 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kinetic-Energy Perspective of Flow Matching
Feb 08, 2026Flow-based generative models can be viewed through a physics lens: sampling transports a particle from noise to data by integrating a time-varying velocity field, and each sample corresponds to a trajectory with its own dynamical effort. Motivated by classical mechanics, we introduce Kinetic Path Energy (KPE), an action-like, per-sample diagnostic that measures the accumulated kinetic effort along an Ordinary Differential Equation (ODE) trajectory. Empirically, KPE exhibits two robust correspondences: (i) higher KPE predicts stronger semantic fidelity; (ii) high-KPE trajectories terminate on low-density manifold frontiers. We further provide theoretical guarantees linking trajectory energy to data density. Paradoxically, this correlation is non-monotonic. At sufficiently high energy, generation can degenerate into memorization. Leveraging the closed-form of empirical flow matching, we show that extreme energies drive trajectories toward near-copies of training examples. This yields a Goldilocks principle and motivates Kinetic Trajectory Shaping (KTS), a training-free two-phase inference strategy that boosts early motion and enforces a late-time soft landing, reducing memorization and improving generation quality across benchmark tasks.
Evaluation of Local Model-Agnostic Explanations Using Ground Truth
Jun 04, 2021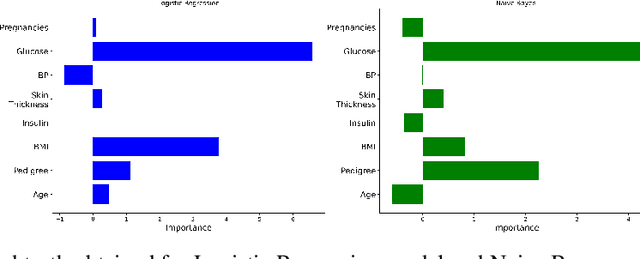

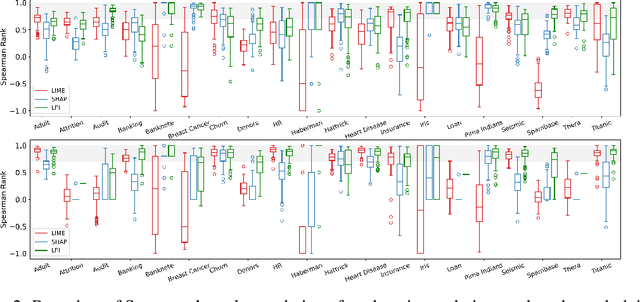
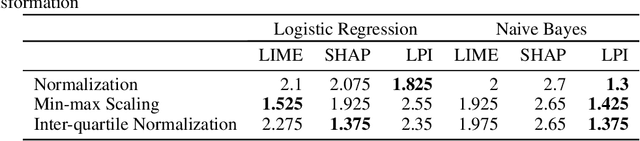
Explanation techniques are commonly evaluated using human-grounded methods, limiting the possibilities for large-scale evaluations and rapid progress in the development of new techniques. We propose a functionally-grounded evaluation procedure for local model-agnostic explanation techniques. In our approach, we generate ground truth for explanations when the black-box model is Logistic Regression and Gaussian Naive Bayes and compare how similar each explanation is to the extracted ground truth. In our empirical study, explanations of Local Interpretable Model-agnostic Explanations (LIME), SHapley Additive exPlanations (SHAP), and Local Permutation Importance (LPI) are compared in terms of how similar they are to the extracted ground truth. In the case of Logistic Regression, we find that the performance of the explanation techniques is highly dependent on the normalization of the data. In contrast, Local Permutation Importance outperforms the other techniques on Naive Bayes, irrespective of normalization. We hope that this work lays the foundation for further research into functionally-grounded evaluation methods for explanation techniques.