 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDMM-LM: Bridging Facial Understanding and Animation via Language Models
Mar 14, 2026Text-guided human body animation has advanced rapidly, yet facial animation lags due to the scarcity of well-annotated, text-paired facial corpora. To close this gap, we leverage foundation generative models to synthesize a large, balanced corpus of facial behavior. We design prompts suite covering emotions and head motions, generate about 80 hours of facial videos with multiple generators, and fit per-frame 3D facial parameters, yielding large-scale (prompt and parameter) pairs for training. Building on this dataset, we probe language models for bidirectional competence over facial motion via two complementary tasks: (1) Motion2Language: given a sequence of 3D facial parameters, the model produces natural-language descriptions capturing content, style, and dynamics; and (2) Language2Motion: given a prompt, the model synthesizes the corresponding sequence of 3D facial parameters via quantized motion tokens for downstream animation. Extensive experiments show that in this setting language models can both interpret and synthesize facial motion with strong generalization. To best of our knowledge, this is the first work to cast facial-parameter modeling as a language problem, establishing a unified path for text-conditioned facial animation and motion understanding.
Talking Together: Synthesizing Co-Located 3D Conversations from Audio
Mar 09, 2026We tackle the challenging task of generating complete 3D facial animations for two interacting, co-located participants from a mixed audio stream. While existing methods often produce disembodied "talking heads" akin to a video conference call, our work is the first to explicitly model the dynamic 3D spatial relationship -- including relative position, orientation, and mutual gaze -- that is crucial for realistic in-person dialogues. Our system synthesizes the full performance of both individuals, including precise lip-sync, and uniquely allows their relative head poses to be controlled via textual descriptions. To achieve this, we propose a dual-stream architecture where each stream is responsible for one participant's output. We employ speaker's role embeddings and inter-speaker cross-attention mechanisms designed to disentangle the mixed audio and model the interaction. Furthermore, we introduce a novel eye gaze loss to promote natural, mutual eye contact. To power our data-hungry approach, we introduce a novel pipeline to curate a large-scale conversational dataset consisting of over 2 million dyadic pairs from in-the-wild videos. Our method generates fluid, controllable, and spatially aware dyadic animations suitable for immersive applications in VR and telepresence, significantly outperforming existing baselines in perceived realism and interaction coherence.
Classroom Final Exam: An Instructor-Tested Reasoning Benchmark
Feb 23, 2026We introduce \CFE{} (\textbf{C}lassroom \textbf{F}inal \textbf{E}xam), a multimodal benchmark for evaluating the reasoning capabilities of large language models across more than 20 STEM domains. \CFE{} is curated from repeatedly used, authentic university homework and exam problems, together with reference solutions provided by course instructors. \CFE{} presents a significant challenge even for frontier models: the newly released Gemini-3.1-pro-preview achieves an overall accuracy of 59.69\%, while the second-best model, Gemini-3-flash-preview, reaches 55.46\%, leaving considerable room for improvement. Beyond leaderboard results, we perform a diagnostic analysis by decomposing reference solutions into reasoning flows. We find that although frontier models can often answer intermediate sub-questions correctly, they struggle to reliably derive and maintain correct intermediate states throughout multi-step solutions. We further observe that model-generated solutions typically have more reasoning steps than those provided by the instructor, indicating suboptimal step efficiency and a higher risk of error accumulation. The data and code are available at https://github.com/Analogy-AI/CFE_Bench.
Omni-Judge: Can Omni-LLMs Serve as Human-Aligned Judges for Text-Conditioned Audio-Video Generation?
