 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusing Attention for One-stage Lane Topology Understanding
Jul 23, 2025Understanding lane toplogy relationships accurately is critical for safe autonomous driving. However, existing two-stage methods suffer from inefficiencies due to error propagations and increased computational overheads. To address these challenges, we propose a one-stage architecture that simultaneously predicts traffic elements, lane centerlines and topology relationship, improving both the accuracy and inference speed of lane topology understanding for autonomous driving. Our key innovation lies in reusing intermediate attention resources within distinct transformer decoders. This approach effectively leverages the inherent relational knowledge within the element detection module to enable the modeling of topology relationships among traffic elements and lanes without requiring additional computationally expensive graph networks. Furthermore, we are the first to demonstrate that knowledge can be distilled from models that utilize standard definition (SD) maps to those operates without using SD maps, enabling superior performance even in the absence of SD maps. Extensive experiments on the OpenLane-V2 dataset show that our approach outperforms baseline methods in both accuracy and efficiency, achieving superior results in lane detection, traffic element identification, and topology reasoning. Our code is available at https://github.com/Yang-Li-2000/one-stage.git.
Chameleon: Fast-slow Neuro-symbolic Lane Topology Extraction
Mar 10, 2025Lane topology extraction involves detecting lanes and traffic elements and determining their relationships, a key perception task for mapless autonomous driving. This task requires complex reasoning, such as determining whether it is possible to turn left into a specific lane. To address this challenge, we introduce neuro-symbolic methods powered by vision-language foundation models (VLMs). Existing approaches have notable limitations: (1) Dense visual prompting with VLMs can achieve strong performance but is costly in terms of both financial resources and carbon footprint, making it impractical for robotics applications. (2) Neuro-symbolic reasoning methods for 3D scene understanding fail to integrate visual inputs when synthesizing programs, making them ineffective in handling complex corner cases. To this end, we propose a fast-slow neuro-symbolic lane topology extraction algorithm, named Chameleon, which alternates between a fast system that directly reasons over detected instances using synthesized programs and a slow system that utilizes a VLM with a chain-of-thought design to handle corner cases. Chameleon leverages the strengths of both approaches, providing an affordable solution while maintaining high performance. We evaluate the method on the OpenLane-V2 dataset, showing consistent improvements across various baseline detectors. Our code, data, and models are publicly available at https://github.com/XR-Lee/neural-symbolic
Exploring contextual modeling with linear complexity for point cloud segmentation
Oct 28, 2024



Point cloud segmentation is an important topic in 3D understanding that has traditionally has been tackled using either the CNN or Transformer. Recently, Mamba has emerged as a promising alternative, offering efficient long-range contextual modeling capabilities without the quadratic complexity associated with Transformer's attention mechanisms. However, despite Mamba's potential, early efforts have all failed to achieve better performance than the best CNN-based and Transformer-based methods. In this work, we address this challenge by identifying the key components of an effective and efficient point cloud segmentation architecture. Specifically, we show that: 1) Spatial locality and robust contextual understanding are critical for strong performance, and 2) Mamba features linear computational complexity, offering superior data and inference efficiency compared to Transformers, while still being capable of delivering strong contextual understanding. Additionally, we further enhance the standard Mamba specifically for point cloud segmentation by identifying its two key shortcomings. First, the enforced causality in the original Mamba is unsuitable for processing point clouds that have no such dependencies. Second, its unidirectional scanning strategy imposes a directional bias, hampering its ability to capture the full context of unordered point clouds in a single pass. To address these issues, we carefully remove the causal convolutions and introduce a novel Strided Bidirectional SSM to enhance the model's capability to capture spatial relationships. Our efforts culminate in the development of a novel architecture named MEEPO, which effectively integrates the strengths of CNN and Mamba. MEEPO surpasses the previous state-of-the-art method, PTv3, by up to +0.8 mIoU on multiple key benchmark datasets, while being 42.1% faster and 5.53x more memory efficient.
