 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Intention Priors from Large-Scale Human Demonstrations for Robotic Manipulation
Apr 27, 2026Human videos contain rich manipulation priors, but using them for robot learning remains difficult because raw observations entangle scene understanding, human motion, and embodiment-specific action. We introduce MoT-HRA, a hierarchical vision-language-action framework that learns human-intention priors from large-scale human demonstrations. We first curate HA-2.2M, a 2.2M-episode action-language dataset reconstructed from heterogeneous human videos through hand-centric filtering, spatial reconstruction, temporal segmentation, and language alignment. On top of this dataset, MoT-HRA factorizes manipulation into three coupled experts: a vision-language expert predicts an embodiment-agnostic 3D trajectory, an intention expert models MANO-style hand motion as a latent human-motion prior, and a fine expert maps the intention-aware representation to robot action chunks. A shared-attention trunk and read-only key-value transfer allow downstream control to use human priors while limiting interference with upstream representations. Experiments on hand motion generation, simulated manipulation, and real-world robot tasks show that MoT-HRA improves motion plausibility and robust control under distribution shift.
Attention Residuals
Mar 16, 2026Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
Master Micro Residual Correction with Adaptive Tactile Fusion and Force-Mixed Control for Contact-Rich Manipulation
Mar 16, 2026Robotic contact-rich and fine-grained manipulation remains a significant challenge due to complex interaction dynamics and the competing requirements of multi-timescale control. While current visual imitation learning methods excel at long-horizon planning, they often fail to perceive critical interaction cues like friction variations or incipient slip, and struggle to balance global task coherence with local reactive feedback. To address these challenges, we propose M2-ResiPolicy, a novel Master-Micro residual control architecture that synergizes high-level action guidance with low-level correction. The framework consists of a Master-Guidance Policy (MGP) operating at 10 Hz, which generates temporally consistent action chunks via a diffusion-based backbone and employs a tactile-intensity-driven adaptive fusion mechanism to dynamically modulate perceptual weights between vision and touch. Simultaneously, a high-frequency (60 Hz) Micro-Residual Corrector (MRC) utilizes a lightweight GRU to provide real-time action compensation based on TCP wrench feedback. This policy is further integrated with a force-mixed PBIC execution layer, effectively regulating contact forces to ensure interaction safety. Experiments across several demanding tasks including fragile object grasping and precision insertion, demonstrate that M2-ResiPolicy significantly outperforms standard Diffusion Policy (DP) and state-of-the-art Reactive Diffusion Policy (RDP), achieving a 93\% damage-free success rate in chip grasping and superior force regulation stability.
RoboStereo: Dual-Tower 4D Embodied World Models for Unified Policy Optimization
Mar 13, 2026Scalable Embodied AI faces fundamental constraints due to prohibitive costs and safety risks of real-world interaction. While Embodied World Models (EWMs) offer promise through imagined rollouts, existing approaches suffer from geometric hallucinations and lack unified optimization frameworks for practical policy improvement. We introduce RoboStereo, a symmetric dual-tower 4D world model that employs bidirectional cross-modal enhancement to ensure spatiotemporal geometric consistency and alleviate physics hallucinations. Building upon this high-fidelity 4D simulator, we present the first unified framework for world-model-based policy optimization: (1) Test-Time Policy Augmentation (TTPA) for pre-execution verification, (2) Imitative-Evolutionary Policy Learning (IEPL) leveraging visual perceptual rewards to learn from expert demonstrations, and (3) Open-Exploration Policy Learning (OEPL) enabling autonomous skill discovery and self-correction. Comprehensive experiments demonstrate RoboStereo achieves state-of-the-art generation quality, with our unified framework delivering >97% average relative improvement on fine-grained manipulation tasks.
Cell Behavior Video Classification Challenge, a benchmark for computer vision methods in time-lapse microscopy
Jan 15, 2026The classification of microscopy videos capturing complex cellular behaviors is crucial for understanding and quantifying the dynamics of biological processes over time. However, it remains a frontier in computer vision, requiring approaches that effectively model the shape and motion of objects without rigid boundaries, extract hierarchical spatiotemporal features from entire image sequences rather than static frames, and account for multiple objects within the field of view. To this end, we organized the Cell Behavior Video Classification Challenge (CBVCC), benchmarking 35 methods based on three approaches: classification of tracking-derived features, end-to-end deep learning architectures to directly learn spatiotemporal features from the entire video sequence without explicit cell tracking, or ensembling tracking-derived with image-derived features. We discuss the results achieved by the participants and compare the potential and limitations of each approach, serving as a basis to foster the development of computer vision methods for studying cellular dynamics.
Universal Visuo-Tactile Video Understanding for Embodied Interaction
May 28, 2025



