 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
Jun 02, 2022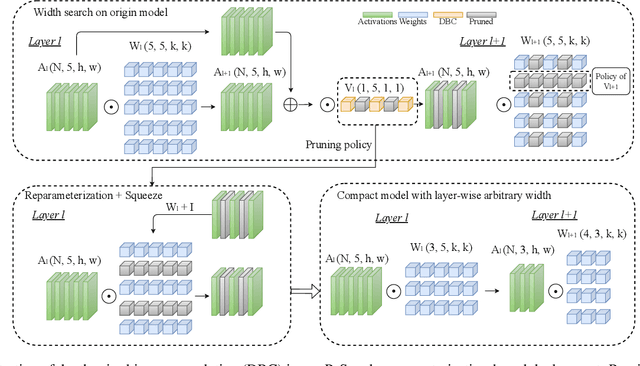
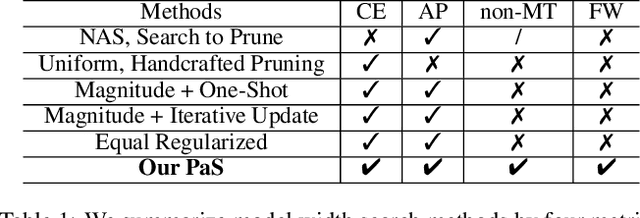

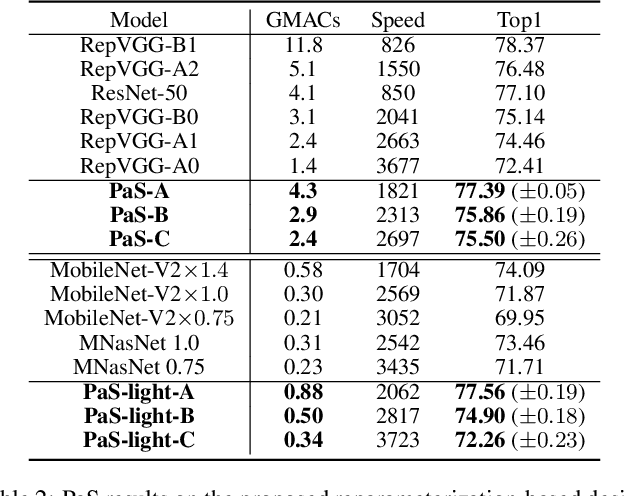
Neural architecture search (NAS) and network pruning are widely studied efficient AI techniques, but not yet perfect. NAS performs exhaustive candidate architecture search, incurring tremendous search cost. Though (structured) pruning can simply shrink model dimension, it remains unclear how to decide the per-layer sparsity automatically and optimally. In this work, we revisit the problem of layer-width optimization and propose Pruning-as-Search (PaS), an end-to-end channel pruning method to search out desired sub-network automatically and efficiently. Specifically, we add a depth-wise binary convolution to learn pruning policies directly through gradient descent. By combining the structural reparameterization and PaS, we successfully searched out a new family of VGG-like and lightweight networks, which enable the flexibility of arbitrary width with respect to each layer instead of each stage. Experimental results show that our proposed architecture outperforms prior arts by around $1.0\%$ top-1 accuracy under similar inference speed on ImageNet-1000 classification task. Furthermore, we demonstrate the effectiveness of our width search on complex tasks including instance segmentation and image translation. Code and models are released.
