 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-Label: Improving GNN Models for Catalysis Systems by Label Deconstruction and Reconstruction
Mar 06, 2023Attaining the equilibrium state of a catalyst-adsorbate system is key to fundamentally assessing its effective properties, such as adsorption energy. Machine learning methods with finer supervision strategies have been applied to boost and guide the relaxation process of an atomic system and better predict its properties at the equilibrium state. In this paper, we present a novel graph neural network (GNN) supervision and prediction strategy DR-Label. The method enhances the supervision signal, reduces the multiplicity of solutions in edge representation, and encourages the model to provide node predictions that are graph structural variation robust. DR-Label first Deconstructs finer-grained equilibrium state information to the model by projecting the node-level supervision signal to each edge. Reversely, the model Reconstructs a more robust equilibrium state prediction by transforming edge-level predictions to node-level with a sphere-fitting algorithm. The DR-Label strategy was applied to three radically distinct models, each of which displayed consistent performance enhancements. Based on the DR-Label strategy, we further proposed DRFormer, which achieved a new state-of-the-art performance on the Open Catalyst 2020 (OC20) dataset and the Cu-based single-atom-alloyed CO adsorption (SAA) dataset. We expect that our work will highlight crucial steps for the development of a more accurate model in equilibrium state property prediction of a catalysis system.
RepMode: Learning to Re-parameterize Diverse Experts for Subcellular Structure Prediction
Dec 20, 2022



In subcellular biological research, fluorescence staining is a key technique to reveal the locations and morphology of subcellular structures. However, fluorescence staining is slow, expensive, and harmful to cells. In this paper, we treat it as a deep learning task termed subcellular structure prediction (SSP), aiming to predict the 3D fluorescent images of multiple subcellular structures from a 3D transmitted-light image. Unfortunately, due to the limitations of current biotechnology, each image is partially labeled in SSP. Besides, naturally, the subcellular structures vary considerably in size, which causes the multi-scale issue in SSP. However, traditional solutions can not address SSP well since they organize network parameters inefficiently and inflexibly. To overcome these challenges, we propose Re-parameterizing Mixture-of-Diverse-Experts (RepMode), a network that dynamically organizes its parameters with task-aware priors to handle specified single-label prediction tasks of SSP. In RepMode, the Mixture-of-Diverse-Experts (MoDE) block is designed to learn the generalized parameters for all tasks, and gating re-parameterization (GatRep) is performed to generate the specialized parameters for each task, by which RepMode can maintain a compact practical topology exactly like a plain network, and meanwhile achieves a powerful theoretical topology. Comprehensive experiments show that RepMode outperforms existing methods on ten of twelve prediction tasks of SSP and achieves state-of-the-art overall performance.
G-MAP: General Memory-Augmented Pre-trained Language Model for Domain Tasks
Dec 08, 2022Recently, domain-specific PLMs have been proposed to boost the task performance of specific domains (e.g., biomedical and computer science) by continuing to pre-train general PLMs with domain-specific corpora. However, this Domain-Adaptive Pre-Training (DAPT; Gururangan et al. (2020)) tends to forget the previous general knowledge acquired by general PLMs, which leads to a catastrophic forgetting phenomenon and sub-optimal performance. To alleviate this problem, we propose a new framework of General Memory Augmented Pre-trained Language Model (G-MAP), which augments the domain-specific PLM by a memory representation built from the frozen general PLM without losing any general knowledge. Specifically, we propose a new memory-augmented layer, and based on it, different augmented strategies are explored to build the memory representation and then adaptively fuse it into the domain-specific PLM. We demonstrate the effectiveness of G-MAP on various domains (biomedical and computer science publications, news, and reviews) and different kinds (text classification, QA, NER) of tasks, and the extensive results show that the proposed G-MAP can achieve SOTA results on all tasks.