Semantic Refocused Tuning for Open-Vocabulary Panoptic Segmentation
Sep 24, 2024



Open-vocabulary panoptic segmentation is an emerging task aiming to accurately segment the image into semantically meaningful masks based on a set of texts. Despite existing efforts, it remains challenging to develop a high-performing method that generalizes effectively across new domains and requires minimal training resources. Our in-depth analysis of current methods reveals a crucial insight: mask classification is the main performance bottleneck for open-vocab. panoptic segmentation. Based on this, we propose Semantic Refocused Tuning (SMART), a novel framework that greatly enhances open-vocab. panoptic segmentation by improving mask classification through two key innovations. First, SMART adopts a multimodal Semantic-guided Mask Attention mechanism that injects task-awareness into the regional information extraction process. This enables the model to capture task-specific and contextually relevant information for more effective mask classification. Second, it incorporates Query Projection Tuning, which strategically fine-tunes the query projection layers within the Vision Language Model (VLM) used for mask classification. This adjustment allows the model to adapt the image focus of mask tokens to new distributions with minimal training resources, while preserving the VLM's pre-trained knowledge. Extensive ablation studies confirm the superiority of our approach. Notably, SMART sets new state-of-the-art results, demonstrating improvements of up to +1.3 PQ and +5.4 mIoU across representative benchmarks, while reducing training costs by nearly 10x compared to the previous best method. Our code and data will be released.
GOPT: Generalizable Online 3D Bin Packing via Transformer-based Deep Reinforcement Learning
Sep 09, 2024



Robotic object packing has broad practical applications in the logistics and automation industry, often formulated by researchers as the online 3D Bin Packing Problem (3D-BPP). However, existing DRL-based methods primarily focus on enhancing performance in limited packing environments while neglecting the ability to generalize across multiple environments characterized by different bin dimensions. To this end, we propose GOPT, a generalizable online 3D Bin Packing approach via Transformer-based deep reinforcement learning (DRL). First, we design a Placement Generator module to yield finite subspaces as placement candidates and the representation of the bin. Second, we propose a Packing Transformer, which fuses the features of the items and bin, to identify the spatial correlation between the item to be packed and available sub-spaces within the bin. Coupling these two components enables GOPT's ability to perform inference on bins of varying dimensions. We conduct extensive experiments and demonstrate that GOPT not only achieves superior performance against the baselines, but also exhibits excellent generalization capabilities. Furthermore, the deployment with a robot showcases the practical applicability of our method in the real world. The source code will be publicly available at https://github.com/Xiong5Heng/GOPT.
Mask Grounding for Referring Image Segmentation
Dec 19, 2023


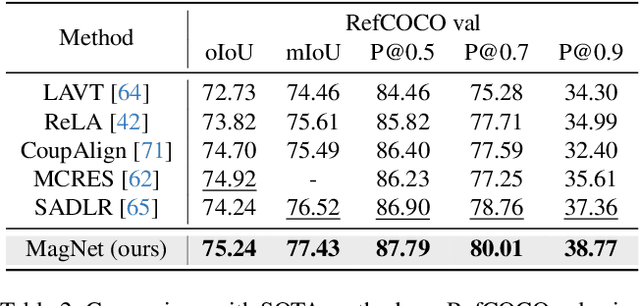
Referring Image Segmentation (RIS) is a challenging task that requires an algorithm to segment objects referred by free-form language expressions. Despite significant progress in recent years, most state-of-the-art (SOTA) methods still suffer from considerable language-image modality gap at the pixel and word level. These methods generally 1) rely on sentence-level language features for language-image alignment and 2) lack explicit training supervision for fine-grained visual grounding. Consequently, they exhibit weak object-level correspondence between visual and language features. Without well-grounded features, prior methods struggle to understand complex expressions that require strong reasoning over relationships among multiple objects, especially when dealing with rarely used or ambiguous clauses. To tackle this challenge, we introduce a novel Mask Grounding auxiliary task that significantly improves visual grounding within language features, by explicitly teaching the model to learn fine-grained correspondence between masked textual tokens and their matching visual objects. Mask Grounding can be directly used on prior RIS methods and consistently bring improvements. Furthermore, to holistically address the modality gap, we also design a cross-modal alignment loss and an accompanying alignment module. These additions work synergistically with Mask Grounding. With all these techniques, our comprehensive approach culminates in MagNet Mask-grounded Network), an architecture that significantly outperforms prior arts on three key benchmarks (RefCOCO, RefCOCO+ and G-Ref), demonstrating our method's effectiveness in addressing current limitations of RIS algorithms. Our code and pre-trained weights will be released.