EfficientFormer: Vision Transformers at MobileNet Speed
Jun 02, 2022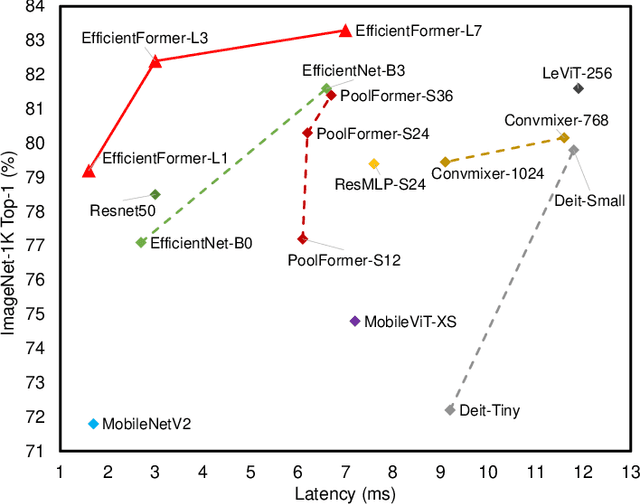
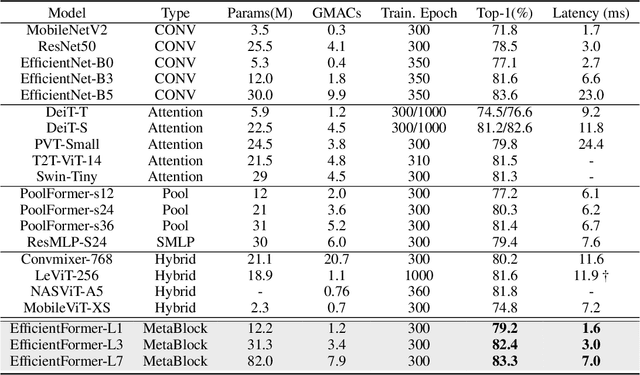
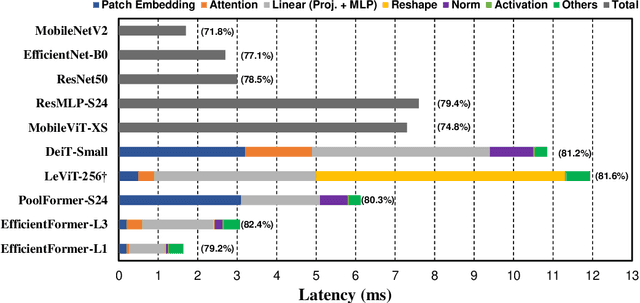
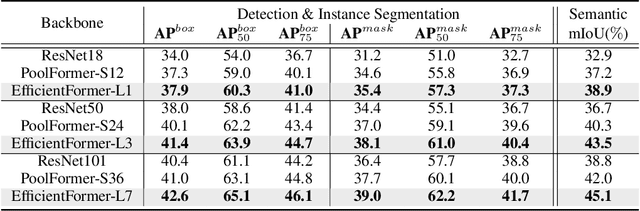
Vision Transformers (ViT) have shown rapid progress in computer vision tasks, achieving promising results on various benchmarks. However, due to the massive number of parameters and model design, e.g., attention mechanism, ViT-based models are generally times slower than lightweight convolutional networks. Therefore, the deployment of ViT for real-time applications is particularly challenging, especially on resource-constrained hardware such as mobile devices. Recent efforts try to reduce the computation complexity of ViT through network architecture search or hybrid design with MobileNet block, yet the inference speed is still unsatisfactory. This leads to an important question: can transformers run as fast as MobileNet while obtaining high performance? To answer this, we first revisit the network architecture and operators used in ViT-based models and identify inefficient designs. Then we introduce a dimension-consistent pure transformer (without MobileNet blocks) as design paradigm. Finally, we perform latency-driven slimming to get a series of final models dubbed EfficientFormer. Extensive experiments show the