 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Anything Anywhere:Model-free Object Poses from Arbitrary References
Jun 22, 2026Estimating the 6D pose of unseen objects is a fundamental yet challenging problem for open-world robotics and embodied perception. Model-based methods are accurate but depend on CAD assets or heavy onboarding, while most model-free approaches are still limited to pairwise single-anchor matching and thus fail under occlusion and large viewpoint changes with low query-reference overlap. Therefore, we present PANY, a unified model-free framework that seamlessly supports both RGB and RGB-D inputs, operates on one or sparse pose-free reference views, and generalizes effectively to novel objects. Built on a multi-view transformer geometry backbone, PANY moves beyond pairwise matching by learning view-consistent geometry and cross-view alignment cues that remain stable under wide baselines and limited overlap. When additional unposed assist views are available, PANY aggregates them via pose-graph canonical registration to increase geometric coverage and reinforce the final pose. Extensive experiments show that PANY achieves state-of-the-art performance across multiple benchmarks, substantially outperforming existing model-free methods, improving pose accuracy by +12% on YCB-V and over +20% on LM-O. Furthermore, PANY consistently performs well under both single-reference and sparse-reference settings, demonstrating strong robustness in real-world environments.
Utility-Guided Agent Orchestration for Efficient LLM Tool Use
Mar 20, 2026Tool-using large language model (LLM) agents often face a fundamental tension between answer quality and execution cost. Fixed workflows are stable but inflexible, while free-form multi-step reasoning methods such as ReAct may improve task performance at the expense of excessive tool calls, longer trajectories, higher token consumption, and increased latency. In this paper, we study agent orchestration as an explicit decision problem rather than leaving it entirely to prompt-level behavior. We propose a utility-guided orchestration policy that selects among actions such as respond, retrieve, tool call, verify, and stop by balancing estimated gain, step cost, uncertainty, and redundancy. Our goal is not to claim universally best task performance, but to provide a controllable and analyzable policy framework for studying quality-cost trade-offs in tool-using LLM agents. Experiments across direct answering, threshold control, fixed workflows, ReAct, and several policy variants show that explicit orchestration signals substantially affect agent behavior. Additional analyses on cost definitions, workflow fairness, and redundancy control further demonstrate that lightweight utility design can provide a defensible and practical mechanism for agent control.
Xray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SABlock: Semantic-Aware KV Cache Eviction with Adaptive Compression Block Size
Oct 26, 2025



The growing memory footprint of the Key-Value (KV) cache poses a severe scalability bottleneck for long-context Large Language Model (LLM) inference. While KV cache eviction has emerged as an effective solution by discarding less critical tokens, existing token-, block-, and sentence-level compression methods struggle to balance semantic coherence and memory efficiency. To this end, we introduce SABlock, a \underline{s}emantic-aware KV cache eviction framework with \underline{a}daptive \underline{block} sizes. Specifically, SABlock first performs semantic segmentation to align compression boundaries with linguistic structures, then applies segment-guided token scoring to refine token importance estimation. Finally, for each segment, a budget-driven search strategy adaptively determines the optimal block size that preserves semantic integrity while improving compression efficiency under a given cache budget. Extensive experiments on long-context benchmarks demonstrate that SABlock consistently outperforms state-of-the-art baselines under the same memory budgets. For instance, on Needle-in-a-Haystack (NIAH), SABlock achieves 99.9% retrieval accuracy with only 96 KV entries, nearly matching the performance of the full-cache baseline that retains up to 8K entries. Under a fixed cache budget of 1,024, SABlock further reduces peak memory usage by 46.28% and achieves up to 9.5x faster decoding on a 128K context length.
Enabling Reconfiguration-Communication Overlap for Collective Communication in Optical Networks
Oct 22, 2025

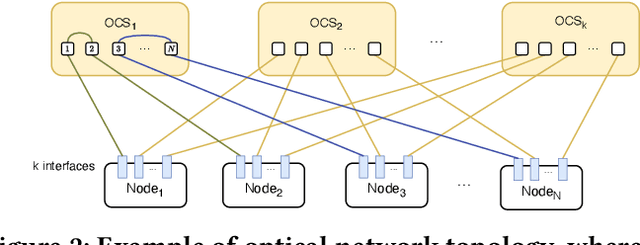

Collective communication (CC) is widely adopted for large-scale distributed machine learning (DML) training workloads. DML's predictable traffic pattern provides a great oppotunity for applying optical network technology. Existing optical interconnects-based CC schemes adopt ``one-shot network reconfiguration'', which provisions static high-capacity topologies for an entire collective operation -- sometimes for a full training iteration. However, this approach faces significant scalability limitations when supporting more complex and efficient CC algorithms required for modern workloads: the ``one-shot'' strategies either demand excessive resource overprovisioning or suffer performance degradation due to rigid resource allocation. To address these challenges, we propose SWOT, a demand-aware optical network framework. SWOT employs ``intra-collective reconfiguration'' and can dynamically align network resources with CC traffic patterns. SWOT incorporates a novel scheduling technique that overlaps optical switch reconfigurations with ongoing transmissions, and improves communication efficiency. SWOT introduce a lightweight collective communication shim that enables coordinated optical network configuration and transmission scheduling while supporting seamless integration with existing CC libraries. Our simulation results demonstrate SWOT's significant performance improvements.
Accelerating Mixture-of-Expert Inference with Adaptive Expert Split Mechanism
Sep 10, 2025