Spatio-Temporal Contrastive Learning Enhanced GNNs for Session-based Recommendation
Sep 23, 2022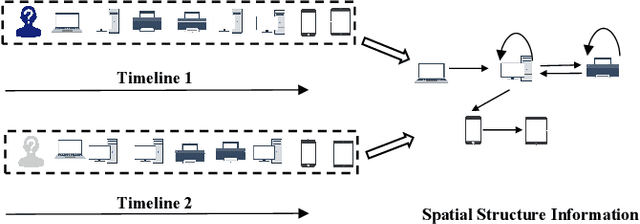


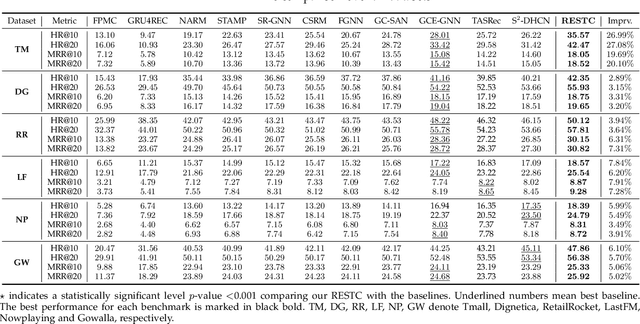
Session-based recommendation (SBR) systems aim to utilize the user's short-term behavior sequence to predict the next item without the detailed user profile. Most recent works try to model the user preference by treating the sessions as between-item transition graphs and utilize various graph neural networks (GNNs) to encode the representations of pair-wise relations among items and their neighbors. Some of the existing GNN-based models mainly focus on aggregating information from the view of spatial graph structure, which ignores the temporal relations within neighbors of an item during message passing and the information loss results in a sub-optimal problem. Other works embrace this challenge by incorporating additional temporal information but lack sufficient interaction between the spatial and temporal patterns. To address this issue, inspired by the uniformity and alignment properties of contrastive learning techniques, we propose a novel framework called Session-based Recommendation with Spatio-Temporal Contrastive Learning Enhanced GNNs (RESTC). The idea is to supplement the GNN-based main supervised recommendation task with the temporal representation via an auxiliary cross-view contrastive learning mechanism. Furthermore, a novel global collaborative filtering graph (CFG) embedding is leveraged to enhance the spatial view in the main task. Extensive experiments demonstrate the significant performance of RESTC compared with the state-of-the-art baselines e.g., with an improvement as much as 27.08% gain on HR@20 and 20.10% gain on MRR@20.
A Survey on Generative Diffusion Model
Sep 21, 2022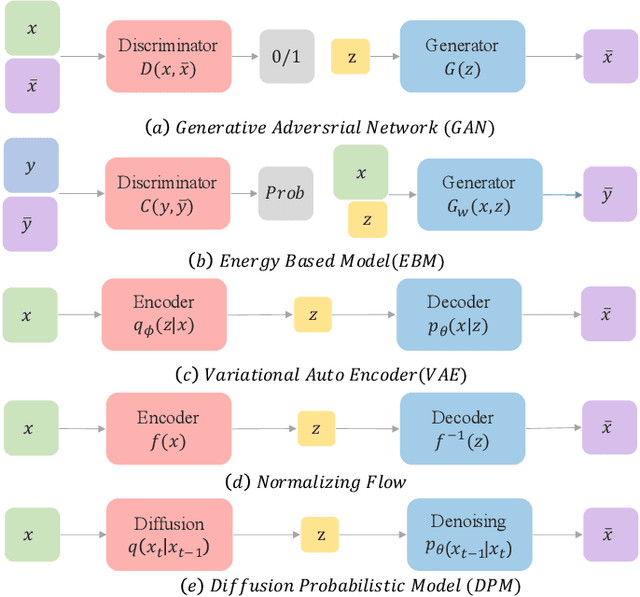
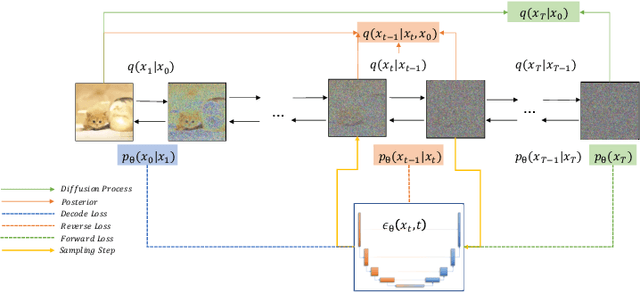
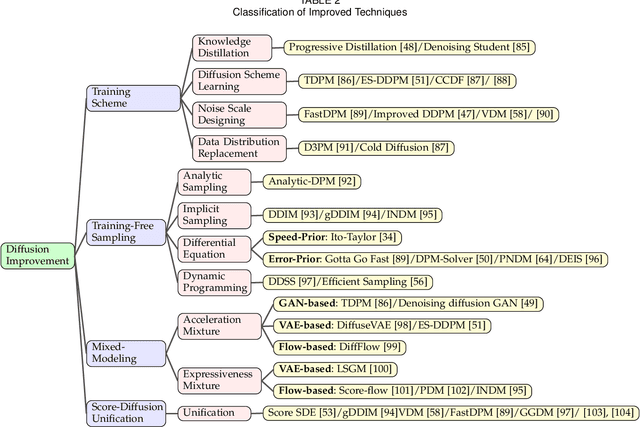
