 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Precise Real-Time Force-Aware Grasping System for Robust Aerial Manipulation
Feb 09, 2026Aerial manipulation requires force-aware capabilities to enable safe and effective grasping and physical interaction. Previous works often rely on heavy, expensive force sensors unsuitable for typical quadrotor platforms, or perform grasping without force feedback, risking damage to fragile objects. To address these limitations, we propose a novel force-aware grasping framework incorporating six low-cost, sensitive skin-like tactile sensors. We introduce a magnetic-based tactile sensing module that provides high-precision three-dimensional force measurements. We eliminate geomagnetic interference through a reference Hall sensor and simplify the calibration process compared to previous work. The proposed framework enables precise force-aware grasping control, allowing safe manipulation of fragile objects and real-time weight measurement of grasped items. The system is validated through comprehensive real-world experiments, including balloon grasping, dynamic load variation tests, and ablation studies, demonstrating its effectiveness in various aerial manipulation scenarios. Our approach achieves fully onboard operation without external motion capture systems, significantly enhancing the practicality of force-sensitive aerial manipulation. The supplementary video is available at: https://www.youtube.com/watch?v=mbcZkrJEf1I.
High-Speed Vision-Based Flight in Clutter with Safety-Shielded Reinforcement Learning
Feb 09, 2026Quadrotor unmanned aerial vehicles (UAVs) are increasingly deployed in complex missions that demand reliable autonomous navigation and robust obstacle avoidance. However, traditional modular pipelines often incur cumulative latency, whereas purely reinforcement learning (RL) approaches typically provide limited formal safety guarantees. To bridge this gap, we propose an end-to-end RL framework augmented with model-based safety mechanisms. We incorporate physical priors in both training and deployment. During training, we design a physics-informed reward structure that provides global navigational guidance. During deployment, we integrate a real-time safety filter that projects the policy outputs onto a provably safe set to enforce strict collision-avoidance constraints. This hybrid architecture reconciles high-speed flight with robust safety assurances. Benchmark evaluations demonstrate that our method outperforms both traditional planners and recent end-to-end obstacle avoidance approaches based on differentiable physics. Extensive experiments demonstrate strong generalization, enabling reliable high-speed navigation in dense clutter and challenging outdoor forest environments at velocities up to 7.5m/s.
A Kinetic-Energy Perspective of Flow Matching
Feb 08, 2026Flow-based generative models can be viewed through a physics lens: sampling transports a particle from noise to data by integrating a time-varying velocity field, and each sample corresponds to a trajectory with its own dynamical effort. Motivated by classical mechanics, we introduce Kinetic Path Energy (KPE), an action-like, per-sample diagnostic that measures the accumulated kinetic effort along an Ordinary Differential Equation (ODE) trajectory. Empirically, KPE exhibits two robust correspondences: (i) higher KPE predicts stronger semantic fidelity; (ii) high-KPE trajectories terminate on low-density manifold frontiers. We further provide theoretical guarantees linking trajectory energy to data density. Paradoxically, this correlation is non-monotonic. At sufficiently high energy, generation can degenerate into memorization. Leveraging the closed-form of empirical flow matching, we show that extreme energies drive trajectories toward near-copies of training examples. This yields a Goldilocks principle and motivates Kinetic Trajectory Shaping (KTS), a training-free two-phase inference strategy that boosts early motion and enforces a late-time soft landing, reducing memorization and improving generation quality across benchmark tasks.
USS-Nav: Unified Spatio-Semantic Scene Graph for Lightweight UAV Zero-Shot Object Navigation
Feb 03, 2026Zero-Shot Object Navigation in unknown environments poses significant challenges for Unmanned Aerial Vehicles (UAVs) due to the conflict between high-level semantic reasoning requirements and limited onboard computational resources. To address this, we present USS-Nav, a lightweight framework that incrementally constructs a Unified Spatio-Semantic scene graph and enables efficient Large Language Model (LLM)-augmented Zero-Shot Object Navigation in unknown environments. Specifically, we introduce an incremental Spatial Connectivity Graph generation method utilizing polyhedral expansion to capture global geometric topology, which is dynamically partitioned into semantic regions via graph clustering. Concurrently, open-vocabulary object semantics are instantiated and anchored to this topology to form a hierarchical environmental representation. Leveraging this hierarchical structure, we present a coarse-to-fine exploration strategy: LLM grounded in the scene graph's semantics to determine global target regions, while a local planner optimizes frontier coverage based on information gain. Experimental results demonstrate that our framework outperforms state-of-the-art methods in terms of computational efficiency and real-time update frequency (15 Hz) on a resource-constrained platform. Furthermore, ablation studies confirm the effectiveness of our framework, showing substantial improvements in Success weighted by Path Length (SPL). The source code will be made publicly available to foster further research.