Tactile perception is essential for embodied agents to understand physical attributes of objects that cannot be determined through visual inspection alone. While existing approaches have made progress in visual and language modalities for physical understanding, they fail to effectively incorporate tactile information that provides crucial haptic feedback for real-world interaction. In this paper, we present VTV-LLM, the first multi-modal large language model for universal Visuo-Tactile Video (VTV) understanding that bridges the gap between tactile perception and natural language. To address the challenges of cross-sensor and cross-modal integration, we contribute VTV150K, a comprehensive dataset comprising 150,000 video frames from 100 diverse objects captured across three different tactile sensors (GelSight Mini, DIGIT, and Tac3D), annotated with four fundamental tactile attributes (hardness, protrusion, elasticity, and friction). We develop a novel three-stage training paradigm that includes VTV enhancement for robust visuo-tactile representation, VTV-text alignment for cross-modal correspondence, and text prompt finetuning for natural language generation. Our framework enables sophisticated tactile reasoning capabilities including feature assessment, comparative analysis, scenario-based decision making and so on. Experimental evaluations demonstrate that VTV-LLM achieves superior performance in tactile video understanding tasks, establishing a foundation for more intuitive human-machine interaction in tactile domains.
Securing the Skies: A Comprehensive Survey on Anti-UAV Methods, Benchmarking, and Future Directions
Apr 16, 2025Unmanned Aerial Vehicles (UAVs) are indispensable for infrastructure inspection, surveillance, and related tasks, yet they also introduce critical security challenges. This survey provides a wide-ranging examination of the anti-UAV domain, centering on three core objectives-classification, detection, and tracking-while detailing emerging methodologies such as diffusion-based data synthesis, multi-modal fusion, vision-language modeling, self-supervised learning, and reinforcement learning. We systematically evaluate state-of-the-art solutions across both single-modality and multi-sensor pipelines (spanning RGB, infrared, audio, radar, and RF) and discuss large-scale as well as adversarially oriented benchmarks. Our analysis reveals persistent gaps in real-time performance, stealth detection, and swarm-based scenarios, underscoring pressing needs for robust, adaptive anti-UAV systems. By highlighting open research directions, we aim to foster innovation and guide the development of next-generation defense strategies in an era marked by the extensive use of UAVs.
WavMark: Watermarking for Audio Generation
Aug 24, 2023



Recent breakthroughs in zero-shot voice synthesis have enabled imitating a speaker's voice using just a few seconds of recording while maintaining a high level of realism. Alongside its potential benefits, this powerful technology introduces notable risks, including voice fraud and speaker impersonation. Unlike the conventional approach of solely relying on passive methods for detecting synthetic data, watermarking presents a proactive and robust defence mechanism against these looming risks. This paper introduces an innovative audio watermarking framework that encodes up to 32 bits of watermark within a mere 1-second audio snippet. The watermark is imperceptible to human senses and exhibits strong resilience against various attacks. It can serve as an effective identifier for synthesized voices and holds potential for broader applications in audio copyright protection. Moreover, this framework boasts high flexibility, allowing for the combination of multiple watermark segments to achieve heightened robustness and expanded capacity. Utilizing 10 to 20-second audio as the host, our approach demonstrates an average Bit Error Rate (BER) of 0.48\% across ten common attacks, a remarkable reduction of over 2800\% in BER compared to the state-of-the-art watermarking tool. See https://aka.ms/wavmark for demos of our work.
Homophone Reveals the Truth: A Reality Check for Speech2Vec
Sep 23, 2022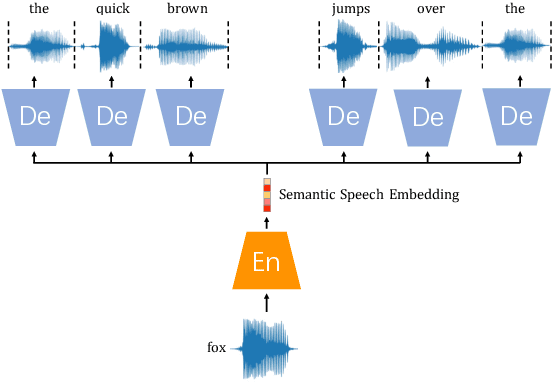

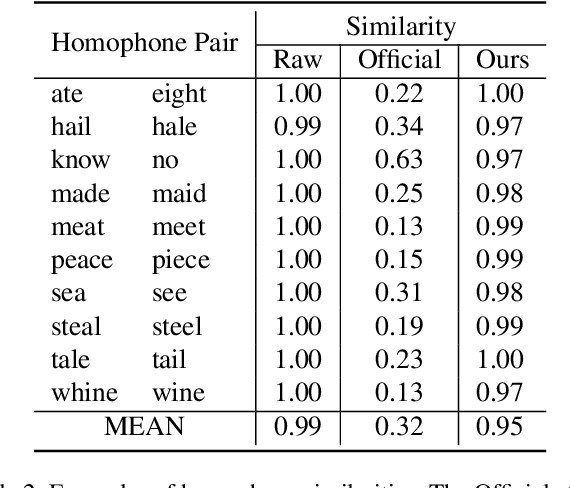
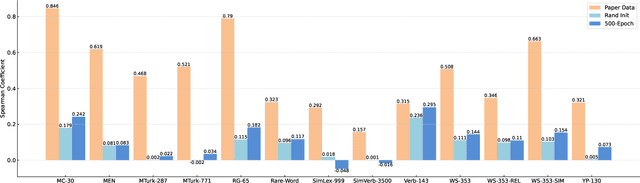
Generating spoken word embeddings that possess semantic information is a fascinating topic. Compared with text-based embeddings, they cover both phonetic and semantic characteristics, which can provide richer information and are potentially helpful for improving ASR and speech translation systems. In this paper, we review and examine the authenticity of a seminal work in this field: Speech2Vec. First, a homophone-based inspection method is proposed to check the speech embeddings released by the author of Speech2Vec. There is no indication that these embeddings are generated by the Speech2Vec model. Moreover, through further analysis of the vocabulary composition, we suspect that a text-based model fabricates these embeddings. Finally, we reproduce the Speech2Vec model, referring to the official code and optimal settings in the original paper. Experiments showed that this model failed to learn effective semantic embeddings. In word similarity benchmarks, it gets a correlation score of 0.08 in MEN and 0.15 in WS-353-SIM tests, which is over 0.5 lower than those described in the original paper. Our data and code are available.