VoicePrivacy/IDMap.
A Study of the Removability of Speaker-Adversarial Perturbations
Oct 10, 2025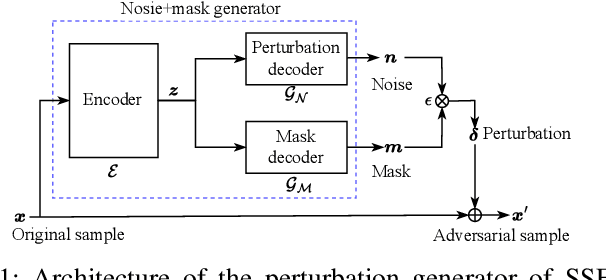
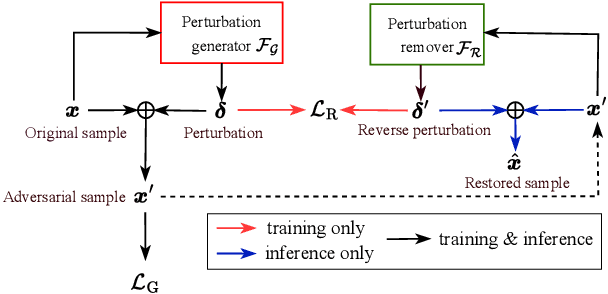
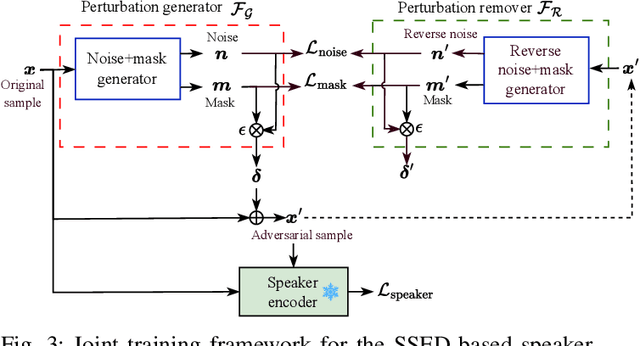

Recent advancements in adversarial attacks have demonstrated their effectiveness in misleading speaker recognition models, making wrong predictions about speaker identities. On the other hand, defense techniques against speaker-adversarial attacks focus on reducing the effects of speaker-adversarial perturbations on speaker attribute extraction. These techniques do not seek to fully remove the perturbations and restore the original speech. To this end, this paper studies the removability of speaker-adversarial perturbations. Specifically, the investigation is conducted assuming various degrees of awareness of the perturbation generator across three scenarios: ignorant, semi-informed, and well-informed. Besides, we consider both the optimization-based and feedforward perturbation generation methods. Experiments conducted on the LibriSpeech dataset demonstrated that: 1) in the ignorant scenario, speaker-adversarial perturbations cannot be eliminated, although their impact on speaker attribute extraction is reduced, 2) in the semi-informed scenario, the speaker-adversarial perturbations cannot be fully removed, while those generated by the feedforward model can be considerably reduced, and 3) in the well-informed scenario, speaker-adversarial perturbations are nearly eliminated, allowing for the restoration of the original speech. Audio samples can be found in https://voiceprivacy.github.io/Perturbation-Generation-Removal/.