superiority of EfficientFormer in performance and speed on mobile devices. Our fastest model, EfficientFormer-L1, achieves 79.2% top-1 accuracy on ImageNet-1K with only 1.6 ms inference latency on iPhone 12 (compiled with CoreML), which is even a bit faster than MobileNetV2 (1.7 ms, 71.8% top-1), and our largest model, EfficientFormer-L7, obtains 83.3% accuracy with only 7.0 ms latency. Our work proves that properly designed transformers can reach extremely low latency on mobile devices while maintaining high performance
Automatic Mapping of the Best-Suited DNN Pruning Schemes for Real-Time Mobile Acceleration
Nov 22, 2021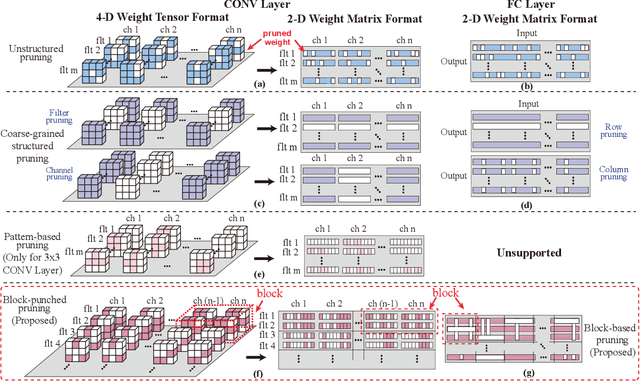

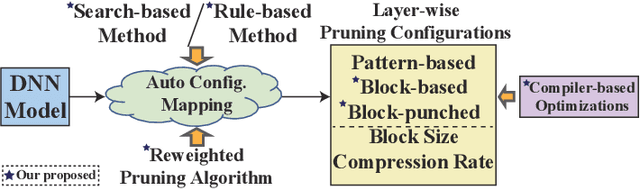
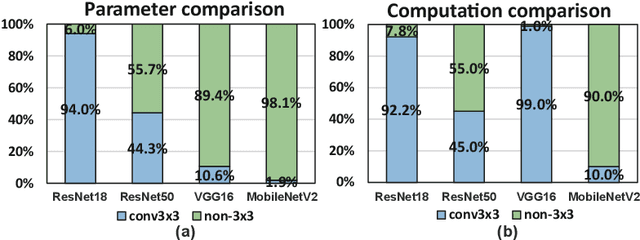
Weight pruning is an effective model compression technique to tackle the challenges of achieving real-time deep neural network (DNN) inference on mobile devices. However, prior pruning schemes have limited application scenarios due to accuracy degradation, difficulty in leveraging hardware acceleration, and/or restriction on certain types of DNN layers. In this paper, we propose a general, fine-grained structured pruning scheme and corresponding compiler optimizations that are applicable to any type of DNN layer while achieving high accuracy and hardware inference performance. With the flexibility of applying