 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2023 Low-Power Computer Vision Challenge (LPCVC) Summary
Mar 11, 2024



This article describes the 2023 IEEE Low-Power Computer Vision Challenge (LPCVC). Since 2015, LPCVC has been an international competition devoted to tackling the challenge of computer vision (CV) on edge devices. Most CV researchers focus on improving accuracy, at the expense of ever-growing sizes of machine models. LPCVC balances accuracy with resource requirements. Winners must achieve high accuracy with short execution time when their CV solutions run on an embedded device, such as Raspberry PI or Nvidia Jetson Nano. The vision problem for 2023 LPCVC is segmentation of images acquired by Unmanned Aerial Vehicles (UAVs, also called drones) after disasters. The 2023 LPCVC attracted 60 international teams that submitted 676 solutions during the submission window of one month. This article explains the setup of the competition and highlights the winners' methods that improve accuracy and shorten execution time.
SimPro: A Simple Probabilistic Framework Towards Realistic Long-Tailed Semi-Supervised Learning
Feb 21, 2024



Recent advancements in semi-supervised learning have focused on a more realistic yet challenging task: addressing imbalances in labeled data while the class distribution of unlabeled data remains both unknown and potentially mismatched. Current approaches in this sphere often presuppose rigid assumptions regarding the class distribution of unlabeled data, thereby limiting the adaptability of models to only certain distribution ranges. In this study, we propose a novel approach, introducing a highly adaptable framework, designated as SimPro, which does not rely on any predefined assumptions about the distribution of unlabeled data. Our framework, grounded in a probabilistic model, innovatively refines the expectation-maximization (EM) algorithm by explicitly decoupling the modeling of conditional and marginal class distributions. This separation facilitates a closed-form solution for class distribution estimation during the maximization phase, leading to the formulation of a Bayes classifier. The Bayes classifier, in turn, enhances the quality of pseudo-labels in the expectation phase. Remarkably, the SimPro framework not only comes with theoretical guarantees but also is straightforward to implement. Moreover, we introduce two novel class distributions broadening the scope of the evaluation. Our method showcases consistent state-of-the-art performance across diverse benchmarks and data distribution scenarios. Our code is available at https://github.com/LeapLabTHU/SimPro.
LLM Agents for Psychology: A Study on Gamified Assessments
Feb 19, 2024Psychological measurement is essential for mental health, self-understanding, and personal development. Traditional methods, such as self-report scales and psychologist interviews, often face challenges with engagement and accessibility. While game-based and LLM-based tools have been explored to improve user interest and automate assessment, they struggle to balance engagement with generalizability. In this work, we propose PsychoGAT (Psychological Game AgenTs) to achieve a generic gamification of psychological assessment. The main insight is that powerful LLMs can function both as adept psychologists and innovative game designers. By incorporating LLM agents into designated roles and carefully managing their interactions, PsychoGAT can transform any standardized scales into personalized and engaging interactive fiction games. To validate the proposed method, we conduct psychometric evaluations to assess its effectiveness and employ human evaluators to examine the generated content across various psychological constructs, including depression, cognitive distortions, and personality traits. Results demonstrate that PsychoGAT serves as an effective assessment tool, achieving statistically significant excellence in psychometric metrics such as reliability, convergent validity, and discriminant validity. Moreover, human evaluations confirm PsychoGAT's enhancements in content coherence, interactivity, interest, immersion, and satisfaction.
Segment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels
Dec 28, 2023Current 3D scene segmentation methods are heavily dependent on manually annotated 3D training datasets. Such manual annotations are labor-intensive, and often lack fine-grained details. Importantly, models trained on this data typically struggle to recognize object classes beyond the annotated classes, i.e., they do not generalize well to unseen domains and require additional domain-specific annotations. In contrast, 2D foundation models demonstrate strong generalization and impressive zero-shot abilities, inspiring us to incorporate these characteristics from 2D models into 3D models. Therefore, we explore the use of image segmentation foundation models to automatically generate training labels for 3D segmentation. We propose Segment3D, a method for class-agnostic 3D scene segmentation that produces high-quality 3D segmentation masks. It improves over existing 3D segmentation models (especially on fine-grained masks), and enables easily adding new training data to further boost the segmentation performance -- all without the need for manual training labels.
A-SDM: Accelerating Stable Diffusion through Redundancy Removal and Performance Optimization
Dec 27, 2023



