 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
Feb 20, 2024



This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
Taming Mode Collapse in Score Distillation for Text-to-3D Generation
Dec 31, 2023



Despite the remarkable performance of score distillation in text-to-3D generation, such techniques notoriously suffer from view inconsistency issues, also known as "Janus" artifact, where the generated objects fake each view with multiple front faces. Although empirically effective methods have approached this problem via score debiasing or prompt engineering, a more rigorous perspective to explain and tackle this problem remains elusive. In this paper, we reveal that the existing score distillation-based text-to-3D generation frameworks degenerate to maximal likelihood seeking on each view independently and thus suffer from the mode collapse problem, manifesting as the Janus artifact in practice. To tame mode collapse, we improve score distillation by re-establishing in entropy term in the corresponding variational objective, which is applied to the distribution of rendered images. Maximizing the entropy encourages diversity among different views in generated 3D assets, thereby mitigating the Janus problem. Based on this new objective, we derive a new update rule for 3D score distillation, dubbed Entropic Score Distillation (ESD). We theoretically reveal that ESD can be simplified and implemented by just adopting the classifier-free guidance trick upon variational score distillation. Although embarrassingly straightforward, our extensive experiments successfully demonstrate that ESD can be an effective treatment for Janus artifacts in score distillation.
SteinDreamer: Variance Reduction for Text-to-3D Score Distillation via Stein Identity
Dec 31, 2023



Score distillation has emerged as one of the most prevalent approaches for text-to-3D asset synthesis. Essentially, score distillation updates 3D parameters by lifting and back-propagating scores averaged over different views. In this paper, we reveal that the gradient estimation in score distillation is inherent to high variance. Through the lens of variance reduction, the effectiveness of SDS and VSD can be interpreted as applications of various control variates to the Monte Carlo estimator of the distilled score. Motivated by this rethinking and based on Stein's identity, we propose a more general solution to reduce variance for score distillation, termed Stein Score Distillation (SSD). SSD incorporates control variates constructed by Stein identity, allowing for arbitrary baseline functions. This enables us to include flexible guidance priors and network architectures to explicitly optimize for variance reduction. In our experiments, the overall pipeline, dubbed SteinDreamer, is implemented by instantiating the control variate with a monocular depth estimator. The results suggest that SSD can effectively reduce the distillation variance and consistently improve visual quality for both object- and scene-level generation. Moreover, we demonstrate that SteinDreamer achieves faster convergence than existing methods due to more stable gradient updates.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023



Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
Drag View: Generalizable Novel View Synthesis with Unposed Imagery
Oct 05, 2023



We introduce DragView, a novel and interactive framework for generating novel views of unseen scenes. DragView initializes the new view from a single source image, and the rendering is supported by a sparse set of unposed multi-view images, all seamlessly executed within a single feed-forward pass. Our approach begins with users dragging a source view through a local relative coordinate system. Pixel-aligned features are obtained by projecting the sampled 3D points along the target ray onto the source view. We then incorporate a view-dependent modulation layer to effectively handle occlusion during the projection. Additionally, we broaden the epipolar attention mechanism to encompass all source pixels, facilitating the aggregation of initialized coordinate-aligned point features from other unposed views. Finally, we employ another transformer to decode ray features into final pixel intensities. Crucially, our framework does not rely on either 2D prior models or the explicit estimation of camera poses. During testing, DragView showcases the capability to generalize to new scenes unseen during training, also utilizing only unposed support images, enabling the generation of photo-realistic new views characterized by flexible camera trajectories. In our experiments, we conduct a comprehensive comparison of the performance of DragView with recent scene representation networks operating under pose-free conditions, as well as with generalizable NeRFs subject to noisy test camera poses. DragView consistently demonstrates its superior performance in view synthesis quality, while also being more user-friendly. Project page: https://zhiwenfan.github.io/DragView/.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023



Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023



Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
PathFusion: Path-consistent Lidar-Camera Deep Feature Fusion
Dec 12, 2022Fusing camera with LiDAR is a promising technique to improve the accuracy of 3D detection due to the complementary physical properties. While most existing methods focus on fusing camera features directly with raw LiDAR point clouds or shallow 3D features, it is observed that direct deep 3D feature fusion achieves inferior accuracy due to feature misalignment. The misalignment that originates from the feature aggregation across large receptive fields becomes increasingly severe for deep network stages. In this paper, we propose PathFusion to enable path-consistent LiDAR-camera deep feature fusion. PathFusion introduces a path consistency loss between shallow and deep features, which encourages the 2D backbone and its fusion path to transform 2D features in a way that is semantically aligned with the transform of the 3D backbone. We apply PathFusion to the prior-art fusion baseline, Focals Conv, and observe more than 1.2\% mAP improvements on the nuScenes test split consistently with and without testing-time augmentations. Moreover, PathFusion also improves KITTI AP3D (R11) by more than 0.6% on moderate level.
Fast Point Cloud Generation with Straight Flows
Dec 04, 2022