different pruning schemes to different layers enabled by our compiler optimizations, we further probe into the new problem of determining the best-suited pruning scheme considering the different acceleration and accuracy performance of various pruning schemes. Two pruning scheme mapping methods, one is search-based and the other is rule-based, are proposed to automatically derive the best-suited pruning regularity and block size for each layer of any given DNN. Experimental results demonstrate that our pruning scheme mapping methods, together with the general fine-grained structured pruning scheme, outperform the state-of-the-art DNN optimization framework with up to 2.48$\times$ and 1.73$\times$ DNN inference acceleration on CIFAR-10 and ImageNet dataset without accuracy loss.
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021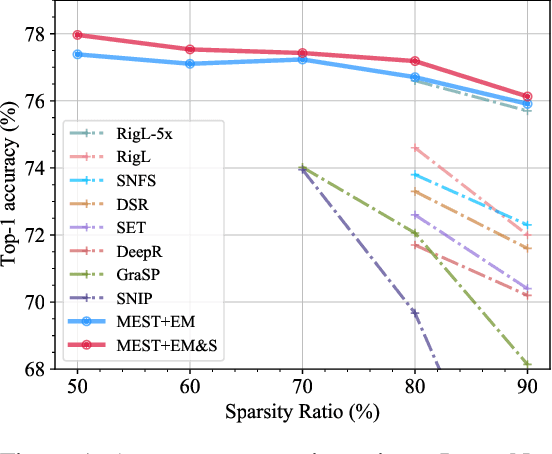
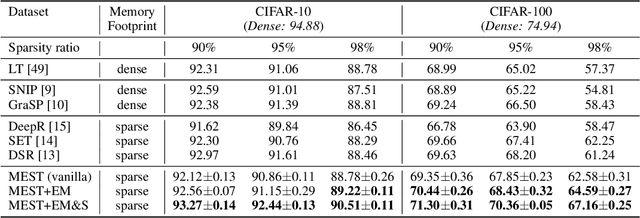
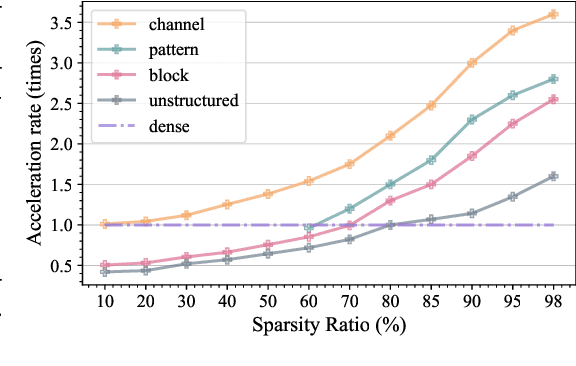
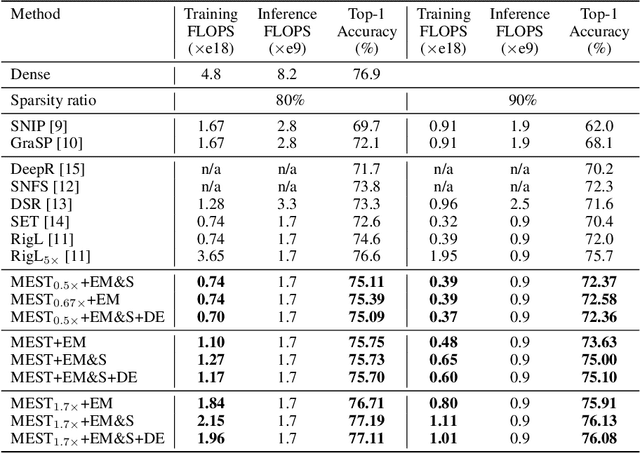
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021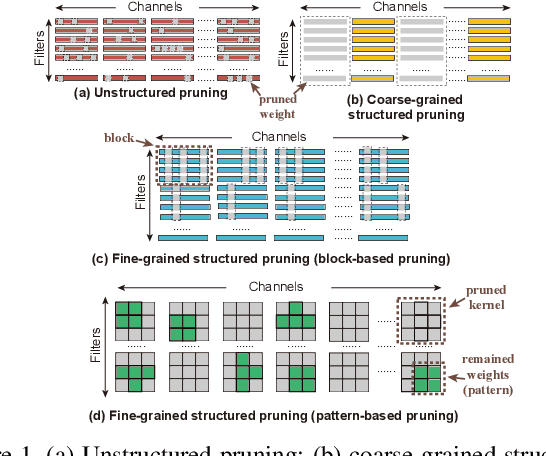
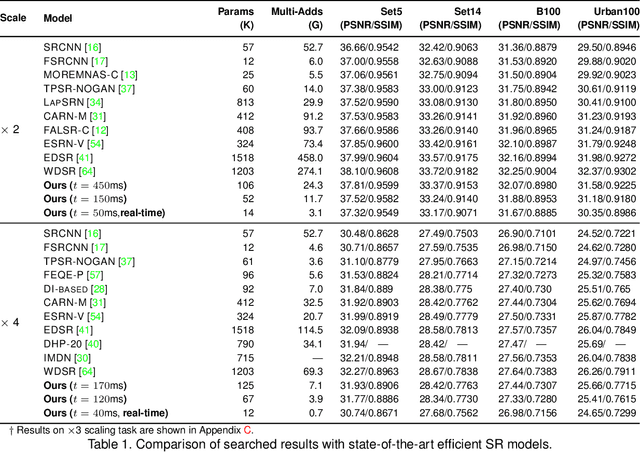
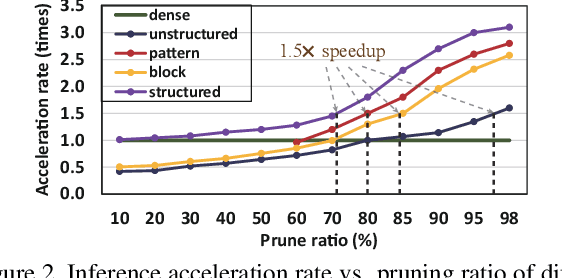
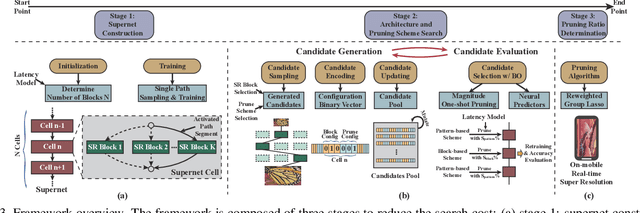
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
Sanity Checks for Lottery Tickets: Does Your Winning Ticket Really Win the Jackpot?