The Stable Diffusion Model (SDM) is a popular and efficient text-to-image (t2i) generation and image-to-image (i2i) generation model. Although there have been some attempts to reduce sampling steps, model distillation, and network quantization, these previous methods generally retain the original network architecture. Billion scale parameters and high computing requirements make the research of model architecture adjustment scarce. In this work, we first explore the computational redundancy part of the network, and then prune the redundancy blocks of the model and maintain the network performance through a progressive incubation strategy. Secondly, in order to maintaining the model performance, we add cross-layer multi-expert conditional convolution (CLME-Condconv) to the block pruning part to inherit the original convolution parameters. Thirdly, we propose a global-regional interactive (GRI) attention to speed up the computationally intensive attention part. Finally, we use semantic-aware supervision (SAS) to align the outputs of the teacher model and student model at the semantic level. Experiments show that this method can effectively train a lightweight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. Experiments show that the proposed method can effectively train a light-weight model close to the performance of the original SD model, and effectively improve the model speed under limited resources. After acceleration, the UNet part of the model is 22% faster and the overall speed is 19% faster.
Agent Attention: On the Integration of Softmax and Linear Attention
Dec 22, 2023



The attention module is the key component in Transformers. While the global attention mechanism offers high expressiveness, its excessive computational cost restricts its applicability in various scenarios. In this paper, we propose a novel attention paradigm, Agent Attention, to strike a favorable balance between computational efficiency and representation power. Specifically, the Agent Attention, denoted as a quadruple $(Q, A, K, V)$, introduces an additional set of agent tokens $A$ into the conventional attention module. The agent tokens first act as the agent for the query tokens $Q$ to aggregate information from $K$ and $V$, and then broadcast the information back to $Q$. Given the number of agent tokens can be designed to be much smaller than the number of query tokens, the agent attention is significantly more efficient than the widely adopted Softmax attention, while preserving global context modelling capability. Interestingly, we show that the proposed agent attention is equivalent to a generalized form of linear attention. Therefore, agent attention seamlessly integrates the powerful Softmax attention and the highly efficient linear attention. Extensive experiments demonstrate the effectiveness of agent attention with various vision Transformers and across diverse vision tasks, including image classification, object detection, semantic segmentation and image generation. Notably, agent attention has shown remarkable performance in high-resolution scenarios, owning to its linear attention nature. For instance, when applied to Stable Diffusion, our agent attention accelerates generation and substantially enhances image generation quality without any additional training. Code is available at https://github.com/LeapLabTHU/Agent-Attention.
Mask Grounding for Referring Image Segmentation
Dec 19, 2023


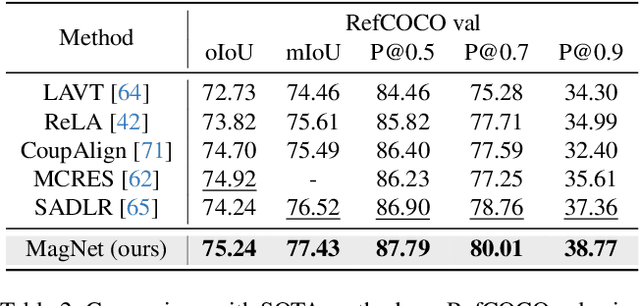
Referring Image Segmentation (RIS) is a challenging task that requires an algorithm to segment objects referred by free-form language expressions. Despite significant progress in recent years, most state-of-the-art (SOTA) methods still suffer from considerable language-image modality gap at the pixel and word level. These methods generally 1) rely on sentence-level language features for language-image alignment and 2) lack explicit training supervision for fine-grained visual grounding. Consequently, they exhibit weak object-level correspondence between visual and language features. Without well-grounded features, prior methods struggle to understand complex expressions that require strong reasoning over relationships among multiple objects, especially when dealing with rarely used or ambiguous clauses. To tackle this challenge, we introduce a novel Mask Grounding auxiliary task that significantly improves visual grounding within language features, by explicitly teaching the model to learn fine-grained correspondence between masked textual tokens and their matching visual objects. Mask Grounding can be directly used on prior RIS methods and consistently bring improvements. Furthermore, to holistically address the modality gap, we also design a cross-modal alignment loss and an accompanying alignment module. These additions work synergistically with Mask Grounding. With all these techniques, our comprehensive approach culminates in MagNet Mask-grounded Network), an architecture that significantly outperforms prior arts on three key benchmarks (RefCOCO, RefCOCO+ and G-Ref), demonstrating our method's effectiveness in addressing current limitations of RIS algorithms. Our code and pre-trained weights will be released.
GSVA: Generalized Segmentation via Multimodal Large Language Models
Dec 15, 2023



