 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Time and Space: Decoupled Spatio-Temporal Alignment for Video Grounding
Apr 09, 2026Spatio-Temporal Video Grounding requires jointly localizing target objects across both temporal and spatial dimensions based on natural language queries, posing fundamental challenges for existing Multimodal Large Language Models (MLLMs). We identify two core challenges: \textit{entangled spatio-temporal alignment}, arising from coupling two heterogeneous sub-tasks within the same autoregressive output space, and \textit{dual-domain visual token redundancy}, where target objects exhibit simultaneous temporal and spatial sparsity, rendering the overwhelming majority of visual tokens irrelevant to the grounding query. To address these, we propose \textbf{Bridge-STG}, an end-to-end framework that decouples temporal and spatial localization while maintaining semantic coherence. While decoupling is the natural solution to this entanglement, it risks creating a semantic gap between the temporal MLLM and the spatial decoder. Bridge-STG resolves this through two pivotal designs: the \textbf{Spatio-Temporal Semantic Bridging (STSB)} mechanism with Explicit Temporal Alignment (ETA) distills the MLLM's temporal reasoning context into enriched bridging queries as a robust semantic interface; and the \textbf{Query-Guided Spatial Localization (QGSL)} module leverages these queries to drive a purpose-built spatial decoder with multi-layer interactive queries and positive/negative frame sampling, jointly eliminating dual-domain visual token redundancy. Extensive experiments across multiple benchmarks demonstrate that Bridge-STG achieves state-of-the-art performance among MLLM-based methods. Bridge-STG improves average m\_vIoU from $26.4$ to $34.3$ on VidSTG and demonstrates strong cross-task transfer across various fine-grained video understanding tasks under a unified multi-task training regime.
Agentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025



Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
Collaborative Learning of On-Device Small Model and Cloud-Based Large Model: Advances and Future Directions
Apr 17, 2025



The conventional cloud-based large model learning framework is increasingly constrained by latency, cost, personalization, and privacy concerns. In this survey, we explore an emerging paradigm: collaborative learning between on-device small model and cloud-based large model, which promises low-latency, cost-efficient, and personalized intelligent services while preserving user privacy. We provide a comprehensive review across hardware, system, algorithm, and application layers. At each layer, we summarize key problems and recent advances from both academia and industry. In particular, we categorize collaboration algorithms into data-based, feature-based, and parameter-based frameworks. We also review publicly available datasets and evaluation metrics with user-level or device-level consideration tailored to collaborative learning settings. We further highlight real-world deployments, ranging from recommender systems and mobile livestreaming to personal intelligent assistants. We finally point out open research directions to guide future development in this rapidly evolving field.
Incentive Mechanisms for Federated Learning: From Economic and Game Theoretic Perspective
Nov 20, 2021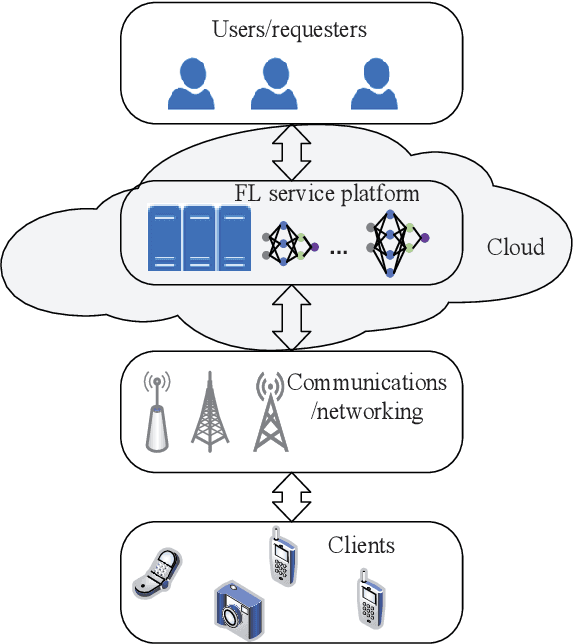
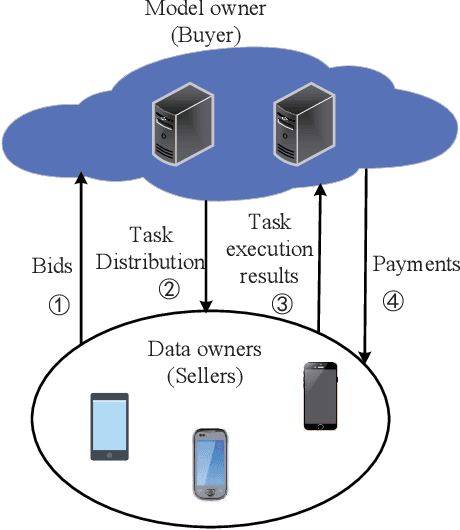
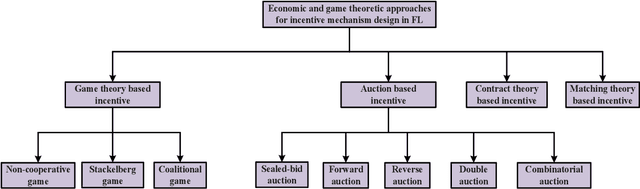
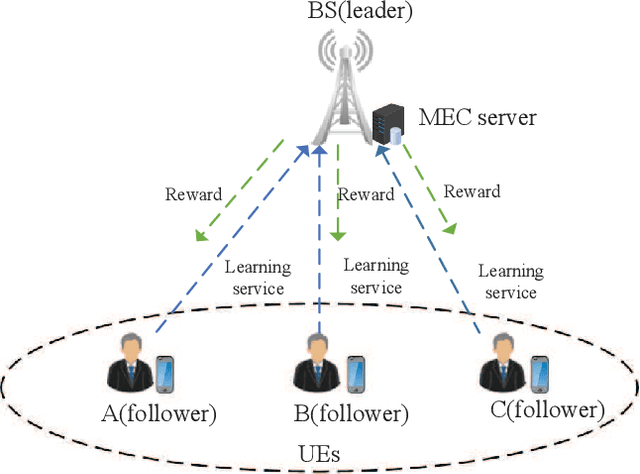
Federated learning (FL) becomes popular and has shown great potentials in training large-scale machine learning (ML) models without exposing the owners' raw data. In FL, the data owners can train ML models based on their local data and only send the model updates rather than raw data to the model owner for aggregation. To improve learning performance in terms of model accuracy and training completion time, it is essential to recruit sufficient participants. Meanwhile, the data owners are rational and may be unwilling to participate in the collaborative learning process due to the resource consumption. To address the issues, there have been various works recently proposed to motivate the data owners to contribute their resources. In this paper, we provide a comprehensive review for the economic and game theoretic approaches proposed in the literature to design various schemes for stimulating data owners to participate in FL training process. In particular, we first present the fundamentals and background of FL, economic theories commonly used in incentive mechanism design. Then, we review applications of game theory and economic approaches applied for incentive mechanisms design of FL. Finally, we highlight some open issues and future research directions concerning incentive mechanism design of FL.