Jul 01, 2021
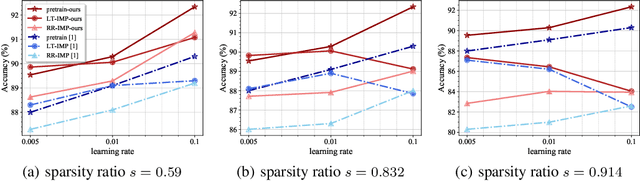
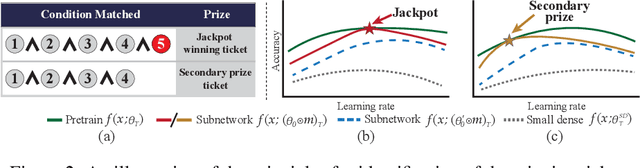

There have been long-standing controversies and inconsistencies over the experiment setup and criteria for identifying the "winning ticket" in literature. To reconcile such, we revisit the definition of lottery ticket hypothesis, with comprehensive and more rigorous conditions. Under our new definition, we show concrete evidence to clarify whether the winning ticket exists across the major DNN architectures and/or applications. Through extensive experiments, we perform quantitative analysis on the correlations between winning tickets and various experimental factors, and empirically study the patterns of our observations. We find that the key training hyperparameters, such as learning rate and training epochs, as well as the architecture characteristics such as capacities and residual connections, are all highly correlated with whether and when the winning tickets can be identified. Based on our analysis, we summarize a guideline for parameter settings in regards of specific architecture characteristics, which we hope to catalyze the research progress on the topic of lottery ticket hypothesis.
Achieving Real-Time Object Detection on MobileDevices with Neural Pruning Search
Jun 28, 2021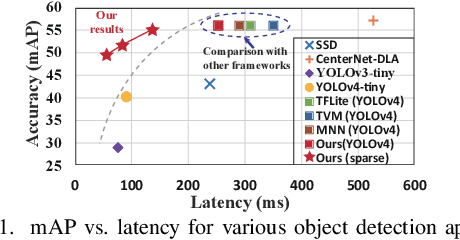
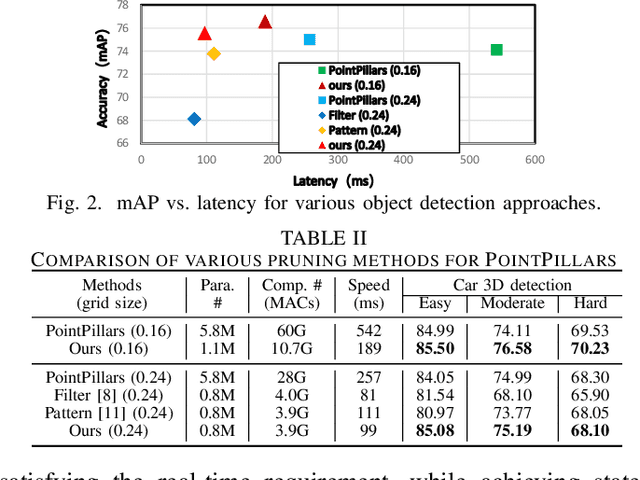
Object detection plays an important role in self-driving cars for security development. However, mobile systems on self-driving cars with limited computation resources lead to difficulties for object detection. To facilitate this, we propose a compiler-aware neural pruning search framework to achieve high-speed inference on autonomous vehicles for 2D and 3D object detection. The framework automatically searches the pruning scheme and rate for each layer to find a best-suited pruning for optimizing detection accuracy and speed performance under compiler optimization. Our experiments demonstrate that for the first time, the proposed method achieves (close-to) real-time, 55ms and 99ms inference times for YOLOv4 based 2D object detection and PointPillars based 3D detection, respectively, on an off-the-shelf mobile phone with minor (or no) accuracy loss.