Generalized Referring Expression Segmentation (GRES) extends the scope of classic RES to referring to multiple objects in one expression or identifying the empty targets absent in the image. GRES poses challenges in modeling the complex spatial relationships of the instances in the image and identifying non-existing referents. Recently, Multimodal Large Language Models (MLLMs) have shown tremendous progress in these complicated vision-language tasks. Connecting Large Language Models (LLMs) and vision models, MLLMs are proficient in understanding contexts with visual inputs. Among them, LISA, as a representative, adopts a special [SEG] token to prompt a segmentation mask decoder, e.g., SAM, to enable MLLMs in the RES task. However, existing solutions to of GRES remain unsatisfactory since current segmentation MLLMs cannot properly handle the cases where users might reference multiple subjects in a singular prompt or provide descriptions incongruent with any image target. In this paper, we propose Generalized Segmentation Vision Assistant (GSVA) to address this gap. Specifically, GSVA reuses the [SEG] token to prompt the segmentation model towards supporting multiple mask references simultaneously and innovatively learns to generate a [REJ] token to reject the null targets explicitly. Experiments validate GSVA's efficacy in resolving the GRES issue, marking a notable enhancement and setting a new record on the GRES benchmark gRefCOCO dataset. GSVA also proves effective across various classic referring expression segmentation and comprehension tasks.
Smooth Diffusion: Crafting Smooth Latent Spaces in Diffusion Models
Dec 07, 2023



Recently, diffusion models have made remarkable progress in text-to-image (T2I) generation, synthesizing images with high fidelity and diverse contents. Despite this advancement, latent space smoothness within diffusion models remains largely unexplored. Smooth latent spaces ensure that a perturbation on an input latent corresponds to a steady change in the output image. This property proves beneficial in downstream tasks, including image interpolation, inversion, and editing. In this work, we expose the non-smoothness of diffusion latent spaces by observing noticeable visual fluctuations resulting from minor latent variations. To tackle this issue, we propose Smooth Diffusion, a new category of diffusion models that can be simultaneously high-performing and smooth. Specifically, we introduce Step-wise Variation Regularization to enforce the proportion between the variations of an arbitrary input latent and that of the output image is a constant at any diffusion training step. In addition, we devise an interpolation standard deviation (ISTD) metric to effectively assess the latent space smoothness of a diffusion model. Extensive quantitative and qualitative experiments demonstrate that Smooth Diffusion stands out as a more desirable solution not only in T2I generation but also across various downstream tasks. Smooth Diffusion is implemented as a plug-and-play Smooth-LoRA to work with various community models. Code is available at https://github.com/SHI-Labs/Smooth-Diffusion.
Augmenting Unsupervised Reinforcement Learning with Self-Reference
Nov 16, 2023



Humans possess the ability to draw on past experiences explicitly when learning new tasks and applying them accordingly. We believe this capacity for self-referencing is especially advantageous for reinforcement learning agents in the unsupervised pretrain-then-finetune setting. During pretraining, an agent's past experiences can be explicitly utilized to mitigate the nonstationarity of intrinsic rewards. In the finetuning phase, referencing historical trajectories prevents the unlearning of valuable exploratory behaviors. Motivated by these benefits, we propose the Self-Reference (SR) approach, an add-on module explicitly designed to leverage historical information and enhance agent performance within the pretrain-finetune paradigm. Our approach achieves state-of-the-art results in terms of Interquartile Mean (IQM) performance and Optimality Gap reduction on the Unsupervised Reinforcement Learning Benchmark for model-free methods, recording an 86% IQM and a 16% Optimality Gap. Additionally, it improves current algorithms by up to 17% IQM and reduces the Optimality Gap by 31%. Beyond performance enhancement, the Self-Reference add-on also increases sample efficiency, a crucial attribute for real-world applications.