 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model for Science: A Study on P vs. NP
Sep 11, 2023



In this work, we use large language models (LLMs) to augment and accelerate research on the P versus NP problem, one of the most important open problems in theoretical computer science and mathematics. Specifically, we propose Socratic reasoning, a general framework that promotes in-depth thinking with LLMs for complex problem-solving. Socratic reasoning encourages LLMs to recursively discover, solve, and integrate problems while facilitating self-evaluation and refinement. Our pilot study on the P vs. NP problem shows that GPT-4 successfully produces a proof schema and engages in rigorous reasoning throughout 97 dialogue turns, concluding "P $\neq$ NP", which is in alignment with (Xu and Zhou, 2023). The investigation uncovers novel insights within the extensive solution space of LLMs, shedding light on LLM for Science.
WavMark: Watermarking for Audio Generation
Aug 24, 2023



Recent breakthroughs in zero-shot voice synthesis have enabled imitating a speaker's voice using just a few seconds of recording while maintaining a high level of realism. Alongside its potential benefits, this powerful technology introduces notable risks, including voice fraud and speaker impersonation. Unlike the conventional approach of solely relying on passive methods for detecting synthetic data, watermarking presents a proactive and robust defence mechanism against these looming risks. This paper introduces an innovative audio watermarking framework that encodes up to 32 bits of watermark within a mere 1-second audio snippet. The watermark is imperceptible to human senses and exhibits strong resilience against various attacks. It can serve as an effective identifier for synthesized voices and holds potential for broader applications in audio copyright protection. Moreover, this framework boasts high flexibility, allowing for the combination of multiple watermark segments to achieve heightened robustness and expanded capacity. Utilizing 10 to 20-second audio as the host, our approach demonstrates an average Bit Error Rate (BER) of 0.48\% across ten common attacks, a remarkable reduction of over 2800\% in BER compared to the state-of-the-art watermarking tool. See https://aka.ms/wavmark for demos of our work.
Retentive Network: A Successor to Transformer for Large Language Models
Aug 09, 2023In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence and attention. Then we propose the retention mechanism for sequence modeling, which supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent. Specifically, the parallel representation allows for training parallelism. The recurrent representation enables low-cost $O(1)$ inference, which improves decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity, where each chunk is encoded parallelly while recurrently summarizing the chunks. Experimental results on language modeling show that RetNet achieves favorable scaling results, parallel training, low-cost deployment, and efficient inference. The intriguing properties make RetNet a strong successor to Transformer for large language models. Code will be available at https://aka.ms/retnet.
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Jul 19, 2023Scaling sequence length has become a critical demand in the era of large language models. However, existing methods struggle with either computational complexity or model expressivity, rendering the maximum sequence length restricted. To address this issue, we introduce LongNet, a Transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences. Specifically, we propose dilated attention, which expands the attentive field exponentially as the distance grows. LongNet has significant advantages: 1) it has a linear computation complexity and a logarithm dependency between any two tokens in a sequence; 2) it can be served as a distributed trainer for extremely long sequences; 3) its dilated attention is a drop-in replacement for standard attention, which can be seamlessly integrated with the existing Transformer-based optimization. Experiments results demonstrate that LongNet yields strong performance on both long-sequence modeling and general language tasks. Our work opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence.
Learning to Retrieve In-Context Examples for Large Language Models
Jul 14, 2023Large language models (LLMs) have demonstrated their ability to learn in-context, allowing them to perform various tasks based on a few input-output examples. However, the effectiveness of in-context learning is heavily reliant on the quality of the selected examples. In this paper, we propose a novel framework to iteratively train dense retrievers that can identify high-quality in-context examples for LLMs. Our framework initially trains a reward model based on LLM feedback to evaluate the quality of candidate examples, followed by knowledge distillation to train a bi-encoder based dense retriever. Our experiments on a suite of 30 tasks demonstrate that our framework significantly enhances in-context learning performance. Furthermore, we show the generalization ability of our framework to unseen tasks during training. An in-depth analysis reveals that our model improves performance by retrieving examples with similar patterns, and the gains are consistent across LLMs of varying sizes.
Unleashing Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration
Jul 14, 2023