Improving DNN Fault Tolerance using Weight Pruning and Differential Crossbar Mapping for ReRAM-based Edge AI
Jun 18, 2021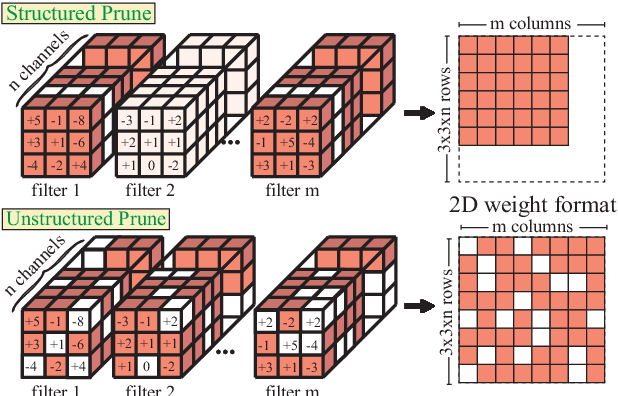
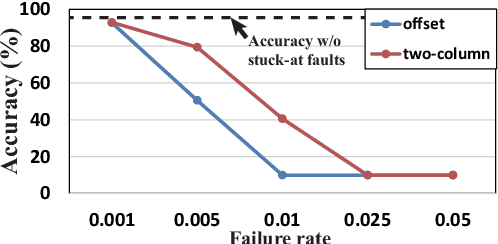
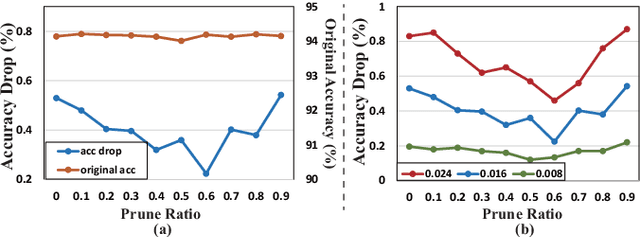
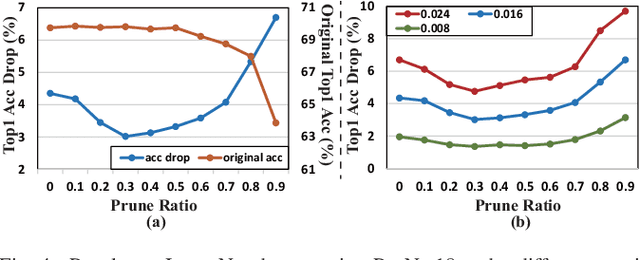
Recent research demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in deep neural networks (DNNs). However, hardware failure, such as stuck-at-fault defects, is one of the main concerns that impedes the ReRAM devices to be a feasible solution for real implementations. The existing solutions to address this issue usually require an optimization to be conducted for each individual device, which is impractical for mass-produced products (e.g., IoT devices). In this paper, we rethink the value of weight pruning in ReRAM-based DNN design from the perspective of model fault tolerance. And a differential mapping scheme is proposed to improve the fault tolerance under a high stuck-on fault rate. Our method can tolerate almost an order of magnitude higher failure rate than the traditional two-column method in representative DNN tasks. More importantly, our method does not require extra hardware cost compared to the traditional two-column mapping scheme. The improvement is universal and does not require the optimization process for each individual device.