P2O-Calib: Camera-LiDAR Calibration Using Point-Pair Spatial Occlusion Relationship
Nov 04, 2023The accurate and robust calibration result of sensors is considered as an important building block to the follow-up research in the autonomous driving and robotics domain. The current works involving extrinsic calibration between 3D LiDARs and monocular cameras mainly focus on target-based and target-less methods. The target-based methods are often utilized offline because of restrictions, such as additional target design and target placement limits. The current target-less methods suffer from feature indeterminacy and feature mismatching in various environments. To alleviate these limitations, we propose a novel target-less calibration approach which is based on the 2D-3D edge point extraction using the occlusion relationship in 3D space. Based on the extracted 2D-3D point pairs, we further propose an occlusion-guided point-matching method that improves the calibration accuracy and reduces computation costs. To validate the effectiveness of our approach, we evaluate the method performance qualitatively and quantitatively on real images from the KITTI dataset. The results demonstrate that our method outperforms the existing target-less methods and achieves low error and high robustness that can contribute to the practical applications relying on high-quality Camera-LiDAR calibration.
* Accepted to IROS 2023. Presentation page: https://events.infovaya.com/presentation?id=103943
Pixel-Pair Occlusion Relationship Map(P2ORM): Formulation, Inference & Application
Jul 23, 2020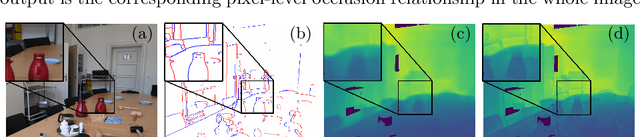
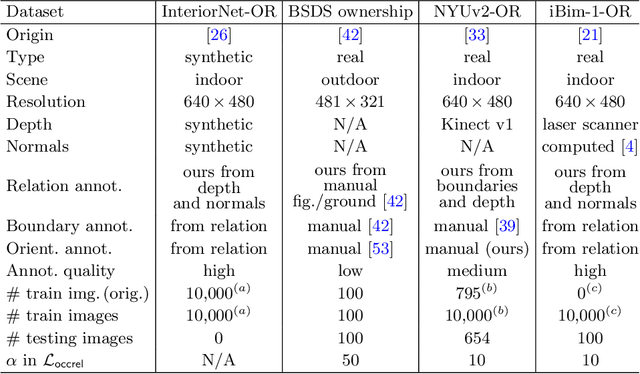
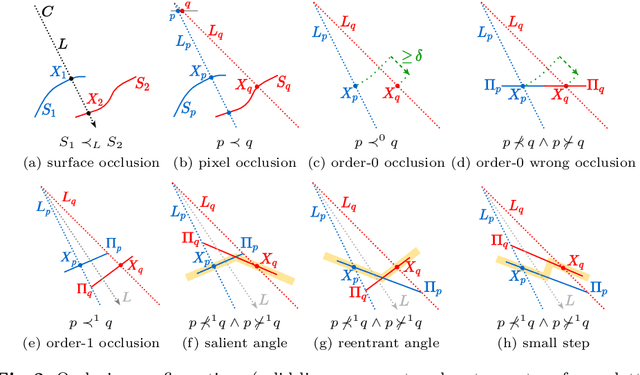
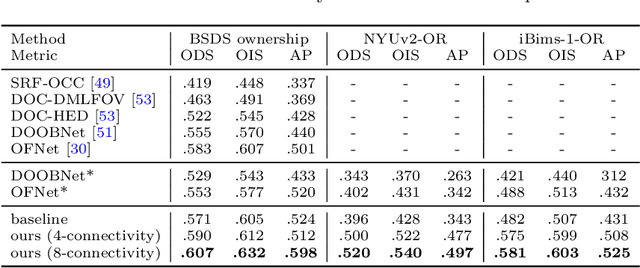
We formalize concepts around geometric occlusion in 2D images (i.e., ignoring semantics), and propose a novel unified formulation of both occlusion boundaries and occlusion orientations via a pixel-pair occlusion relation. The former provides a way to generate large-scale accurate occlusion datasets while, based on the latter, we propose a novel method for task-independent pixel-level occlusion relationship estimation from single images. Experiments on a variety of datasets demonstrate that our method outperforms existing ones on this task. To further illustrate the value of our formulation, we also propose a new depth map refinement method that consistently improve the performance of state-of-the-art monocular depth estimation methods. Our code and data are available at http://imagine.enpc.fr/~qiux/P2ORM/.
