 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Graphs: using Scene and Knowledge Graphs for HD-EPIC VQA Challenge
Jun 10, 2025



This report presents SceneNet and KnowledgeNet, our approaches developed for the HD-EPIC VQA Challenge 2025. SceneNet leverages scene graphs generated with a multi-modal large language model (MLLM) to capture fine-grained object interactions, spatial relationships, and temporally grounded events. In parallel, KnowledgeNet incorporates ConceptNet's external commonsense knowledge to introduce high-level semantic connections between entities, enabling reasoning beyond directly observable visual evidence. Each method demonstrates distinct strengths across the seven categories of the HD-EPIC benchmark, and their combination within our framework results in an overall accuracy of 44.21% on the challenge, highlighting its effectiveness for complex egocentric VQA tasks.
Omnia de EgoTempo: Benchmarking Temporal Understanding of Multi-Modal LLMs in Egocentric Videos
Mar 17, 2025



Understanding fine-grained temporal dynamics is crucial in egocentric videos, where continuous streams capture frequent, close-up interactions with objects. In this work, we bring to light that current egocentric video question-answering datasets often include questions that can be answered using only few frames or commonsense reasoning, without being necessarily grounded in the actual video. Our analysis shows that state-of-the-art Multi-Modal Large Language Models (MLLMs) on these benchmarks achieve remarkably high performance using just text or a single frame as input. To address these limitations, we introduce EgoTempo, a dataset specifically designed to evaluate temporal understanding in the egocentric domain. EgoTempo emphasizes tasks that require integrating information across the entire video, ensuring that models would need to rely on temporal patterns rather than static cues or pre-existing knowledge. Extensive experiments on EgoTempo show that current MLLMs still fall short in temporal reasoning on egocentric videos, and thus we hope EgoTempo will catalyze new research in the field and inspire models that better capture the complexity of temporal dynamics. Dataset and code are available at https://github.com/google-research-datasets/egotempo.git.
Spatial Cognition from Egocentric Video: Out of Sight, Not Out of Mind
Apr 07, 2024



As humans move around, performing their daily tasks, they are able to recall where they have positioned objects in their environment, even if these objects are currently out of sight. In this paper, we aim to mimic this spatial cognition ability. We thus formulate the task of Out of Sight, Not Out of Mind - 3D tracking active objects using observations captured through an egocentric camera. We introduce Lift, Match and Keep (LMK), a method which lifts partial 2D observations to 3D world coordinates, matches them over time using visual appearance, 3D location and interactions to form object tracks, and keeps these object tracks even when they go out-of-view of the camera - hence keeping in mind what is out of sight. We test LMK on 100 long videos from EPIC-KITCHENS. Our results demonstrate that spatial cognition is critical for correctly locating objects over short and long time scales. E.g., for one long egocentric video, we estimate the 3D location of 50 active objects. Of these, 60% can be correctly positioned in 3D after 2 minutes of leaving the camera view.
An Outlook into the Future of Egocentric Vision
Aug 14, 2023



What will the future be? We wonder! In this survey, we explore the gap between current research in egocentric vision and the ever-anticipated future, where wearable computing, with outward facing cameras and digital overlays, is expected to be integrated in our every day lives. To understand this gap, the article starts by envisaging the future through character-based stories, showcasing through examples the limitations of current technology. We then provide a mapping between this future and previously defined research tasks. For each task, we survey its seminal works, current state-of-the-art methodologies and available datasets, then reflect on shortcomings that limit its applicability to future research. Note that this survey focuses on software models for egocentric vision, independent of any specific hardware. The paper concludes with recommendations for areas of immediate explorations so as to unlock our path to the future always-on, personalised and life-enhancing egocentric vision.
EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge: Mixed Sequences Prediction
Jul 24, 2023



This report presents the technical details of our approach for the EPIC-Kitchens-100 Unsupervised Domain Adaptation (UDA) Challenge in Action Recognition. Our approach is based on the idea that the order in which actions are performed is similar between the source and target domains. Based on this, we generate a modified sequence by randomly combining actions from the source and target domains. As only unlabelled target data are available under the UDA setting, we use a standard pseudo-labeling strategy for extracting action labels for the target. We then ask the network to predict the resulting action sequence. This allows to integrate information from both domains during training and to achieve better transfer results on target. Additionally, to better incorporate sequence information, we use a language model to filter unlikely sequences. Lastly, we employed a co-occurrence matrix to eliminate unseen combinations of verbs and nouns. Our submission, labeled as 'sshayan', can be found on the leaderboard, where it currently holds the 2nd position for 'verb' and the 4th position for both 'noun' and 'action'.
What can a cook in Italy teach a mechanic in India? Action Recognition Generalisation Over Scenarios and Locations
Jun 14, 2023



We propose and address a new generalisation problem: can a model trained for action recognition successfully classify actions when they are performed within a previously unseen scenario and in a previously unseen location? To answer this question, we introduce the Action Recognition Generalisation Over scenarios and locations dataset (ARGO1M), which contains 1.1M video clips from the large-scale Ego4D dataset, across 10 scenarios and 13 locations. We demonstrate recognition models struggle to generalise over 10 proposed test splits, each of an unseen scenario in an unseen location. We thus propose CIR, a method to represent each video as a Cross-Instance Reconstruction of videos from other domains. Reconstructions are paired with text narrations to guide the learning of a domain generalisable representation. We provide extensive analysis and ablations on ARGO1M that show CIR outperforms prior domain generalisation works on all test splits. Code and data: https://chiaraplizz.github.io/what-can-a-cook/.
E$^2$MOTION: Motion Augmented Event Stream for Egocentric Action Recognition
Dec 07, 2021
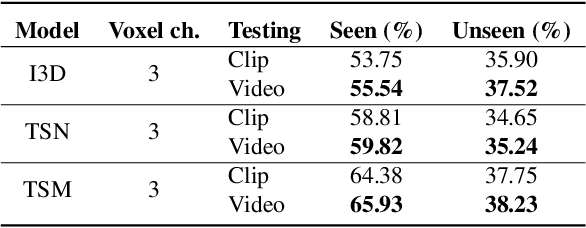