Deep learning shows great potential in generation tasks thanks to deep latent representation. Generative models are classes of models that can generate observations randomly with respect to certain implied parameters. Recently, the diffusion Model becomes a raising class of generative models by virtue of its power-generating ability. Nowadays, great achievements have been reached. More applications except for computer vision, speech generation, bioinformatics, and natural language processing are to be explored in this field. However, the diffusion model has its natural drawback of a slow generation process, leading to many enhanced works. This survey makes a summary of the field of the diffusion model. We firstly state the main problem with two landmark works - DDPM and DSM. Then, we present a diverse range of advanced techniques to speed up the diffusion models - training schedule, training-free sampling, mixed-modeling, and score & diffusion unification. Regarding existing models, we also provide a benchmark of FID score, IS, and NLL according to specific NFE. Moreover, applications with diffusion models are introduced including computer vision, sequence modeling, audio, and AI for science. Finally, there is a summarization of this field together with limitations & further directions.
Multi-Task Mixture Density Graph Neural Networks for Predicting Cu-based Single-Atom Alloy Catalysts for CO2 Reduction Reaction
Sep 15, 2022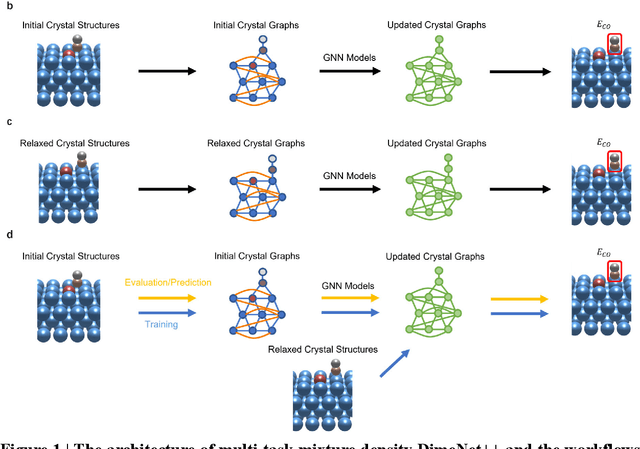
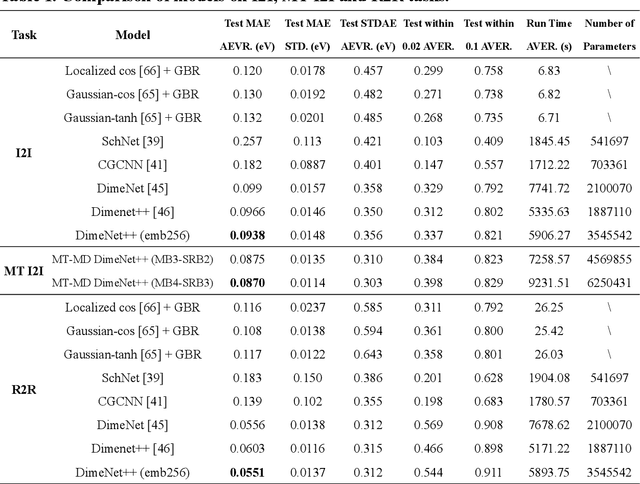
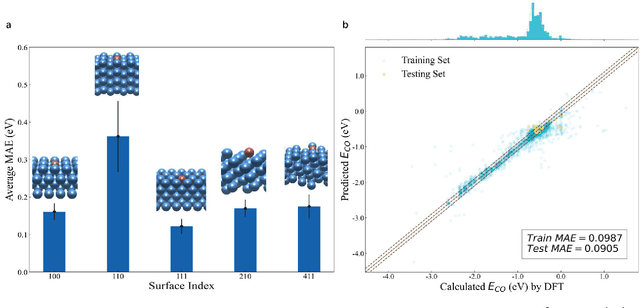

Graph neural networks (GNNs) have drawn more and more attention from material scientists and demonstrated a high capacity to establish connections between the structure and properties. However, with only unrelaxed structures provided as input, few GNN models can predict the thermodynamic properties of relaxed configurations with an acceptable level of error. In this work, we develop a multi-task (MT) architecture based on DimeNet++ and mixture density networks to improve the performance of such task. Taking CO adsorption on Cu-based single-atom alloy catalysts as an illustration, we show that our method can reliably estimate