 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
May 29, 2025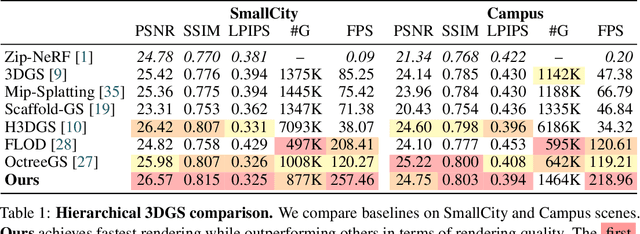
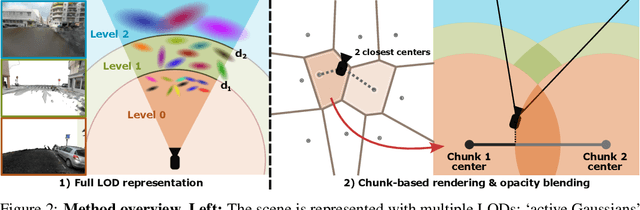
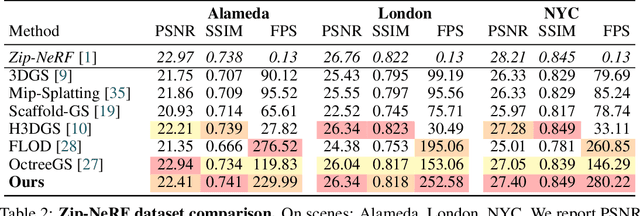
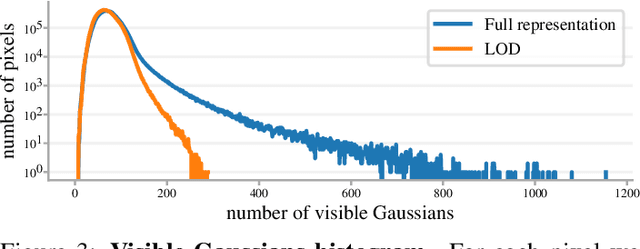
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.
M2SVid: End-to-End Inpainting and Refinement for Monocular-to-Stereo Video Conversion
May 22, 2025We tackle the problem of monocular-to-stereo video conversion and propose a novel architecture for inpainting and refinement of the warped right view obtained by depth-based reprojection of the input left view. We extend the Stable Video Diffusion (SVD) model to utilize the input left video, the warped right video, and the disocclusion masks as conditioning input to generate a high-quality right camera view. In order to effectively exploit information from neighboring frames for inpainting, we modify the attention layers in SVD to compute full attention for discoccluded pixels. Our model is trained to generate the right view video in an end-to-end manner by minimizing image space losses to ensure high-quality generation. Our approach outperforms previous state-of-the-art methods, obtaining an average rank of 1.43 among the 4 compared methods in a user study, while being 6x faster than the second placed method.
One2Any: One-Reference 6D Pose Estimation for Any Object
May 07, 20256D object pose estimation remains challenging for many applications due to dependencies on complete 3D models, multi-view images, or training limited to specific object categories. These requirements make generalization to novel objects difficult for which neither 3D models nor multi-view images may be available. To address this, we propose a novel method One2Any that estimates the relative 6-degrees of freedom (DOF) object pose using only a single reference-single query RGB-D image, without prior knowledge of its 3D model, multi-view data, or category constraints. We treat object pose estimation as an encoding-decoding process, first, we obtain a comprehensive Reference Object Pose Embedding (ROPE) that encodes an object shape, orientation, and texture from a single reference view. Using this embedding, a U-Net-based pose decoding module produces Reference Object Coordinate (ROC) for new views, enabling fast and accurate pose estimation. This simple encoding-decoding framework allows our model to be trained on any pair-wise pose data, enabling large-scale training and demonstrating great scalability. Experiments on multiple benchmark datasets demonstrate that our model generalizes well to novel objects, achieving state-of-the-art accuracy and robustness even rivaling methods that require multi-view or CAD inputs, at a fraction of compute.
* accepted by CVPR 2025
LaRI: Layered Ray Intersections for Single-view 3D Geometric Reasoning
Apr 25, 2025



We present layered ray intersections (LaRI), a new method for unseen geometry reasoning from a single image. Unlike conventional depth estimation that is limited to the visible surface, LaRI models multiple surfaces intersected by the camera rays using layered point maps. Benefiting from the compact and layered representation, LaRI enables complete, efficient, and view-aligned geometric reasoning to unify object- and scene-level tasks. We further propose to predict the ray stopping index, which identifies valid intersecting pixels and layers from LaRI's output. We build a complete training data generation pipeline for synthetic and real-world data, including 3D objects and scenes, with necessary data cleaning steps and coordination between rendering engines. As a generic method, LaRI's performance is validated in two scenarios: It yields comparable object-level results to the recent large generative model using 4% of its training data and 17% of its parameters. Meanwhile, it achieves scene-level occluded geometry reasoning in only one feed-forward.
Prior2Former -- Evidential Modeling of Mask Transformers for Assumption-Free Open-World Panoptic Segmentation
Apr 07, 2025In panoptic segmentation, individual instances must be separated within semantic classes. As state-of-the-art methods rely on a pre-defined set of classes, they struggle with novel categories and out-of-distribution (OOD) data. This is particularly problematic in safety-critical applications, such as autonomous driving, where reliability in unseen scenarios is essential. We address the gap between outstanding benchmark performance and reliability by proposing Prior2Former (P2F), the first approach for segmentation vision transformers rooted in evidential learning. P2F extends the mask vision transformer architecture by incorporating a Beta prior for computing model uncertainty in pixel-wise binary mask assignments. This design enables high-quality uncertainty estimation that effectively detects novel and OOD objects enabling state-of-the-art anomaly instance segmentation and open-world panoptic segmentation. Unlike most segmentation models addressing unknown classes, P2F operates without access to OOD data samples or contrastive training on void (i.e., unlabeled) classes, making it highly applicable in real-world scenarios where such prior information is unavailable. Additionally, P2F can be flexibly applied to anomaly instance and panoptic segmentation. Through comprehensive experiments on the Cityscapes, COCO, SegmentMeIfYouCan, and OoDIS datasets, we demonstrate the state-of-the-art performance of P2F. It achieves the highest ranking in the OoDIS anomaly instance benchmark among methods not using OOD data in any way.