Mixture-of-Experts (MoE) has emerged as a promising architecture for modern large language models (LLMs). However, massive parameters impose heavy GPU memory (i.e., VRAM) demands, hindering the widespread adoption of MoE LLMs. Offloading the expert parameters to CPU RAM offers an effective way to alleviate the VRAM requirements for MoE inference. Existing approaches typically cache a small subset of experts in VRAM and dynamically prefetch experts from RAM during inference, leading to significant degradation in inference speed due to the poor cache hit rate and substantial expert loading latency. In this work, we propose MoEpic, an efficient MoE inference system with a novel expert split mechanism. Specifically, each expert is vertically divided into two segments: top and bottom. MoEpic caches the top segment of hot experts, so that more experts will be stored under the limited VRAM budget, thereby improving the cache hit rate. During each layer's inference, MoEpic predicts and prefetches the activated experts for the next layer. Since the top segments of cached experts are exempt from fetching, the loading time is reduced, which allows efficient transfer-computation overlap. Nevertheless, the performance of MoEpic critically depends on the cache configuration (i.e., each layer's VRAM budget and expert split ratio). To this end, we propose a divide-and-conquer algorithm based on fixed-point iteration for adaptive cache configuration. Extensive experiments on popular MoE LLMs demonstrate that MoEpic can save about half of the GPU cost, while lowering the inference latency by about 37.51%-65.73% compared to the baselines.
Mitigating Catastrophic Forgetting with Adaptive Transformer Block Expansion in Federated Fine-Tuning
Jun 06, 2025


Federated fine-tuning (FedFT) of large language models (LLMs) has emerged as a promising solution for adapting models to distributed data environments while ensuring data privacy. Existing FedFT methods predominantly utilize parameter-efficient fine-tuning (PEFT) techniques to reduce communication and computation overhead. However, they often fail to adequately address the catastrophic forgetting, a critical challenge arising from continual adaptation in distributed environments. The traditional centralized fine-tuning methods, which are not designed for the heterogeneous and privacy-constrained nature of federated environments, struggle to mitigate this issue effectively. Moreover, the challenge is further exacerbated by significant variation in data distributions and device capabilities across clients, which leads to intensified forgetting and degraded model generalization. To tackle these issues, we propose FedBE, a novel FedFT framework that integrates an adaptive transformer block expansion mechanism with a dynamic trainable-block allocation strategy. Specifically, FedBE expands trainable blocks within the model architecture, structurally separating newly learned task-specific knowledge from the original pre-trained representations. Additionally, FedBE dynamically assigns these trainable blocks to clients based on their data distributions and computational capabilities. This enables the framework to better accommodate heterogeneous federated environments and enhances the generalization ability of the model.Extensive experiments show that compared with existing federated fine-tuning methods, FedBE achieves 12-74% higher accuracy retention on general tasks after fine-tuning and a model convergence acceleration ratio of 1.9-3.1x without degrading the accuracy of downstream tasks.
PRISM: Probabilistic Representation for Integrated Shape Modeling and Generation
Apr 06, 2025Despite the advancements in 3D full-shape generation, accurately modeling complex geometries and semantics of shape parts remains a significant challenge, particularly for shapes with varying numbers of parts. Current methods struggle to effectively integrate the contextual and structural information of 3D shapes into their generative processes. We address these limitations with PRISM, a novel compositional approach for 3D shape generation that integrates categorical diffusion models with Statistical Shape Models (SSM) and Gaussian Mixture Models (GMM). Our method employs compositional SSMs to capture part-level geometric variations and uses GMM to represent part semantics in a continuous space. This integration enables both high fidelity and diversity in generated shapes while preserving structural coherence. Through extensive experiments on shape generation and manipulation tasks, we demonstrate that our approach significantly outperforms previous methods in both quality and controllability of part-level operations. Our code will be made publicly available.
Resource-Efficient Federated Fine-Tuning Large Language Models for Heterogeneous Data
Mar 27, 2025



Fine-tuning large language models (LLMs) via federated learning, i.e., FedLLM, has been proposed to adapt LLMs for various downstream applications in a privacy-preserving way. To reduce the fine-tuning costs on resource-constrained devices, FedLoRA is proposed to fine-tune only a small subset of model parameters by integrating low-rank adaptation (LoRA) into FedLLM. However, apart from resource constraints, there is still another critical challenge, i.e., data heterogeneity, severely hindering the implementation of FedLoRA in practical applications. Herein, inspired by the previous group-based federated learning paradigm, we propose a hierarchical FedLoRA framework, termed HierFedLoRA, to address these challenges. Specifically, HierFedLoRA partitions all devices into multiple near-IID groups and adjusts the intra-group aggregation frequency for each group to eliminate the negative effects of non-IID data. Meanwhile, to reduce the computation and communication cost, HierFedLoRA dynamically assigns diverse and suitable fine-tuning depth (i.e., the number of continuous fine-tuning layers from the output) for each group. HierFedLoRA explores jointly optimizing aggregation frequency and depth upon their coupled relationship to better enhance the performance of FedLoRA. Extensive experiments are conducted on a physical platform with 80 commercial devices. The results show that HierFedLoRA improves the final model accuracy by 1.6% to 4.2%, speeding up the fine-tuning process by at least 2.1$\times$, compared to the strong baselines.