 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkRec: Thinking-based recommendation via LLM
May 21, 2025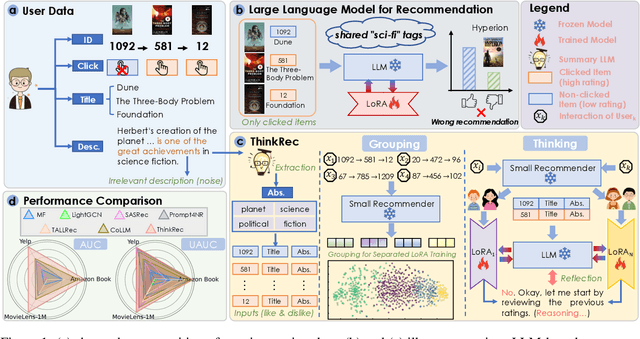
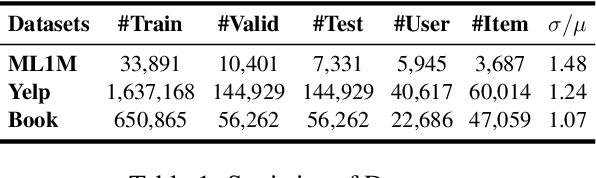
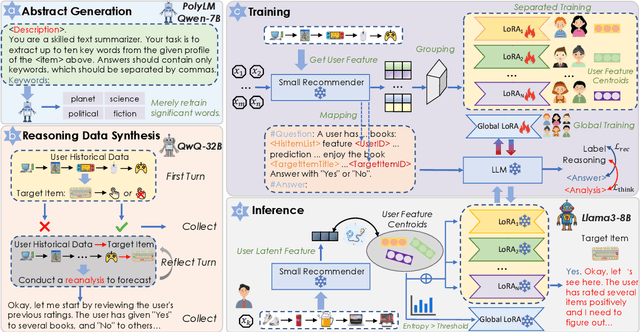

Recent advances in large language models (LLMs) have enabled more semantic-aware recommendations through natural language generation. Existing LLM for recommendation (LLM4Rec) methods mostly operate in a System 1-like manner, relying on superficial features to match similar items based on click history, rather than reasoning through deeper behavioral logic. This often leads to superficial and erroneous recommendations. Motivated by this, we propose ThinkRec, a thinking-based framework that shifts LLM4Rec from System 1 to System 2 (rational system). Technically, ThinkRec introduces a thinking activation mechanism that augments item metadata with keyword summarization and injects synthetic reasoning traces, guiding the model to form interpretable reasoning chains that consist of analyzing interaction histories, identifying user preferences, and making decisions based on target items. On top of this, we propose an instance-wise expert fusion mechanism to reduce the reasoning difficulty. By dynamically assigning weights to expert models based on users' latent features, ThinkRec adapts its reasoning path to individual users, thereby enhancing precision and personalization. Extensive experiments on real-world datasets demonstrate that ThinkRec significantly improves the accuracy and interpretability of recommendations. Our implementations are available in anonymous Github: https://anonymous.4open.science/r/ThinkRec_LLM.
EcoAgent: An Efficient Edge-Cloud Collaborative Multi-Agent Framework for Mobile Automation
May 08, 2025Cloud-based mobile agents powered by (multimodal) large language models ((M)LLMs) offer strong reasoning abilities but suffer from high latency and cost. While fine-tuned (M)SLMs enable edge deployment, they often lose general capabilities and struggle with complex tasks. To address this, we propose EcoAgent, an Edge-Cloud cOllaborative multi-agent framework for mobile automation. EcoAgent features a closed-loop collaboration among a cloud-based Planning Agent and two edge-based agents: the Execution Agent for action execution and the Observation Agent for verifying outcomes. The Observation Agent uses a Pre-Understanding Module to compress screen images into concise text, reducing token usage. In case of failure, the Planning Agent retrieves screen history and replans via a Reflection Module. Experiments on AndroidWorld show that EcoAgent maintains high task success rates while significantly reducing MLLM token consumption, enabling efficient and practical mobile automation.