FORMS: Fine-grained Polarized ReRAM-based In-situ Computation for Mixed-signal DNN Accelerator
Jun 16, 2021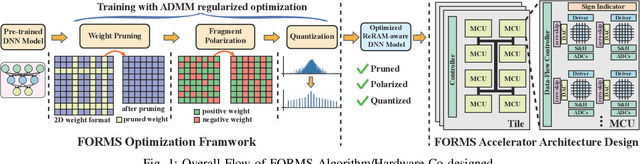
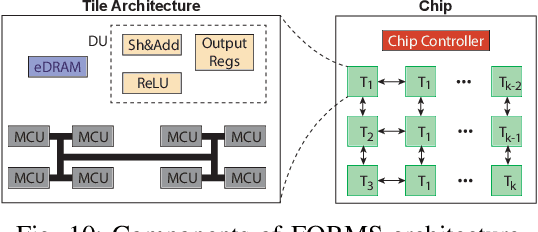
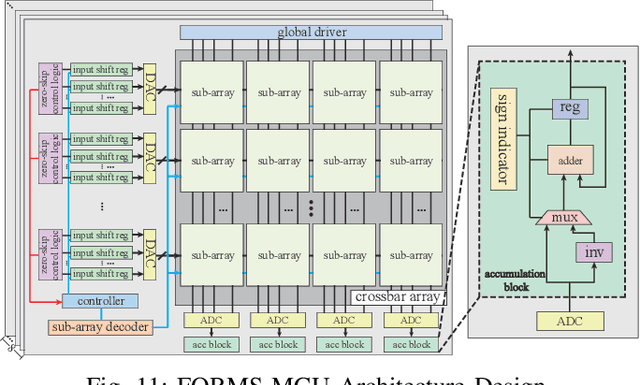

Recent works demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in DNNs. With weights stored in the ReRAM crossbar cells as conductance, when the input vector is applied to word lines, the matrix-vector multiplication results can be generated as the current in bit lines. A key problem is that the weight can be either positive or negative, but the in-situ computation assumes all cells on each crossbar column with the same sign. The current architectures either use two ReRAM crossbars for positive and negative weights, or add an offset to weights so that all values become positive. Neither solution is ideal: they either double the cost of crossbars, or incur extra offset circuity. To better solve this problem, this paper proposes FORMS, a fine-grained ReRAM-based DNN accelerator with polarized weights. Instead of trying to represent the positive/negative weights, our key design principle is to enforce exactly what is assumed in the in-situ computation -- ensuring that all weights in the same column of a crossbar have the same sign. It naturally avoids the cost of an additional crossbar. Such weights can be nicely generated using alternating direction method of multipliers (ADMM) regularized optimization, which can exactly enforce certain patterns in DNN weights. To achieve high accuracy, we propose to use fine-grained sub-array columns, which provide a unique opportunity for input zero-skipping, significantly avoiding unnecessary computations. It also makes the hardware much easier to implement. Putting all together, with the same optimized models, FORMS achieves significant throughput improvement and speed up in frame per second over ISAAC with similar area cost.
Towards Fast and Accurate Multi-Person Pose Estimation on Mobile Devices
Jun 06, 2021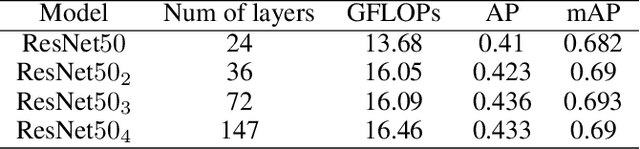


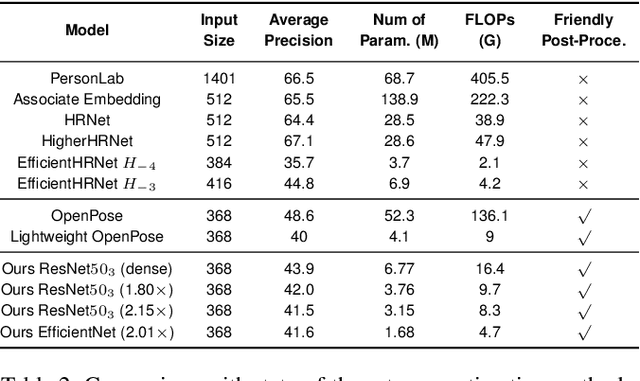
The rapid development of autonomous driving, abnormal behavior detection, and behavior recognition makes an increasing demand for multi-person pose estimation-based applications, especially on mobile platforms. However, to achieve high accuracy, state-of-the-art methods tend to have a large model size and complex post-processing algorithm, which costs intense computation and long end-to-end latency. To solve this problem, we propose an architecture optimization and weight pruning framework to accelerate inference of multi-person pose estimation on mobile devices. With our optimization framework, we achieve up to 2.51x faster model inference speed with higher accuracy compared to representative lightweight multi-person pose estimator.