SPIRIT: Adapting Vision Foundation Models for Unified Single- and Multi-Frame Infrared Small Target Detection
Feb 02, 2026Infrared small target detection (IRSTD) is crucial for surveillance and early-warning, with deployments spanning both single-frame analysis and video-mode tracking. A practical solution should leverage vision foundation models (VFMs) to mitigate infrared data scarcity, while adopting a memory-attention-based temporal propagation framework that unifies single- and multi-frame inference. However, infrared small targets exhibit weak radiometric signals and limited semantic cues, which differ markedly from visible-spectrum imagery. This modality gap makes direct use of semantics-oriented VFMs and appearance-driven cross-frame association unreliable for IRSTD: hierarchical feature aggregation can submerge localized target peaks, and appearance-only memory attention becomes ambiguous, leading to spurious clutter associations. To address these challenges, we propose SPIRIT, a unified and VFM-compatible framework that adapts VFMs to IRSTD via lightweight physics-informed plug-ins. Spatially, PIFR refines features by approximating rank-sparsity decomposition to suppress structured background components and enhance sparse target-like signals. Temporally, PGMA injects history-derived soft spatial priors into memory cross-attention to constrain cross-frame association, enabling robust video detection while naturally reverting to single-frame inference when temporal context is absent. Experiments on multiple IRSTD benchmarks show consistent gains over VFM-based baselines and SOTA performance.
TriphiBot: A Triphibious Robot Combining FOC-based Propulsion with Eccentric Design
Feb 01, 2026Triphibious robots capable of multi-domain motion and cross-domain transitions are promising to handle complex tasks across diverse environments. However, existing designs primarily focus on dual-mode platforms, and some designs suffer from high mechanical complexity or low propulsion efficiency, which limits their application. In this paper, we propose a novel triphibious robot capable of aerial, terrestrial, and aquatic motion, by a minimalist design combining a quadcopter structure with two passive wheels, without extra actuators. To address inefficiency of ground-support motion (moving on land/seabed) for quadcopter based designs, we introduce an eccentric Center of Gravity (CoG) design that inherently aligns thrust with motion, enhancing efficiency without specialized mechanical transformation designs. Furthermore, to address the drastic differences in motion control caused by different fluids (air and water), we develop a unified propulsion system based on Field-Oriented Control (FOC). This method resolves torque matching issues and enables precise, rapid bidirectional thrust across different mediums. Grounded in the perspective of living condition and ground support, we analyse the robot's dynamics and propose a Hybrid Nonlinear Model Predictive Control (HNMPC)-PID control system to ensure stable multi-domain motion and seamless transitions. Experimental results validate the robot's multi-domain motion and cross-mode transition capability, along with the efficiency and adaptability of the proposed propulsion system.
CREPES-X: Hierarchical Bearing-Distance-Inertial Direct Cooperative Relative Pose Estimation System
Dec 31, 2025Relative localization is critical for cooperation in autonomous multi-robot systems. Existing approaches either rely on shared environmental features or inertial assumptions or suffer from non-line-of-sight degradation and outliers in complex environments. Robust and efficient fusion of inter-robot measurements such as bearings, distances, and inertials for tens of robots remains challenging. We present CREPES-X (Cooperative RElative Pose Estimation System with multiple eXtended features), a hierarchical relative localization framework that enhances speed, accuracy, and robustness under challenging conditions, without requiring any global information. CREPES-X starts with a compact hardware design: InfraRed (IR) LEDs, an IR camera, an ultra-wideband module, and an IMU housed in a cube no larger than 6cm on each side. Then CREPES-X implements a two-stage hierarchical estimator to meet different requirements, considering speed, accuracy, and robustness. First, we propose a single-frame relative estimator that provides instant relative poses for multi-robot setups through a closed-form solution and robust bearing outlier rejection. Then a multi-frame relative estimator is designed to offer accurate and robust relative states by exploring IMU pre-integration via robocentric relative kinematics with loosely- and tightly-coupled optimization. Extensive simulations and real-world experiments validate the effectiveness of CREPES-X, showing robustness to up to 90% bearing outliers, proving resilience in challenging conditions, and achieving RMSE of 0.073m and 1.817° in real-world datasets.
Secure and Explainable Fraud Detection in Finance via Hierarchical Multi-source Dataset Distillation
Dec 26, 2025We propose an explainable, privacy-preserving dataset distillation framework for collaborative financial fraud detection. A trained random forest is converted into transparent, axis-aligned rule regions (leaf hyperrectangles), and synthetic transactions are generated by uniformly sampling within each region. This produces a compact, auditable surrogate dataset that preserves local feature interactions without exposing sensitive original records. The rule regions also support explainability: aggregated rule statistics (for example, support and lift) describe global patterns, while assigning each case to its generating region gives concise human-readable rationales and calibrated uncertainty based on tree-vote disagreement. On the IEEE-CIS fraud dataset (590k transactions across three institution-like clusters), distilled datasets reduce data volume by 85% to 93% (often under 15% of the original) while maintaining competitive precision and micro-F1, with only a modest AUC drop. Sharing and augmenting with synthesized data across institutions improves cross-cluster precision, recall, and AUC. Real vs. synthesized structure remains highly similar (over 93% by nearest-neighbor cosine analysis). Membership-inference attacks perform at chance level (about 0.50) when distinguishing training from hold-out records, suggesting low memorization risk. Removing high-uncertainty synthetic points using disagreement scores further boosts AUC (up to 0.687) and improves calibration. Sensitivity tests show weak dependence on the distillation ratio (AUC about 0.641 to 0.645 from 6% to 60%). Overall, tree-region distillation enables trustworthy, deployable fraud analytics with interpretable global rules, per-case rationales with quantified uncertainty, and strong privacy properties suitable for multi-institution settings and regulatory audit.