Event cameras are novel bio-inspired sensors, which asynchronously capture pixel-level intensity changes in the form of "events". Due to their sensing mechanism, event cameras have little to no motion blur, a very high temporal resolution and require significantly less power and memory than traditional frame-based cameras. These characteristics make them a perfect fit to several real-world applications such as egocentric action recognition on wearable devices, where fast camera motion and limited power challenge traditional vision sensors. However, the ever-growing field of event-based vision has, to date, overlooked the potential of event cameras in such applications. In this paper, we show that event data is a very valuable modality for egocentric action recognition. To do so, we introduce N-EPIC-Kitchens, the first event-based camera extension of the large-scale EPIC-Kitchens dataset. In this context, we propose two strategies: (i) directly processing event-camera data with traditional video-processing architectures (E$^2$(GO)) and (ii) using event-data to distill optical flow information (E$^2$(GO)MO). On our proposed benchmark, we show that event data provides a comparable performance to RGB and optical flow, yet without any additional flow computation at deploy time, and an improved performance of up to 4% with respect to RGB only information.
Domain Generalization through Audio-Visual Relative Norm Alignment in First Person Action Recognition
Oct 19, 2021



First person action recognition is becoming an increasingly researched area thanks to the rising popularity of wearable cameras. This is bringing to light cross-domain issues that are yet to be addressed in this context. Indeed, the information extracted from learned representations suffers from an intrinsic "environmental bias". This strongly affects the ability to generalize to unseen scenarios, limiting the application of current methods to real settings where labeled data are not available during training. In this work, we introduce the first domain generalization approach for egocentric activity recognition, by proposing a new audio-visual loss, called Relative Norm Alignment loss. It re-balances the contributions from the two modalities during training, over different domains, by aligning their feature norm representations. Our approach leads to strong results in domain generalization on both EPIC-Kitchens-55 and EPIC-Kitchens-100, as demonstrated by extensive experiments, and can be extended to work also on domain adaptation settings with competitive results.
PoliTO-IIT Submission to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition
Jul 01, 2021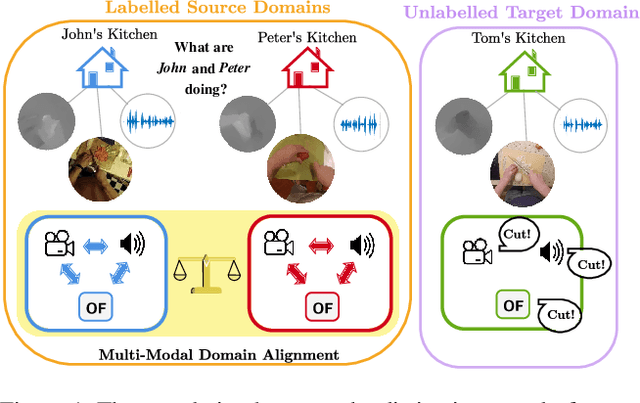


In this report, we describe the technical details of our submission to the EPIC-Kitchens-100 Unsupervised Domain Adaptation (UDA) Challenge in Action Recognition. To tackle the domain-shift which exists under the UDA setting, we first exploited a recent Domain Generalization (DG) technique, called Relative Norm Alignment (RNA). It consists in designing a model able to generalize well to any unseen domain, regardless of the possibility to access target data at training time. Then, in a second phase, we extended the approach to work on unlabelled target data, allowing the model to adapt to the target distribution in an unsupervised fashion. For this purpose, we included in our framework existing UDA algorithms, such as Temporal Attentive Adversarial Adaptation Network (TA3N), jointly with new multi-stream consistency losses, namely Temporal Hard Norm Alignment (T-HNA) and Min-Entropy Consistency (MEC). Our submission (entry 'plnet') is visible on the leaderboard and it achieved the 1st position for 'verb', and the 3rd position for both 'noun' and 'action'.
Cross-Domain First Person Audio-Visual Action Recognition through Relative Norm Alignment
Jun 03, 2021



First person action recognition is an increasingly researched topic because of the growing popularity of wearable cameras. This is bringing to light cross-domain issues that are yet to be addressed in this context. Indeed, the information extracted from learned representations suffers from an intrinsic environmental bias. This strongly affects the ability to generalize to unseen scenarios, limiting the application of current methods in real settings where trimmed labeled data are not available during training. In this work, we propose to leverage over the intrinsic complementary nature of audio-visual signals to learn a representation that works well on data seen during training, while being able to generalize across different domains. To this end, we introduce an audio-visual loss that aligns the contributions from the two modalities by acting on the magnitude of their feature norm representations. This new loss, plugged into a minimal multi-modal action recognition architecture, leads to strong results in cross-domain first person action recognition, as demonstrated by extensive experiments on the popular EPIC-Kitchens dataset.