CO adsorption energy with a mean absolute error of 0.087 eV from the initial CO adsorption structures without costly first-principles calculations. Further, compared to other state-of-the-art GNN methods, our model exhibits improved generalization ability when predicting catalytic performance of out-of-domain configurations, built with either unseen substrate surfaces or doping species. We show that the proposed MT GNN strategy can facilitate catalyst discovery.
MetaRF: Differentiable Random Forest for Reaction Yield Prediction with a Few Trails
Aug 22, 2022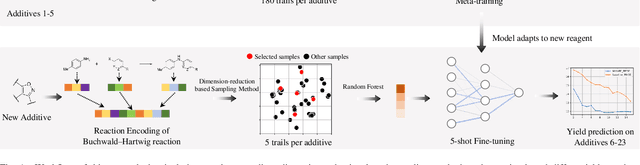
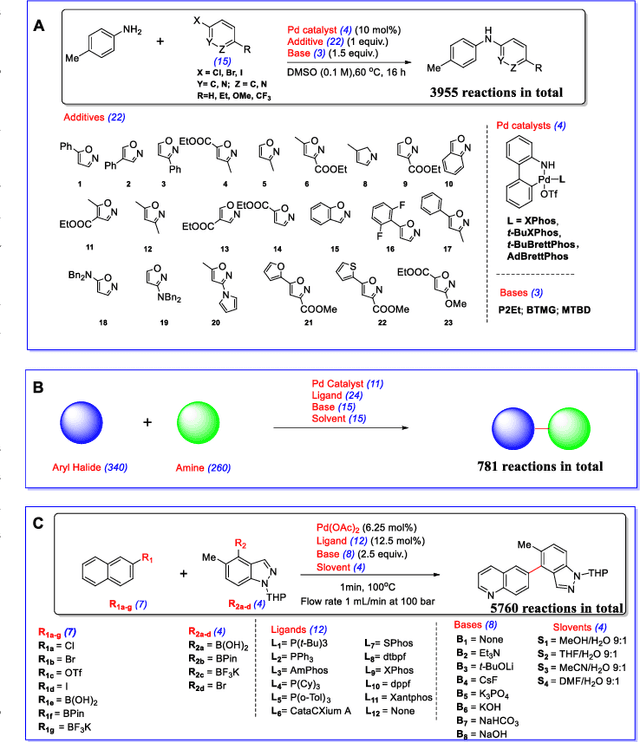
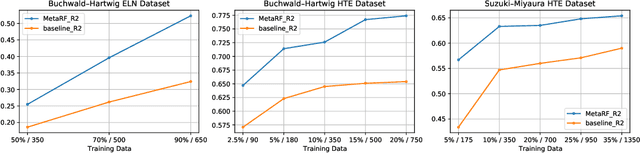
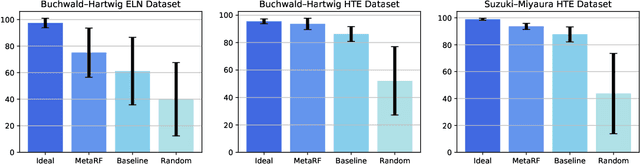
Artificial intelligence has deeply revolutionized the field of medicinal chemistry with many impressive applications, but the success of these applications requires a massive amount of training samples with high-quality annotations, which seriously limits the wide usage of data-driven methods. In this paper, we focus on the reaction yield prediction problem, which assists chemists in selecting high-yield reactions in a new chemical space only with a few experimental trials. To attack this challenge, we first put forth MetaRF, an attention-based differentiable random forest model specially designed for the few-shot yield prediction, where the attention weight of a random forest is automatically optimized by the meta-learning framework and can be quickly adapted to predict the performance of new reagents while given a few additional samples. To improve the few-shot learning performance, we further introduce a dimension-reduction based sampling method to determine valuable samples to be experimentally tested and then learned. Our methodology is evaluated on three different datasets and acquires satisfactory performance on few-shot prediction. In high-throughput experimentation (HTE) datasets, the average yield of our methodology's top 10 high-yield reactions is relatively close to the results of ideal yield selection.