PRISM: Probabilistic Representation for Integrated Shape Modeling and Generation
Apr 06, 2025Despite the advancements in 3D full-shape generation, accurately modeling complex geometries and semantics of shape parts remains a significant challenge, particularly for shapes with varying numbers of parts. Current methods struggle to effectively integrate the contextual and structural information of 3D shapes into their generative processes. We address these limitations with PRISM, a novel compositional approach for 3D shape generation that integrates categorical diffusion models with Statistical Shape Models (SSM) and Gaussian Mixture Models (GMM). Our method employs compositional SSMs to capture part-level geometric variations and uses GMM to represent part semantics in a continuous space. This integration enables both high fidelity and diversity in generated shapes while preserving structural coherence. Through extensive experiments on shape generation and manipulation tasks, we demonstrate that our approach significantly outperforms previous methods in both quality and controllability of part-level operations. Our code will be made publicly available.
Semantic Library Adaptation: LoRA Retrieval and Fusion for Open-Vocabulary Semantic Segmentation
Mar 27, 2025Open-vocabulary semantic segmentation models associate vision and text to label pixels from an undefined set of classes using textual queries, providing versatile performance on novel datasets. However, large shifts between training and test domains degrade their performance, requiring fine-tuning for effective real-world applications. We introduce Semantic Library Adaptation (SemLA), a novel framework for training-free, test-time domain adaptation. SemLA leverages a library of LoRA-based adapters indexed with CLIP embeddings, dynamically merging the most relevant adapters based on proximity to the target domain in the embedding space. This approach constructs an ad-hoc model tailored to each specific input without additional training. Our method scales efficiently, enhances explainability by tracking adapter contributions, and inherently protects data privacy, making it ideal for sensitive applications. Comprehensive experiments on a 20-domain benchmark built over 10 standard datasets demonstrate SemLA's superior adaptability and performance across diverse settings, establishing a new standard in domain adaptation for open-vocabulary semantic segmentation.
Test-Time Visual In-Context Tuning
Mar 27, 2025



Visual in-context learning (VICL), as a new paradigm in computer vision, allows the model to rapidly adapt to various tasks with only a handful of prompts and examples. While effective, the existing VICL paradigm exhibits poor generalizability under distribution shifts. In this work, we propose test-time Visual In-Context Tuning (VICT), a method that can adapt VICL models on the fly with a single test sample. Specifically, we flip the role between the task prompts and the test sample and use a cycle consistency loss to reconstruct the original task prompt output. Our key insight is that a model should be aware of a new test distribution if it can successfully recover the original task prompts. Extensive experiments on six representative vision tasks ranging from high-level visual understanding to low-level image processing, with 15 common corruptions, demonstrate that our VICT can improve the generalizability of VICL to unseen new domains. In addition, we show the potential of applying VICT for unseen tasks at test time. Code: https://github.com/Jiahao000/VICT.
4D Gaussian Splatting SLAM
Mar 20, 2025Simultaneously localizing camera poses and constructing Gaussian radiance fields in dynamic scenes establish a crucial bridge between 2D images and the 4D real world. Instead of removing dynamic objects as distractors and reconstructing only static environments, this paper proposes an efficient architecture that incrementally tracks camera poses and establishes the 4D Gaussian radiance fields in unknown scenarios by using a sequence of RGB-D images. First, by generating motion masks, we obtain static and dynamic priors for each pixel. To eliminate the influence of static scenes and improve the efficiency on learning the motion of dynamic objects, we classify the Gaussian primitives into static and dynamic Gaussian sets, while the sparse control points along with an MLP is utilized to model the transformation fields of the dynamic Gaussians. To more accurately learn the motion of dynamic Gaussians, a novel 2D optical flow map reconstruction algorithm is designed to render optical flows of dynamic objects between neighbor images, which are further used to supervise the 4D Gaussian radiance fields along with traditional photometric and geometric constraints. In experiments, qualitative and quantitative evaluation results show that the proposed method achieves robust tracking and high-quality view synthesis performance in real-world environments.
Omnia de EgoTempo: Benchmarking Temporal Understanding of Multi-Modal LLMs in Egocentric Videos
Mar 17, 2025Understanding fine-grained temporal dynamics is crucial in egocentric videos, where continuous streams capture frequent, close-up interactions with objects. In this work, we bring to light that current egocentric video question-answering datasets often include questions that can be answered using only few frames or commonsense reasoning, without being necessarily grounded in the actual video. Our analysis shows that state-of-the-art Multi-Modal Large Language Models (MLLMs) on these benchmarks achieve remarkably high performance using just text or a single frame as input. To address these limitations, we introduce EgoTempo, a dataset specifically designed to evaluate temporal understanding in the egocentric domain. EgoTempo emphasizes tasks that require integrating information across the entire video, ensuring that models would need to rely on temporal patterns rather than static cues or pre-existing knowledge. Extensive experiments on EgoTempo show that current MLLMs still fall short in temporal reasoning on egocentric videos, and thus we hope EgoTempo will catalyze new research in the field and inspire models that better capture the complexity of temporal dynamics. Dataset and code are available at https://github.com/google-research-datasets/egotempo.git.