Responsive DNN Adaptation for Video Analytics against Environment Shift via Hierarchical Mobile-Cloud Collaborations
Apr 30, 2025Mobile video analysis systems often encounter various deploying environments, where environment shifts present greater demands for responsiveness in adaptations of deployed "expert DNN models". Existing model adaptation frameworks primarily operate in a cloud-centric way, exhibiting degraded performance during adaptation and delayed reactions to environment shifts. Instead, this paper proposes MOCHA, a novel framework optimizing the responsiveness of continuous model adaptation through hierarchical collaborations between mobile and cloud resources. Specifically, MOCHA (1) reduces adaptation response delays by performing on-device model reuse and fast fine-tuning before requesting cloud model retrieval and end-to-end retraining; (2) accelerates history expert model retrieval by organizing them into a structured taxonomy utilizing domain semantics analyzed by a cloud foundation model as indices; (3) enables efficient local model reuse by maintaining onboard expert model caches for frequent scenes, which proactively prefetch model weights from the cloud model database. Extensive evaluations with real-world videos on three DNN tasks show MOCHA improves the model accuracy during adaptation by up to 6.8% while saving the response delay and retraining time by up to 35.5x and 3.0x respectively.
Collaborative Learning of On-Device Small Model and Cloud-Based Large Model: Advances and Future Directions
Apr 17, 2025The conventional cloud-based large model learning framework is increasingly constrained by latency, cost, personalization, and privacy concerns. In this survey, we explore an emerging paradigm: collaborative learning between on-device small model and cloud-based large model, which promises low-latency, cost-efficient, and personalized intelligent services while preserving user privacy. We provide a comprehensive review across hardware, system, algorithm, and application layers. At each layer, we summarize key problems and recent advances from both academia and industry. In particular, we categorize collaboration algorithms into data-based, feature-based, and parameter-based frameworks. We also review publicly available datasets and evaluation metrics with user-level or device-level consideration tailored to collaborative learning settings. We further highlight real-world deployments, ranging from recommender systems and mobile livestreaming to personal intelligent assistants. We finally point out open research directions to guide future development in this rapidly evolving field.
Efficient Distributed Retrieval-Augmented Generation for Enhancing Language Model Performance
