 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Testbeds: An Interaction-Centric Agent Simulation Platform for Dynamic Recommender Systems
May 22, 2025Evaluating and iterating upon recommender systems is crucial, yet traditional A/B testing is resource-intensive, and offline methods struggle with dynamic user-platform interactions. While agent-based simulation is promising, existing platforms often lack a mechanism for user actions to dynamically reshape the environment. To bridge this gap, we introduce RecInter, a novel agent-based simulation platform for recommender systems featuring a robust interaction mechanism. In RecInter platform, simulated user actions (e.g., likes, reviews, purchases) dynamically update item attributes in real-time, and introduced Merchant Agents can reply, fostering a more realistic and evolving ecosystem. High-fidelity simulation is ensured through Multidimensional User Profiling module, Advanced Agent Architecture, and LLM fine-tuned on Chain-of-Thought (CoT) enriched interaction data. Our platform achieves significantly improved simulation credibility and successfully replicates emergent phenomena like Brand Loyalty and the Matthew Effect. Experiments demonstrate that this interaction mechanism is pivotal for simulating realistic system evolution, establishing our platform as a credible testbed for recommender systems research.
Semantic Convergence: Harmonizing Recommender Systems via Two-Stage Alignment and Behavioral Semantic Tokenization
Dec 18, 2024



Large language models (LLMs), endowed with exceptional reasoning capabilities, are adept at discerning profound user interests from historical behaviors, thereby presenting a promising avenue for the advancement of recommendation systems. However, a notable discrepancy persists between the sparse collaborative semantics typically found in recommendation systems and the dense token representations within LLMs. In our study, we propose a novel framework that harmoniously merges traditional recommendation models with the prowess of LLMs. We initiate this integration by transforming ItemIDs into sequences that align semantically with the LLMs space, through the proposed Alignment Tokenization module. Additionally, we design a series of specialized supervised learning tasks aimed at aligning collaborative signals with the subtleties of natural language semantics. To ensure practical applicability, we optimize online inference by pre-caching the top-K results for each user, reducing latency and improving effciency. Extensive experimental evidence indicates that our model markedly improves recall metrics and displays remarkable scalability of recommendation systems.
Adaptive Super Resolution For One-Shot Talking-Head Generation
Mar 23, 2024The one-shot talking-head generation learns to synthesize a talking-head video with one source portrait image under the driving of same or different identity video. Usually these methods require plane-based pixel transformations via Jacobin matrices or facial image warps for novel poses generation. The constraints of using a single image source and pixel displacements often compromise the clarity of the synthesized images. Some methods try to improve the quality of synthesized videos by introducing additional super-resolution modules, but this will undoubtedly increase computational consumption and destroy the original data distribution. In this work, we propose an adaptive high-quality talking-head video generation method, which synthesizes high-resolution video without additional pre-trained modules. Specifically, inspired by existing super-resolution methods, we down-sample the one-shot source image, and then adaptively reconstruct high-frequency details via an encoder-decoder module, resulting in enhanced video clarity. Our method consistently improves the quality of generated videos through a straightforward yet effective strategy, substantiated by quantitative and qualitative evaluations. The code and demo video are available on: \url{https://github.com/Songluchuan/AdaSR-TalkingHead/}.
Emotional Listener Portrait: Neural Listener Head Generation with Emotion
Oct 08, 2023Listener head generation centers on generating non-verbal behaviors (e.g., smile) of a listener in reference to the information delivered by a speaker. A significant challenge when generating such responses is the non-deterministic nature of fine-grained facial expressions during a conversation, which varies depending on the emotions and attitudes of both the speaker and the listener. To tackle this problem, we propose the Emotional Listener Portrait (ELP), which treats each fine-grained facial motion as a composition of several discrete motion-codewords and explicitly models the probability distribution of the motions under different emotion in conversation. Benefiting from the ``explicit'' and ``discrete'' design, our ELP model can not only automatically generate natural and diverse responses toward a given speaker via sampling from the learned distribution but also generate controllable responses with a predetermined attitude. Under several quantitative metrics, our ELP exhibits significant improvements compared to previous methods.