Human intelligence thrives on the concept of cognitive synergy, where collaboration and information integration among different cognitive processes yield superior outcomes compared to individual cognitive processes in isolation. Although Large Language Models (LLMs) have demonstrated promising performance as general task-solving agents, they still struggle with tasks that require intensive domain knowledge and complex reasoning. In this work, we propose Solo Performance Prompting (SPP), which transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas. A cognitive synergist refers to an intelligent agent that collaborates with multiple minds, combining their individual strengths and knowledge, to enhance problem-solving and overall performance in complex tasks. By dynamically identifying and simulating different personas based on task inputs, SPP unleashes the potential of cognitive synergy in LLMs. We have discovered that assigning multiple, fine-grained personas in LLMs elicits better problem-solving abilities compared to using a single or fixed number of personas. We evaluate SPP on three challenging tasks: Trivia Creative Writing, Codenames Collaborative, and Logic Grid Puzzle, encompassing both knowledge-intensive and reasoning-intensive types. Unlike previous works, such as Chain-of-Thought, that solely enhance the reasoning abilities in LLMs, SPP effectively elicits internal knowledge acquisition abilities, reduces hallucination, and maintains strong reasoning capabilities. Code, data, and prompts can be found at: https://github.com/MikeWangWZHL/Solo-Performance-Prompting.git.
In-context Autoencoder for Context Compression in a Large Language Model
Jul 13, 2023



We propose the In-context Autoencoder (ICAE) for context compression in a large language model (LLM). The ICAE has two modules: a learnable encoder adapted with LoRA from an LLM for compressing a long context into a limited number of memory slots, and a fixed decoder which is the target LLM that can condition on the memory slots for various purposes. We first pretrain the ICAE using both autoencoding and language modeling objectives on massive text data, enabling it to generate memory slots that accurately and comprehensively represent the original context. Then, we fine-tune the pretrained ICAE on a small amount of instruct data to enhance its interaction with various prompts for producing desirable responses. Our experimental results demonstrate that the ICAE learned with our proposed pretraining and fine-tuning paradigm can effectively produce memory slots with $4\times$ context compression, which can be well conditioned on by the target LLM to respond to various prompts. The promising results demonstrate significant implications of the ICAE for its novel approach to the long context problem and its potential to reduce computation and memory overheads for LLM inference in practice, suggesting further research effort in context management for an LLM. Our code and data will be released shortly.
Kosmos-2: Grounding Multimodal Large Language Models to the World
Jul 13, 2023
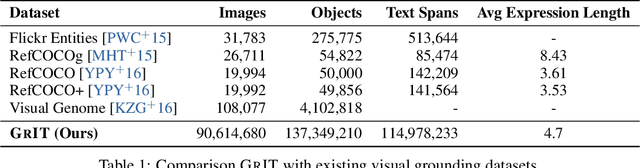

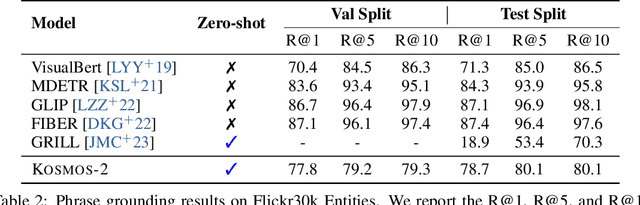
We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Code and pretrained models are available at https://aka.ms/kosmos-2.
Learning to Rank in Generative Retrieval
Jun 27, 2023Generative retrieval is a promising new paradigm in text retrieval that generates identifier strings of relevant passages as the retrieval target. This paradigm leverages powerful generation models and represents a new paradigm distinct from traditional learning-to-rank methods. However, despite its rapid development, current generative retrieval methods are still limited. They typically rely on a heuristic function to transform predicted identifiers into a passage rank list, which creates a gap between the learning objective of generative retrieval and the desired passage ranking target. Moreover, the inherent exposure bias problem of text generation also persists in generative retrieval. To address these issues, we propose a novel framework, called LTRGR, that combines generative retrieval with the classical learning-to-rank paradigm. Our approach involves training an autoregressive model using a passage rank loss, which directly optimizes the autoregressive model toward the optimal passage ranking. This framework only requires an additional training step to enhance current generative retrieval systems and does not add any burden to the inference stage. We conducted experiments on three public datasets, and our results demonstrate that LTRGR achieves state-of-the-art performance among generative retrieval methods, indicating its effectiveness and robustness.
Knowledge Distillation of Large Language Models
Jun 14, 2023Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge from white-box generative LLMs is still under-explored, which becomes more and more important with the prosperity of LLMs. In this work, we propose MiniLLM that distills smaller language models from generative larger language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. Extensive experiments in the instruction-following setting show that the MiniLLM models generate more precise responses with the higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance. Our method is also scalable for different model families with 120M to 13B parameters. We will release our code and model checkpoints at https://aka.ms/MiniLLM.