Apr 16, 2025Small language models (SLMs) support efficient deployments on resource-constrained edge devices, but their limited capacity compromises inference performance. Retrieval-augmented generation (RAG) is a promising solution to enhance model performance by integrating external databases, without requiring intensive on-device model retraining. However, large-scale public databases and user-specific private contextual documents are typically located on the cloud and the device separately, while existing RAG implementations are primarily centralized. To bridge this gap, we propose DRAGON, a distributed RAG framework to enhance on-device SLMs through both general and personal knowledge without the risk of leaking document privacy. Specifically, DRAGON decomposes multi-document RAG into multiple parallel token generation processes performed independently and locally on the cloud and the device, and employs a newly designed Speculative Aggregation, a dual-side speculative algorithm to avoid frequent output synchronization between the cloud and device. A new scheduling algorithm is further introduced to identify the optimal aggregation side based on real-time network conditions. Evaluations on real-world hardware testbed demonstrate a significant performance improvement of DRAGON-up to 1.9x greater gains over standalone SLM compared to the centralized RAG, substantial reduction in per-token latency, and negligible Time to First Token (TTFT) overhead.
FeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Apr 01, 2025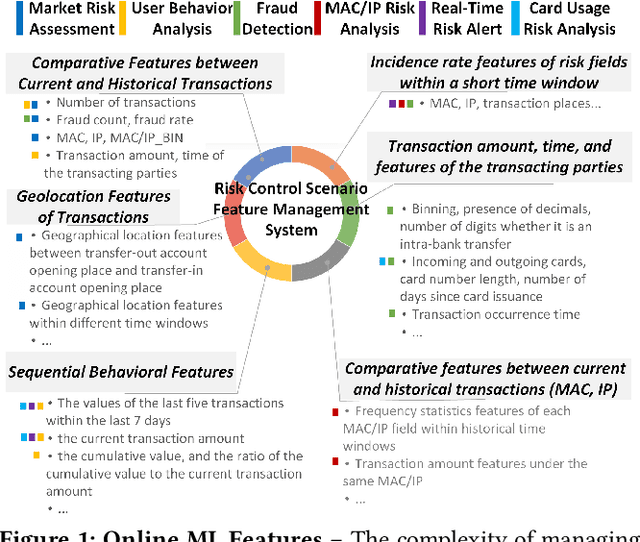
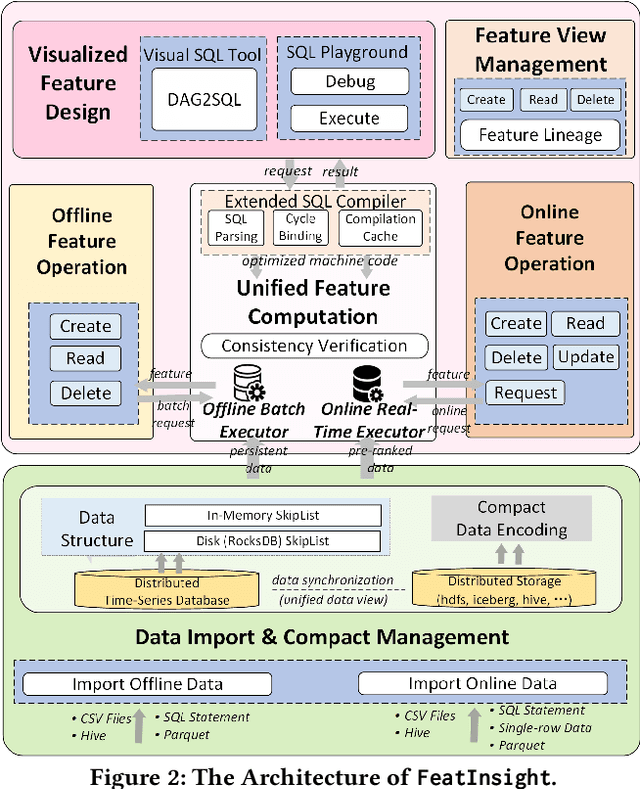
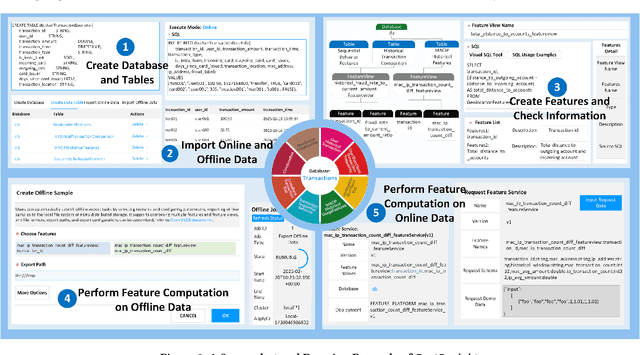
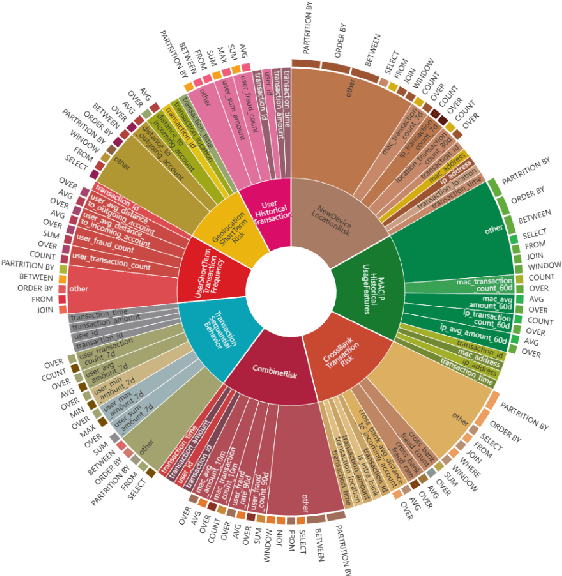
Feature management is essential for many online machine learning applications and can often become the performance bottleneck (e.g., taking up to 70% of the overall latency in sales prediction service). Improper feature configurations (e.g., introducing too many irrelevant features) can severely undermine the model's generalization capabilities. However, managing online ML features is challenging due to (1) large-scale, complex raw data (e.g., the 2018 PHM dataset contains 17 tables and dozens to hundreds of columns), (2) the need for high-performance, consistent computation of interdependent features with complex patterns, and (3) the requirement for rapid updates and deployments to accommodate real-time data changes. In this demo, we present FeatInsight, a system that supports the entire feature lifecycle, including feature design, storage, visualization, computation, verification, and lineage management. FeatInsight (with OpenMLDB as the execution engine) has been deployed in over 100 real-world scenarios on 4Paradigm's Sage Studio platform, handling up to a trillion-dimensional feature space and enabling millisecond-level feature updates. We demonstrate how FeatInsight enhances feature design efficiency (e.g., for online product recommendation) and improve feature computation performance (e.g., for online fraud detection). The code is available at https://github.com/4paradigm/FeatInsight.