Pseudo-label Guided Cross-video Pixel Contrast for Robotic Surgical Scene Segmentation with Limited Annotations
Jul 20, 2022



Surgical scene segmentation is fundamentally crucial for prompting cognitive assistance in robotic surgery. However, pixel-wise annotating surgical video in a frame-by-frame manner is expensive and time consuming. To greatly reduce the labeling burden, in this work, we study semi-supervised scene segmentation from robotic surgical video, which is practically essential yet rarely explored before. We consider a clinically suitable annotation situation under the equidistant sampling. We then propose PGV-CL, a novel pseudo-label guided cross-video contrast learning method to boost scene segmentation. It effectively leverages unlabeled data for a trusty and global model regularization that produces more discriminative feature representation. Concretely, for trusty representation learning, we propose to incorporate pseudo labels to instruct the pair selection, obtaining more reliable representation pairs for pixel contrast. Moreover, we expand the representation learning space from previous image-level to cross-video, which can capture the global semantics to benefit the learning process. We extensively evaluate our method on a public robotic surgery dataset EndoVis18 and a public cataract dataset CaDIS. Experimental results demonstrate the effectiveness of our method, consistently outperforming the state-of-the-art semi-supervised methods under different labeling ratios, and even surpassing fully supervised training on EndoVis18 with 10.1% labeling.
Explore More Guidance: A Task-aware Instruction Network for Sign Language Translation Enhanced with Data Augmentation
Apr 12, 2022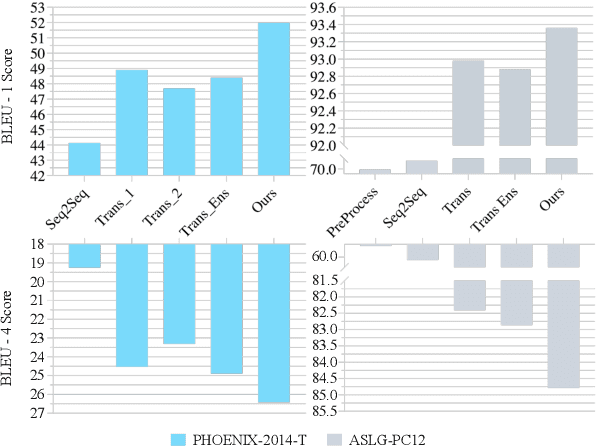
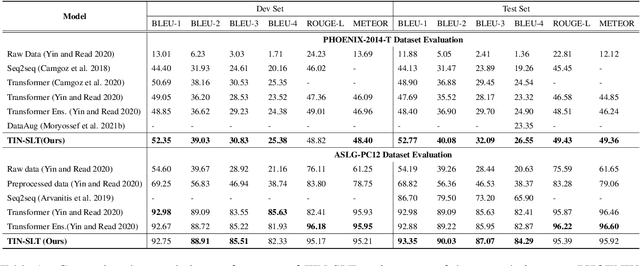
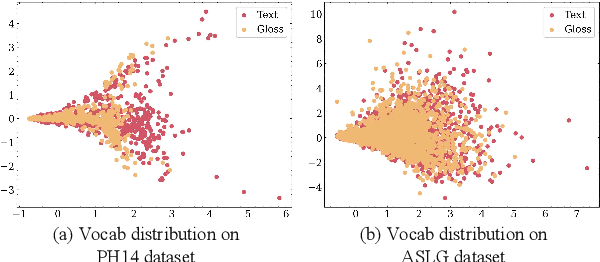
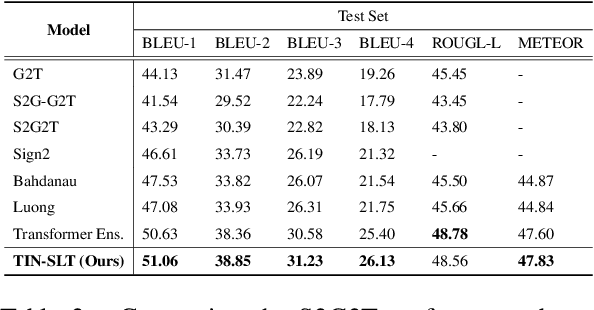