Pose from Shape: Deep Pose Estimation for Arbitrary 3D Objects
Jun 12, 2019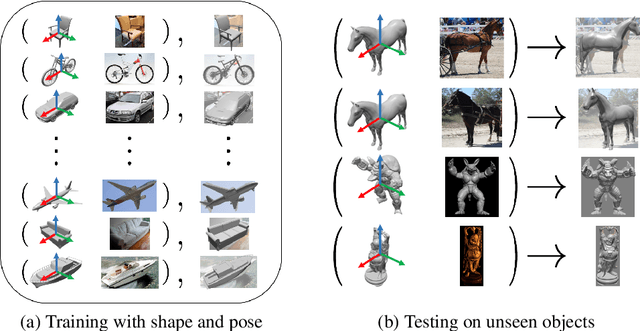
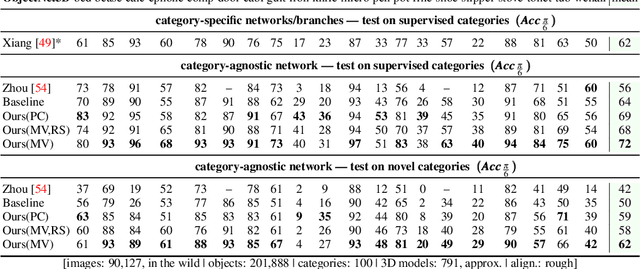
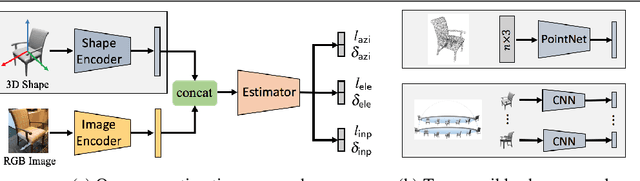
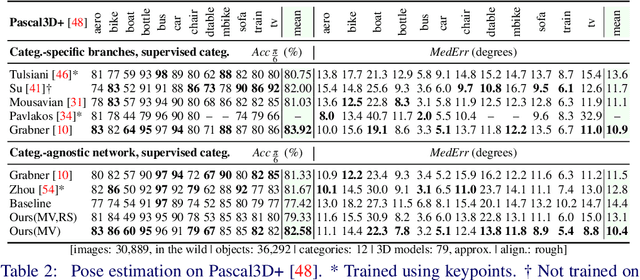
Most deep pose estimation methods need to be trained for specific object instances or categories. In this work we propose a completely generic deep pose estimation approach, which does not require the network to have been trained on relevant categories, nor objects in a category to have a canonical pose. We believe this is a crucial step to design robotic systems that can interact with new objects in the wild not belonging to a predefined category. Our main insight is to dynamically condition pose estimation with a representation of the 3D shape of the target object. More precisely, we train a Convolutional Neural Network that takes as input both a test image and a 3D model, and outputs the relative 3D pose of the object in the input image with respect to the 3D model. We demonstrate that our method boosts performances for supervised category pose estimation on standard benchmarks, namely Pascal3D+, ObjectNet3D and Pix3D, on which we provide results superior to the state of the art. More importantly, we show that our network trained on everyday man-made objects from ShapeNet generalizes without any additional training to completely new types of 3D objects by providing results on the LINEMOD dataset as well as on natural entities such as animals from ImageNet.