Empirical Privacy Variance
Mar 16, 2025We propose the notion of empirical privacy variance and study it in the context of differentially private fine-tuning of language models. Specifically, we show that models calibrated to the same $(\varepsilon, \delta)$-DP guarantee using DP-SGD with different hyperparameter configurations can exhibit significant variations in empirical privacy, which we quantify through the lens of memorization. We investigate the generality of this phenomenon across multiple dimensions and discuss why it is surprising and relevant. Through regression analysis, we examine how individual and composite hyperparameters influence empirical privacy. The results reveal a no-free-lunch trade-off: existing practices of hyperparameter tuning in DP-SGD, which focus on optimizing utility under a fixed privacy budget, often come at the expense of empirical privacy. To address this, we propose refined heuristics for hyperparameter selection that explicitly account for empirical privacy, showing that they are both precise and practically useful. Finally, we take preliminary steps to understand empirical privacy variance. We propose two hypotheses, identify limitations in existing techniques like privacy auditing, and outline open questions for future research.
SharedAssembly: A Data Collection Approach via Shared Tele-Assembly
Mar 15, 2025Assembly is a fundamental skill for robots in both modern manufacturing and service robotics. Existing datasets aim to address the data bottleneck in training general-purpose robot models, falling short of capturing contact-rich assembly tasks. To bridge this gap, we introduce SharedAssembly, a novel bilateral teleoperation approach with shared autonomy for scalable assembly execution and data collection. User studies demonstrate that the proposed approach enhances both success rates and efficiency, achieving a 97.0% success rate across various sub-millimeter-level assembly tasks. Notably, novice and intermediate users achieve performance comparable to experts using baseline teleoperation methods, significantly enhancing large-scale data collection.
CFNet: Optimizing Remote Sensing Change Detection through Content-Aware Enhancement
Mar 11, 2025Change detection is a crucial and widely applied task in remote sensing, aimed at identifying and analyzing changes occurring in the same geographical area over time. Due to variability in acquisition conditions, bi-temporal remote sensing images often exhibit significant differences in image style. Even with the powerful generalization capabilities of DNNs, these unpredictable style variations between bi-temporal images inevitably affect model's ability to accurately detect changed areas. To address issue above, we propose the Content Focuser Network (CFNet), which takes content-aware strategy as a key insight. CFNet employs EfficientNet-B5 as the backbone for feature extraction. To enhance the model's focus on the content features of images while mitigating the misleading effects of style features, we develop a constraint strategy that prioritizes the content features of bi-temporal images, termed Content-Aware. Furthermore, to enable the model to flexibly focus on changed and unchanged areas according to the requirements of different stages, we design a reweighting module based on the cosine distance between bi-temporal image features, termed Focuser. CFNet achieve outstanding performance across three well-known change detection datasets: CLCD (F1: 81.41%, IoU: 68.65%), LEVIR-CD (F1: 92.18%, IoU: 85.49%), and SYSU-CD (F1: 82.89%, IoU: 70.78%). The code and pretrained models of CFNet are publicly released at https://github.com/wifiBlack/CFNet.
Vision-based 3D Semantic Scene Completion via Capture Dynamic Representations
Mar 08, 2025The vision-based semantic scene completion task aims to predict dense geometric and semantic 3D scene representations from 2D images. However, the presence of dynamic objects in the scene seriously affects the accuracy of the model inferring 3D structures from 2D images. Existing methods simply stack multiple frames of image input to increase dense scene semantic information, but ignore the fact that dynamic objects and non-texture areas violate multi-view consistency and matching reliability. To address these issues, we propose a novel method, CDScene: Vision-based Robust Semantic Scene Completion via Capturing Dynamic Representations. First, we leverage a multimodal large-scale model to extract 2D explicit semantics and align them into 3D space. Second, we exploit the characteristics of monocular and stereo depth to decouple scene information into dynamic and static features. The dynamic features contain structural relationships around dynamic objects, and the static features contain dense contextual spatial information. Finally, we design a dynamic-static adaptive fusion module to effectively extract and aggregate complementary features, achieving robust and accurate semantic scene completion in autonomous driving scenarios. Extensive experimental results on the SemanticKITTI, SSCBench-KITTI360, and SemanticKITTI-C datasets demonstrate the superiority and robustness of CDScene over existing state-of-the-art methods.