Diffusion models have emerged as a powerful tool for point cloud generation. A key component that drives the impressive performance for generating high-quality samples from noise is iteratively denoise for thousands of steps. While beneficial, the complexity of learning steps has limited its applications to many 3D real-world. To address this limitation, we propose Point Straight Flow (PSF), a model that exhibits impressive performance using one step. Our idea is based on the reformulation of the standard diffusion model, which optimizes the curvy learning trajectory into a straight path. Further, we develop a distillation strategy to shorten the straight path into one step without a performance loss, enabling applications to 3D real-world with latency constraints. We perform evaluations on multiple 3D tasks and find that our PSF performs comparably to the standard diffusion model, outperforming other efficient 3D point cloud generation methods. On real-world applications such as point cloud completion and training-free text-guided generation in a low-latency setup, PSF performs favorably.
Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
Nov 23, 2021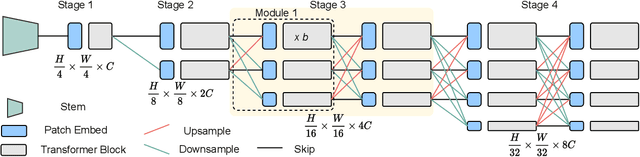

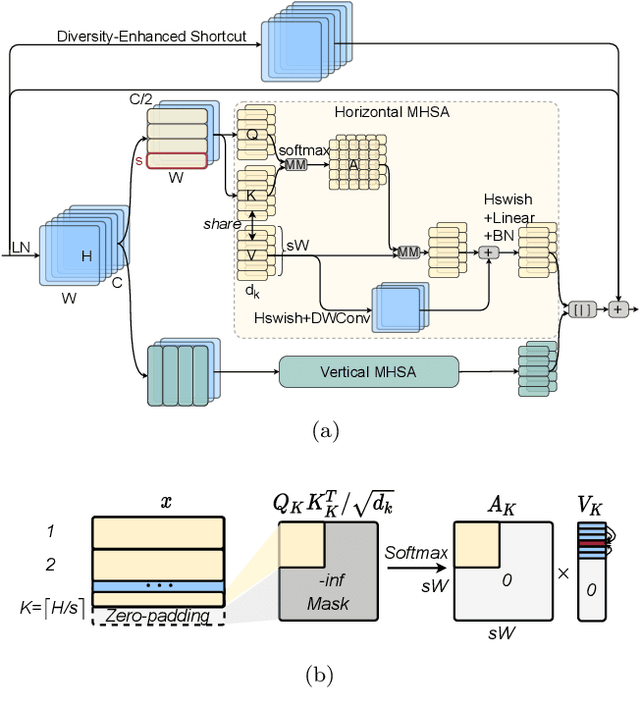
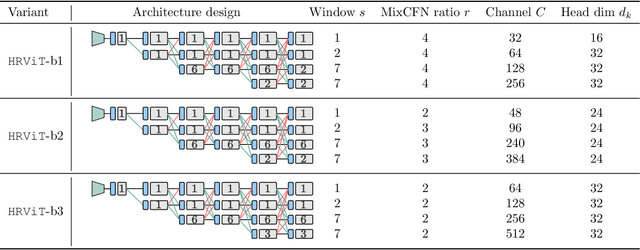
Vision Transformers (ViTs) have emerged with superior performance on computer vision tasks compared to convolutional neural network (CNN)-based models. However, ViTs are mainly designed for image classification that generate single-scale low-resolution representations, which makes dense prediction tasks such as semantic segmentation challenging for ViTs. Therefore, we propose HRViT, which enhances ViTs to learn semantically-rich and spatially-precise multi-scale representations by integrating high-resolution multi-branch architectures with ViTs. We balance the model performance and efficiency of HRViT by various branch-block co-optimization techniques. Specifically, we explore heterogeneous branch designs, reduce the redundancy in linear layers, and augment the attention block with enhanced expressiveness. Those approaches enabled HRViT to push the Pareto frontier of performance and efficiency on semantic segmentation to a new level, as our evaluation results on ADE20K and Cityscapes show. HRViT achieves 50.20% mIoU on ADE20K and 83.16% mIoU on Cityscapes, surpassing state-of-the-art MiT and CSWin backbones with an average of +1.78 mIoU improvement, 28% parameter saving, and 21% FLOPs reduction, demonstrating the potential of HRViT as a strong vision backbone for semantic segmentation.