FAR-AVIO: Fast and Robust Schur-Complement Based Acoustic-Visual-Inertial Fusion Odometry with Sensor Calibration
Dec 23, 2025
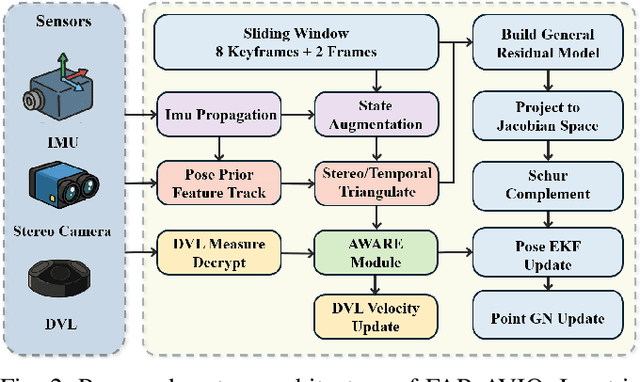
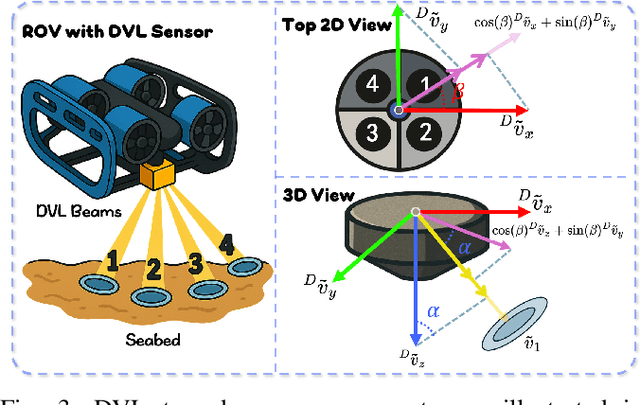
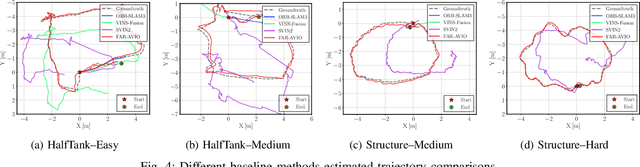
Underwater environments impose severe challenges to visual-inertial odometry systems, as strong light attenuation, marine snow and turbidity, together with weakly exciting motions, degrade inertial observability and cause frequent tracking failures over long-term operation. While tightly coupled acoustic-visual-inertial fusion, typically implemented through an acoustic Doppler Velocity Log (DVL) integrated with visual-inertial measurements, can provide accurate state estimation, the associated graph-based optimization is often computationally prohibitive for real-time deployment on resource-constrained platforms. Here we present FAR-AVIO, a Schur-Complement based, tightly coupled acoustic-visual-inertial odometry framework tailored for underwater robots. FAR-AVIO embeds a Schur complement formulation into an Extended Kalman Filter(EKF), enabling joint pose-landmark optimization for accuracy while maintaining constant-time updates by efficiently marginalizing landmark states. On top of this backbone, we introduce Adaptive Weight Adjustment and Reliability Evaluation(AWARE), an online sensor health module that continuously assesses the reliability of visual, inertial and DVL measurements and adaptively regulates their sigma weights, and we develop an efficient online calibration scheme that jointly estimates DVL-IMU extrinsics, without dedicated calibration manoeuvres. Numerical simulations and real-world underwater experiments consistently show that FAR-AVIO outperforms state-of-the-art underwater SLAM baselines in both localization accuracy and computational efficiency, enabling robust operation on low-power embedded platforms. Our implementation has been released as open source software at https://far-vido.gitbook.io/far-vido-docs.
Flying in Clutter on Monocular RGB by Learning in 3D Radiance Fields with Domain Adaptation
Dec 19, 2025Modern autonomous navigation systems predominantly rely on lidar and depth cameras. However, a fundamental question remains: Can flying robots navigate in clutter using solely monocular RGB images? Given the prohibitive costs of real-world data collection, learning policies in simulation offers a promising path. Yet, deploying such policies directly in the physical world is hindered by the significant sim-to-real perception gap. Thus, we propose a framework that couples the photorealism of 3D Gaussian Splatting (3DGS) environments with Adversarial Domain Adaptation. By training in high-fidelity simulation while explicitly minimizing feature discrepancy, our method ensures the policy relies on domain-invariant cues. Experimental results demonstrate that our policy achieves robust zero-shot transfer to the physical world, enabling safe and agile flight in unstructured environments with varying illumination.