Counterfactual Intervention Feature Transfer for Visible-Infrared Person Re-identification
Aug 01, 2022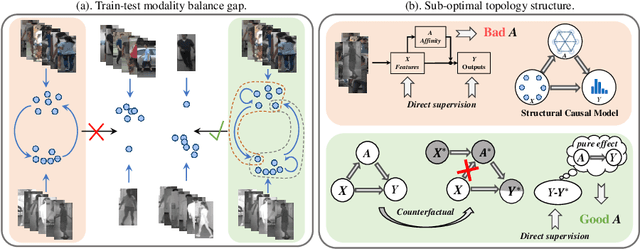
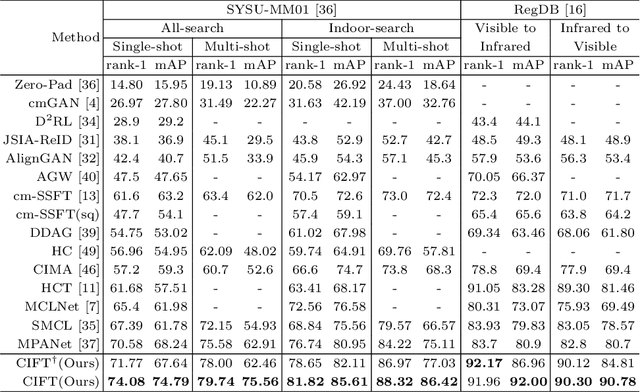
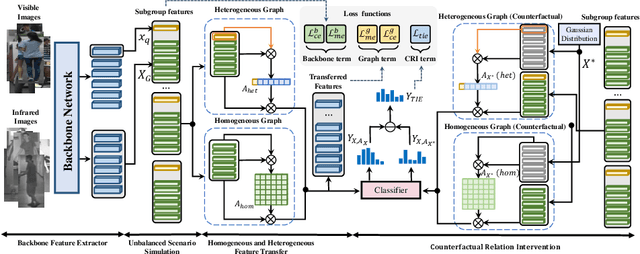
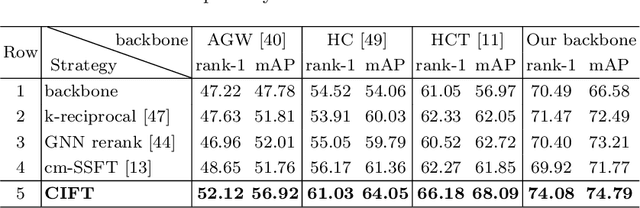
Graph-based models have achieved great success in person re-identification tasks recently, which compute the graph topology structure (affinities) among different people first and then pass the information across them to achieve stronger features. But we find existing graph-based methods in the visible-infrared person re-identification task (VI-ReID) suffer from bad generalization because of two issues: 1) train-test modality balance gap, which is a property of VI-ReID task. The number of two modalities data are balanced in the training stage, but extremely unbalanced in inference, causing the low generalization of graph-based VI-ReID methods. 2) sub-optimal topology structure caused by the end-to-end learning manner to the graph module. We analyze that the well-trained input features weaken the learning of graph topology, making it not generalized enough during the inference process. In this paper, we propose a Counterfactual Intervention Feature Transfer (CIFT) method to tackle these problems. Specifically, a Homogeneous and Heterogeneous Feature Transfer (H2FT) is designed to reduce the train-test modality balance gap by two independent types of well-designed graph modules and an unbalanced scenario simulation. Besides, a Counterfactual Relation Intervention (CRI) is proposed to utilize the counterfactual intervention and causal effect tools to highlight the role of topology structure in the whole training process, which makes the graph topology structure more reliable. Extensive experiments on standard VI-ReID benchmarks demonstrate that CIFT outperforms the state-of-the-art methods under various settings.
ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis
Mar 09, 2021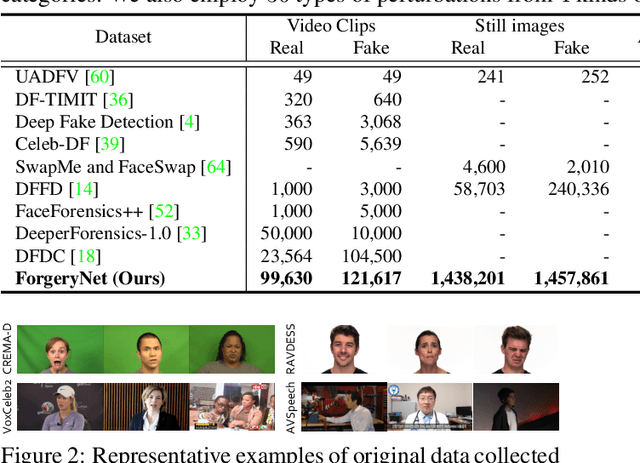
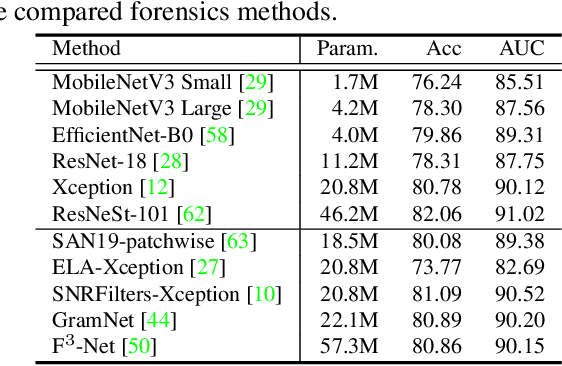

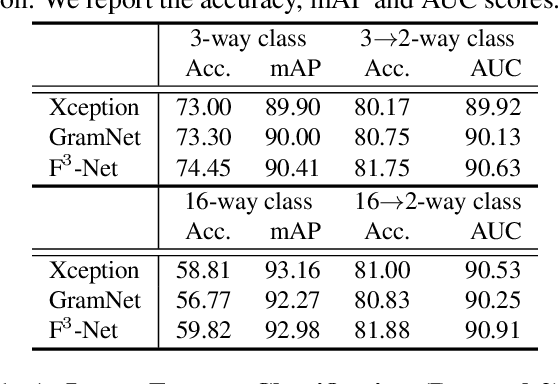
The rapid progress of photorealistic synthesis techniques has reached at a critical point where the boundary between real and manipulated images starts to blur. Thus, benchmarking and advancing digital forgery analysis have become a pressing issue. However, existing face forgery datasets either have limited diversity or only support coarse-grained analysis. To counter this emerging threat, we construct the ForgeryNet dataset, an extremely large face forgery dataset with unified annotations in image- and video-level data across four tasks: 1) Image Forgery Classification, including two-way (real / fake), three-way (real / fake with identity-replaced forgery approaches / fake with identity-remained forgery approaches), and n-way (real and 15 respective forgery approaches) classification. 2) Spatial Forgery Localization, which segments the manipulated area of fake images compared to their corresponding source real images. 3) Video Forgery Classification, which re-defines the video-level forgery classification with manipulated frames in random positions. This task is important because attackers in real world are free to manipulate any target frame. and 4) Temporal Forgery Localization, to localize the temporal segments which are manipulated. ForgeryNet is by far the largest publicly available deep face forgery dataset in terms of data-scale (2.9 million images, 221,247 videos), manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations) and annotations (6.3 million classification labels, 2.9 million manipulated area annotations and 221,247 temporal forgery segment labels). We perform extensive benchmarking and studies of existing face forensics methods and obtain several valuable observations.
CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations
Aug 01, 2020
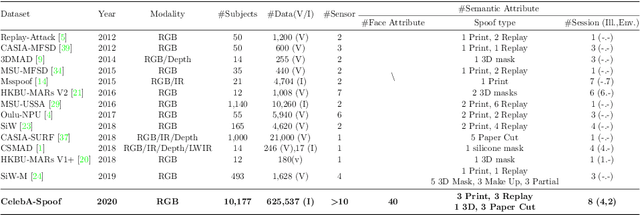

As facial interaction systems are prevalently deployed, security and reliability of these systems become a critical issue, with substantial research efforts devoted. Among them, face anti-spoofing emerges as an important area, whose objective is to identify whether a presented face is live or spoof. Though promising progress has been achieved, existing works still have difficulty in handling complex spoof attacks and generalizing to real-world scenarios. The main reason is that current face anti-spoofing datasets are limited in both quantity and diversity. To overcome these obstacles, we contribute a large-scale face anti-spoofing dataset, CelebA-Spoof, with the following appealing properties: 1) Quantity: CelebA-Spoof comprises of 625,537 pictures of 10,177 subjects, significantly larger than the existing datasets. 2) Diversity: The spoof images are captured from 8 scenes (2 environments * 4 illumination conditions) with more than 10 sensors. 3) Annotation Richness: CelebA-Spoof contains 10 spoof type annotations, as well as the 40 attribute annotations inherited from the original CelebA dataset. Equipped with CelebA-Spoof, we carefully benchmark existing methods in a unified multi-task framework, Auxiliary Information Embedding Network (AENet), and reveal several valuable observations.
Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues
Jul 18, 2020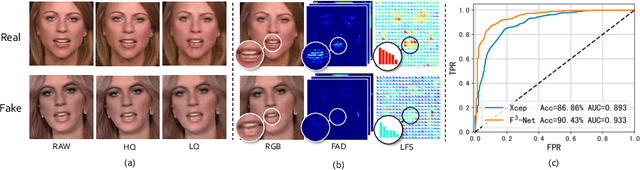
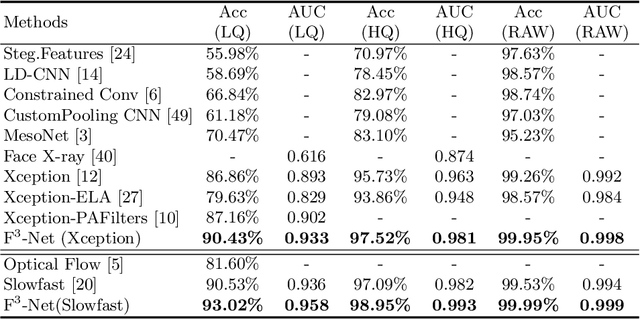
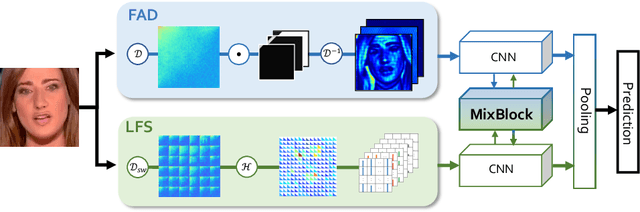
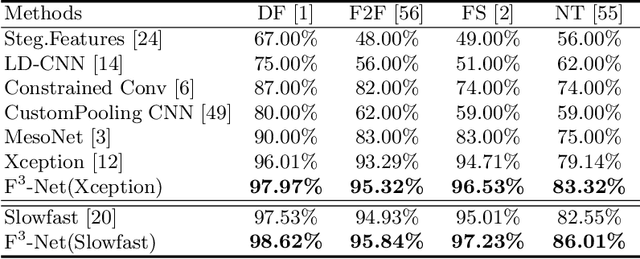
As realistic facial manipulation technologies have achieved remarkable progress, social concerns about potential malicious abuse of these technologies bring out an emerging research topic of face forgery detection. However, it is extremely challenging since recent advances are able to forge faces beyond the perception ability of human eyes, especially in compressed images and videos. We find that mining forgery patterns with the awareness of frequency could be a cure, as frequency provides a complementary viewpoint where either subtle forgery artifacts or compression errors could be well described. To introduce frequency into the face forgery detection, we propose a novel Frequency in Face Forgery Network (F3-Net), taking advantages of two different but complementary frequency-aware clues, 1) frequency-aware decomposed image components, and 2) local frequency statistics, to deeply mine the forgery patterns via our two-stream collaborative learning framework. We apply DCT as the applied frequency-domain transformation. Through comprehensive studies, we show that the proposed F3-Net significantly outperforms competing state-of-the-art methods on all compression qualities in the challenging FaceForensics++ dataset, especially wins a big lead upon low-quality media.
Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis
Oct 16, 2019
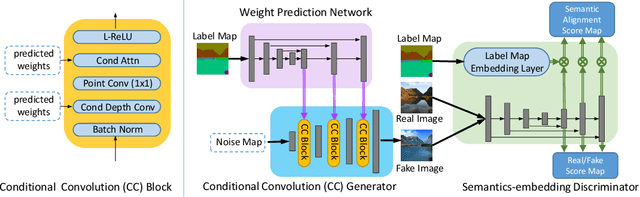
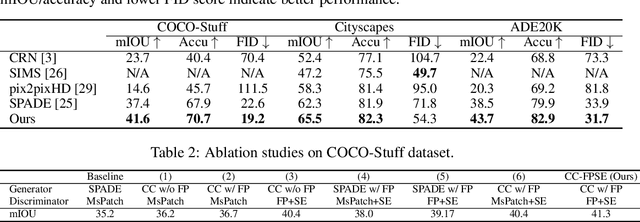

Semantic image synthesis aims at generating photorealistic images from semantic layouts. Previous approaches with conditional generative adversarial networks (GAN) show state-of-the-art performance on this task, which either feed the semantic label maps as inputs to the generator, or use them to modulate the activations in normalization layers via affine transformations. We argue that convolutional kernels in the generator should be aware of the distinct semantic labels at different locations when generating images. In order to better exploit the semantic layout for the image generator, we propose to predict convolutional kernels conditioned on the semantic label map to generate the intermediate feature maps from the noise maps and eventually generate the images. Moreover, we propose a feature pyramid semantics-embedding discriminator, which is more effective in enhancing fine details and semantic alignments between the generated images and the input semantic layouts than previous multi-scale discriminators. We achieve state-of-the-art results on both quantitative metrics and subjective evaluation on various semantic segmentation datasets, demonstrating the effectiveness of our approach.
A Large Scale Urban Surveillance Video Dataset for Multiple-Object Tracking and Behavior Analysis
Apr 26, 2019
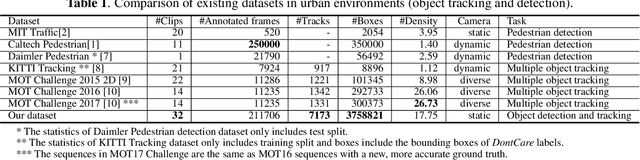

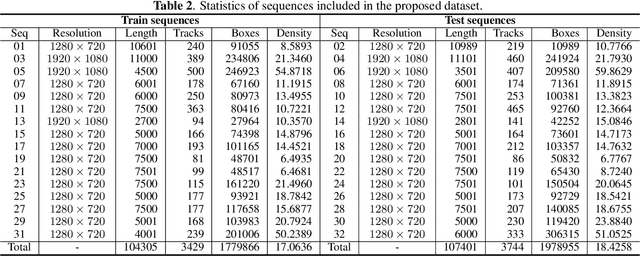
Multiple-object tracking and behavior analysis have been the essential parts of surveillance video analysis for public security and urban management. With billions of surveillance video captured all over the world, multiple-object tracking and behavior analysis by manual labor are cumbersome and cost expensive. Due to the rapid development of deep learning algorithms in recent years, automatic object tracking and behavior analysis put forward an urgent demand on a large scale well-annotated surveillance video dataset that can reflect the diverse, congested, and complicated scenarios in real applications. This paper introduces an urban surveillance video dataset (USVD) which is by far the largest and most comprehensive. The dataset consists of 16 scenes captured in 7 typical outdoor scenarios: street, crossroads, hospital entrance, school gate, park, pedestrian mall, and public square. Over 200k video frames are annotated carefully, resulting in more than 3:7 million object bounding boxes and about 7:1 thousand trajectories. We further use this dataset to evaluate the performance of typical algorithms for multiple-object tracking and anomaly behavior analysis and explore the robustness of these methods in urban congested scenarios.