Feb 02, 2026State-of-the-art text-to-video generation models such as Sora 2 and Veo 3 can now produce high-fidelity videos with synchronized audio directly from a textual prompt, marking a new milestone in multi-modal generation. However, evaluating such tri-modal outputs remains an unsolved challenge. Human evaluation is reliable but costly and difficult to scale, while traditional automatic metrics, such as FVD, CLAP, and ViCLIP, focus on isolated modality pairs, struggle with complex prompts, and provide limited interpretability. Omni-modal large language models (omni-LLMs) present a promising alternative: they naturally process audio, video, and text, support rich reasoning, and offer interpretable chain-of-thought feedback. Driven by this, we introduce Omni-Judge, a study assessing whether omni-LLMs can serve as human-aligned judges for text-conditioned audio-video generation. Across nine perceptual and alignment metrics, Omni-Judge achieves correlation comparable to traditional metrics and excels on semantically demanding tasks such as audio-text alignment, video-text alignment, and audio-video-text coherence. It underperforms on high-FPS perceptual metrics, including video quality and audio-video synchronization, due to limited temporal resolution. Omni-Judge provides interpretable explanations that expose semantic or physical inconsistencies, enabling practical downstream uses such as feedback-based refinement. Our findings highlight both the potential and current limitations of omni-LLMs as unified evaluators for multi-modal generation.
When to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025



Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025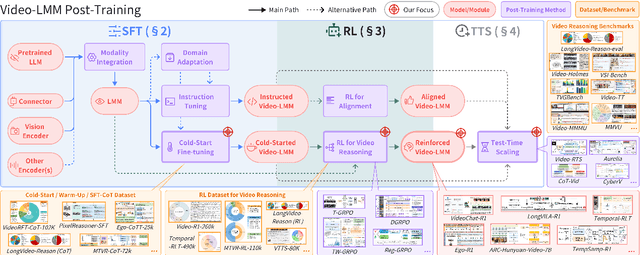
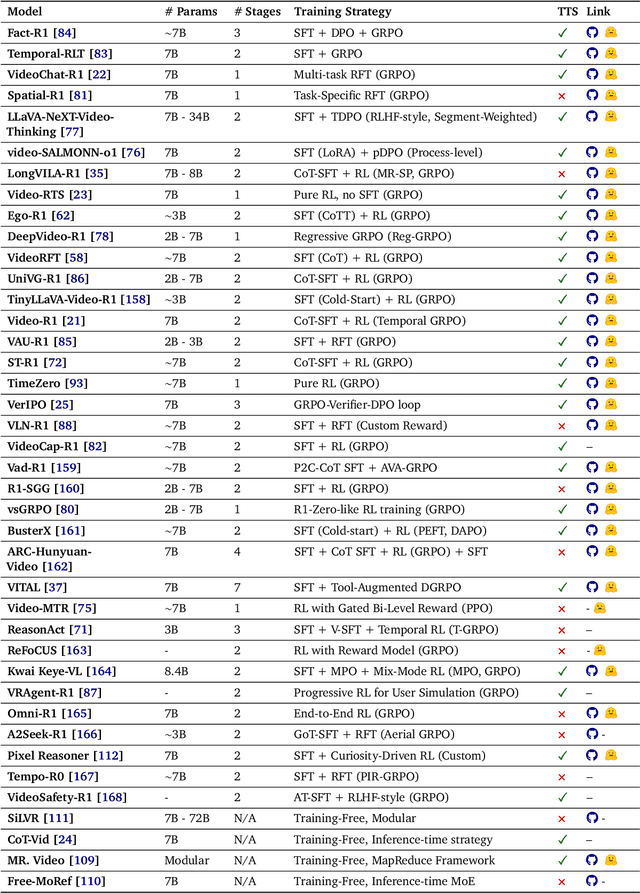
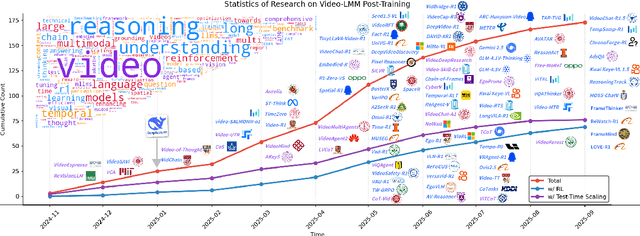
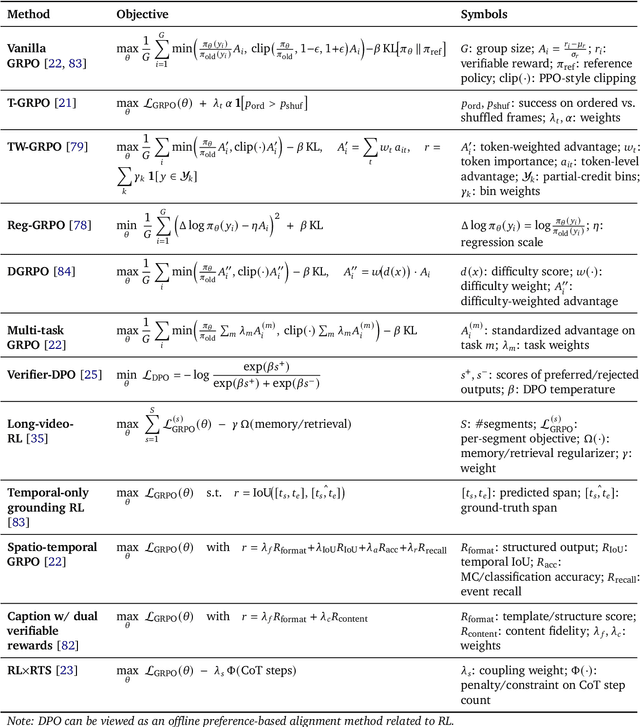
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
StreamME: Simplify 3D Gaussian Avatar within Live Stream
Jul 22, 2025We propose StreamME, a method focuses on fast 3D avatar reconstruction. The StreamME synchronously records and reconstructs a head avatar from live video streams without any pre-cached data, enabling seamless integration of the reconstructed appearance into downstream applications. This exceptionally fast training strategy, which we refer to as on-the-fly training, is central to our approach. Our method is built upon 3D Gaussian Splatting (3DGS), eliminating the reliance