 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrofitting Multilingual Sentence Embeddings with Abstract Meaning Representation
Oct 18, 2022

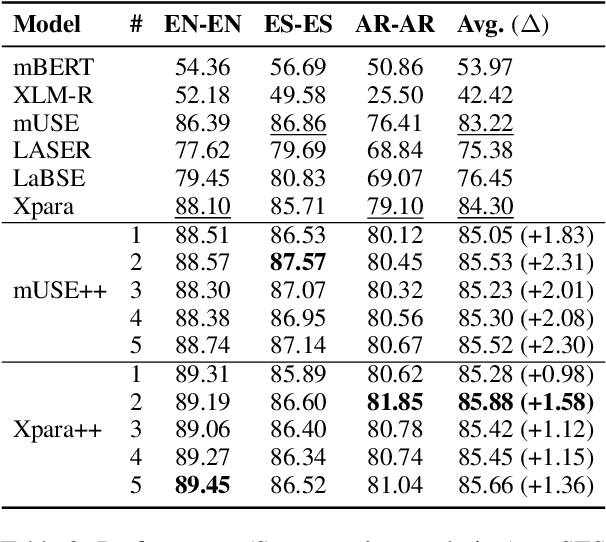
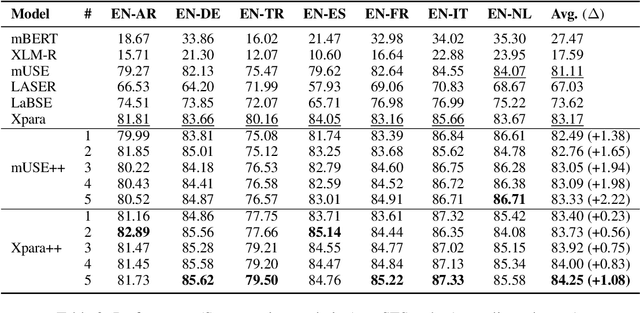
We introduce a new method to improve existing multilingual sentence embeddings with Abstract Meaning Representation (AMR). Compared with the original textual input, AMR is a structured semantic representation that presents the core concepts and relations in a sentence explicitly and unambiguously. It also helps reduce surface variations across different expressions and languages. Unlike most prior work that only evaluates the ability to measure semantic similarity, we present a thorough evaluation of existing multilingual sentence embeddings and our improved versions, which include a collection of five transfer tasks in different downstream applications. Experiment results show that retrofitting multilingual sentence embeddings with AMR leads to better state-of-the-art performance on both semantic textual similarity and transfer tasks. Our codebase and evaluation scripts can be found at \url{https://github.com/jcyk/MSE-AMR}.
Towards In-distribution Compatibility in Out-of-distribution Detection
Aug 29, 2022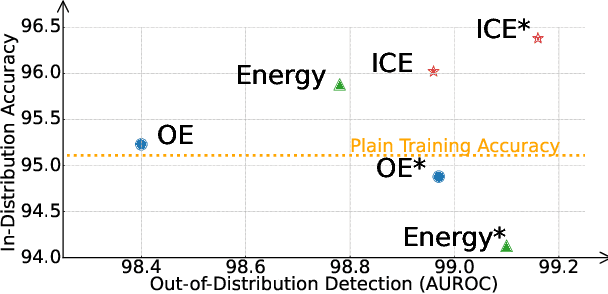
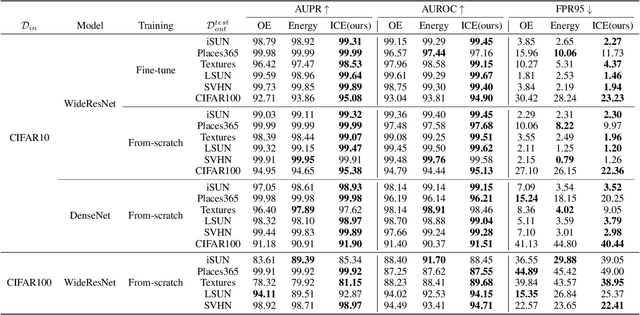
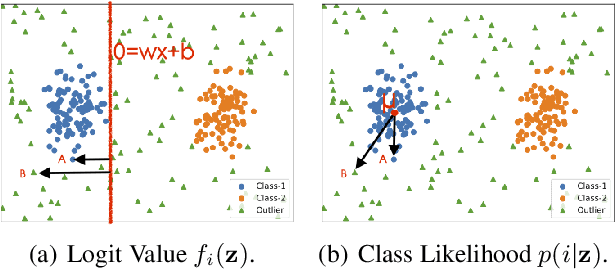
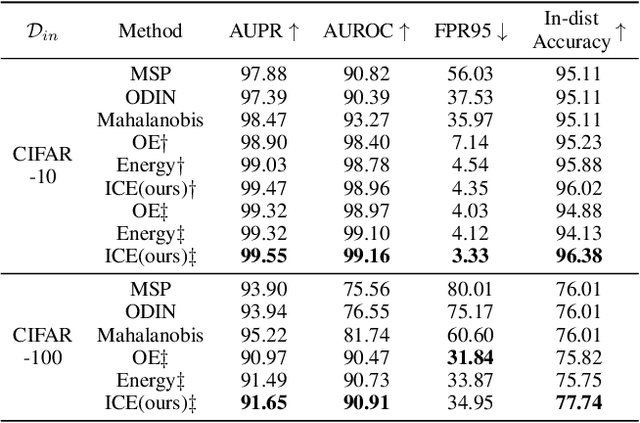
Deep neural network, despite its remarkable capability of discriminating targeted in-distribution samples, shows poor performance on detecting anomalous out-of-distribution data. To address this defect, state-of-the-art solutions choose to train deep networks on an auxiliary dataset of outliers. Various training criteria for these auxiliary outliers are proposed based on heuristic intuitions. However, we find that these intuitively designed outlier training criteria can hurt in-distribution learning and eventually lead to inferior performance. To this end, we identify three causes of the in-distribution incompatibility: contradictory gradient, false likelihood, and distribution shift. Based on our new understandings, we propose a new out-of-distribution detection method by adapting both the top-design of deep models and the loss function. Our method achieves in-distribution compatibility by pursuing less interference with the probabilistic characteristic of in-distribution features. On several benchmarks, our method not only achieves the state-of-the-art out-of-distribution detection performance but also improves the in-distribution accuracy.
