 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternalizing Agency from Reflective Experience
Mar 17, 2026Large language models are increasingly deployed as autonomous agents that must plan, act, and recover from mistakes through long-horizon interaction with environments that provide rich feedback. However, prevailing outcome-driven post-training methods (e.g., RL with verifiable rewards) primarily optimize final success signals, leaving rich environment feedback underutilized. Consequently, they often lead to distribution sharpening: the policy becomes better at reproducing a narrow set of already-successful behaviors, while failing to improve the feedback-grounded agency needed to expand problem-solving capacity (e.g., Pass@k) in long-horizon settings. To address this, we propose LEAFE (Learning Feedback-Grounded Agency from Reflective Experience), a framework that internalizes recovery agency from reflective experience. Specifically, during exploration, the agent summarizes environment feedback into actionable experience, backtracks to earlier decision points, and explores alternative branches with revised actions. We then distill these experience-guided corrections into the model through supervised fine-tuning, enabling the policy to recover more effectively in future interactions. Across a diverse set of interactive coding and agentic tasks under fixed interaction budgets, LEAFE consistently improves Pass@1 over the base model and achieves higher Pass@k than outcome-driven baselines (GRPO) and experience-based methods such as Early Experience, with gains of up to 14% on Pass@128.
Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues
Jul 18, 2020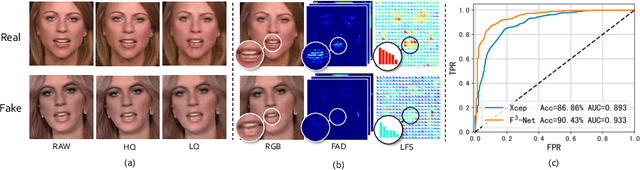
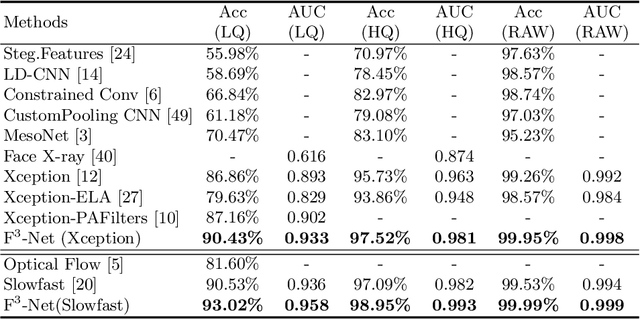
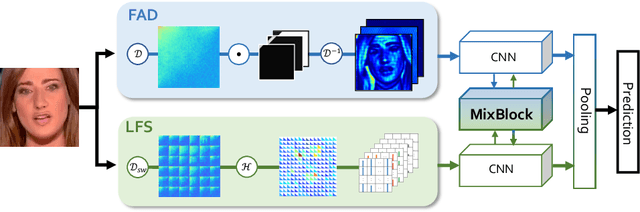
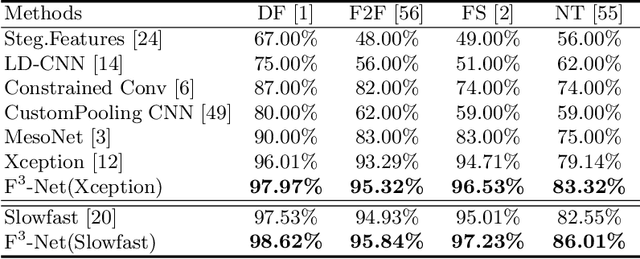
As realistic facial manipulation technologies have achieved remarkable progress, social concerns about potential malicious abuse of these technologies bring out an emerging research topic of face forgery detection. However, it is extremely challenging since recent advances are able to forge faces beyond the perception ability of human eyes, especially in compressed images and videos. We find that mining forgery patterns with the awareness of frequency could be a cure, as frequency provides a complementary viewpoint where either subtle forgery artifacts or compression errors could be well described. To introduce frequency into the face forgery detection, we propose a novel Frequency in Face Forgery Network (F3-Net), taking advantages of two different but complementary frequency-aware clues, 1) frequency-aware decomposed image components, and 2) local frequency statistics, to deeply mine the forgery patterns via our two-stream collaborative learning framework. We apply DCT as the applied frequency-domain transformation. Through comprehensive studies, we show that the proposed F3-Net significantly outperforms competing state-of-the-art methods on all compression qualities in the challenging FaceForensics++ dataset, especially wins a big lead upon low-quality media.