on MLPs in deformable 3DGS and relying solely on geometry, which significantly improves the adaptation speed to facial expression. To further ensure high efficiency in on-the-fly training, we introduced a simplification strategy based on primary points, which distributes the point clouds more sparsely across the facial surface, optimizing points number while maintaining rendering quality. Leveraging the on-the-fly training capabilities, our method protects the facial privacy and reduces communication bandwidth in VR system or online conference. Additionally, it can be directly applied to downstream application such as animation, toonify, and relighting. Please refer to our project page for more details: https://songluchuan.github.io/StreamME/.
MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
May 26, 2025Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/
Intentional Gesture: Deliver Your Intentions with Gestures for Speech
May 21, 2025When humans speak, gestures help convey communicative intentions, such as adding emphasis or describing concepts. However, current co-speech gesture generation methods rely solely on superficial linguistic cues (\textit{e.g.} speech audio or text transcripts), neglecting to understand and leverage the communicative intention that underpins human gestures. This results in outputs that are rhythmically synchronized with speech but are semantically shallow. To address this gap, we introduce \textbf{Intentional-Gesture}, a novel framework that casts gesture generation as an intention-reasoning task grounded in high-level communicative functions. % First, we curate the \textbf{InG} dataset by augmenting BEAT-2 with gesture-intention annotations (\textit{i.e.}, text sentences summarizing intentions), which are automatically annotated using large vision-language models. Next, we introduce the \textbf{Intentional Gesture Motion Tokenizer} to leverage these intention annotations. It injects high-level communicative functions (\textit{e.g.}, intentions) into tokenized motion representations to enable intention-aware gesture synthesis that are both temporally aligned and semantically meaningful, achieving new state-of-the-art performance on the BEAT-2 benchmark. Our framework offers a modular foundation for expressive gesture generation in digital humans and embodied AI. Project Page: https://andypinxinliu.github.io/Intentional-Gesture
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V