Sign language recognition and translation first uses a recognition module to generate glosses from sign language videos and then employs a translation module to translate glosses into spoken sentences. Most existing works focus on the recognition step, while paying less attention to sign language translation. In this work, we propose a task-aware instruction network, namely TIN-SLT, for sign language translation, by introducing the instruction module and the learning-based feature fuse strategy into a Transformer network. In this way, the pre-trained model's language ability can be well explored and utilized to further boost the translation performance. Moreover, by exploring the representation space of sign language glosses and target spoken language, we propose a multi-level data augmentation scheme to adjust the data distribution of the training set. We conduct extensive experiments on two challenging benchmark datasets, PHOENIX-2014-T and ASLG-PC12, on which our method outperforms former best solutions by 1.65 and 1.42 in terms of BLEU-4. Our code is published at https://github.com/yongcaoplus/TIN-SLT.
Acknowledging the Unknown for Multi-label Learning with Single Positive Labels
Mar 30, 2022
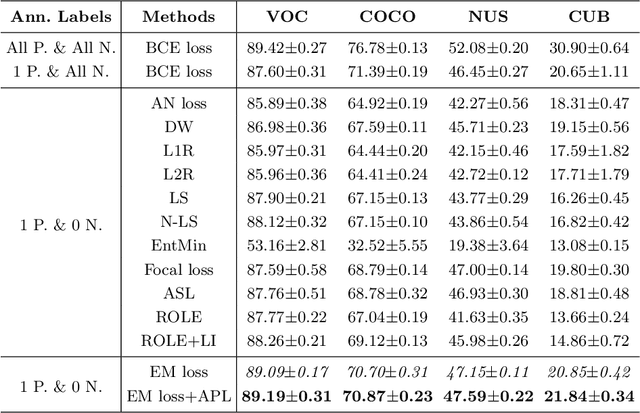
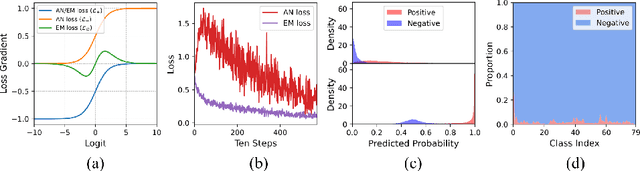

Due to the difficulty of collecting exhaustive multi-label annotations, multi-label training data often contains partial labels. We consider an extreme of this problem, called single positive multi-label learning (SPML), where each multi-label training image has only one positive label. Traditionally, all unannotated labels are assumed as negative labels in SPML, which would introduce false negative labels and make model training be dominated by assumed negative labels. In this work, we choose to treat all unannotated labels from a different perspective, \textit{i.e.} acknowledging they are unknown. Hence, we propose entropy-maximization (EM) loss to maximize the entropy of predicted probabilities for all unannotated labels. Considering the positive-negative label imbalance of unannotated labels, we propose asymmetric pseudo-labeling (APL) with asymmetric-tolerance strategies and a self-paced procedure to provide more precise supervision. Experiments show that our method significantly improves performance and achieves state-of-the-art results on all four benchmarks.