Graph R-CNN: Towards Accurate 3D Object Detection with Semantic-Decorated Local Graph
Aug 07, 2022Two-stage detectors have gained much popularity in 3D object detection. Most two-stage 3D detectors utilize grid points, voxel grids, or sampled keypoints for RoI feature extraction in the second stage. Such methods, however, are inefficient in handling unevenly distributed and sparse outdoor points. This paper solves this problem in three aspects. 1) Dynamic Point Aggregation. We propose the patch search to quickly search points in a local region for each 3D proposal. The dynamic farthest voxel sampling is then applied to evenly sample the points. Especially, the voxel size varies along the distance to accommodate the uneven distribution of points. 2) RoI-graph Pooling. We build local graphs on the sampled points to better model contextual information and mine point relations through iterative message passing. 3) Visual Features Augmentation. We introduce a simple yet effective fusion strategy to compensate for sparse LiDAR points with limited semantic cues. Based on these modules, we construct our Graph R-CNN as the second stage, which can be applied to existing one-stage detectors to consistently improve the detection performance. Extensive experiments show that Graph R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI and Waymo Open Dataset. And we rank first place on the KITTI BEV car detection leaderboard. Code will be available at \url{https://github.com/Nightmare-n/GraphRCNN}.
DID-M3D: Decoupling Instance Depth for Monocular 3D Object Detection
Jul 22, 2022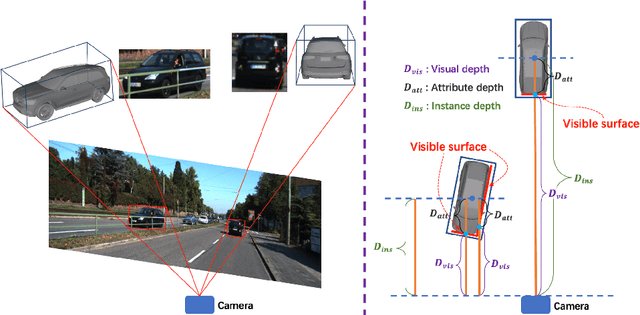
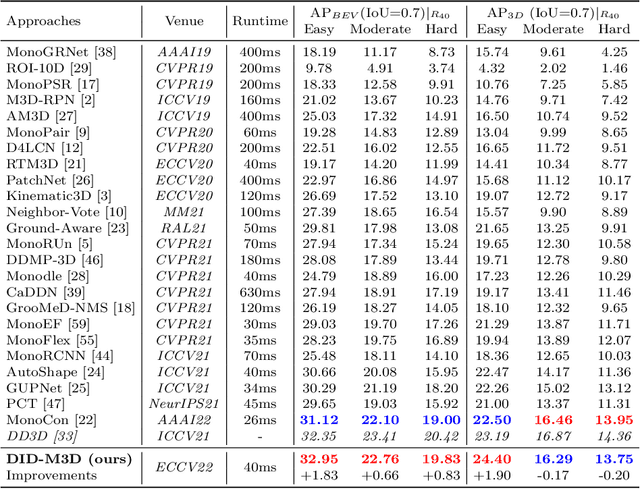
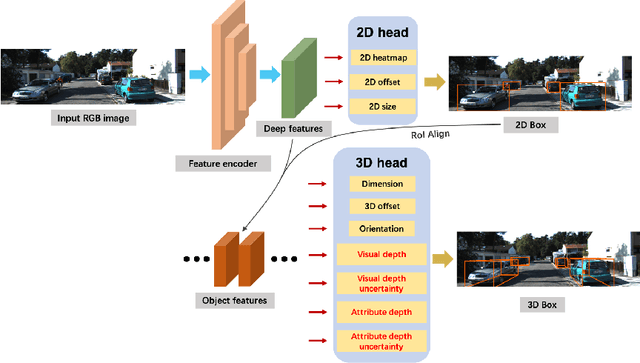

Monocular 3D detection has drawn much attention from the community due to its low cost and setup simplicity. It takes an RGB image as input and predicts 3D boxes in the 3D space. The most challenging sub-task lies in the instance depth estimation. Previous works usually use a direct estimation method. However, in this paper we point out that the instance depth on the RGB image is non-intuitive. It is coupled by visual depth clues and instance attribute clues, making it hard to be directly learned in the network. Therefore, we propose to reformulate the instance depth to the combination of the instance visual surface depth (visual depth) and the instance attribute depth (attribute depth). The visual depth is related to objects' appearances and positions on the image. By contrast, the attribute depth relies on objects' inherent attributes, which are invariant to the object affine transformation on the image. Correspondingly, we decouple the 3D location uncertainty into visual depth uncertainty and attribute depth uncertainty. By combining different types of depths and associated uncertainties, we can obtain the final instance depth. Furthermore, data augmentation in monocular 3D detection is usually limited due to the physical nature, hindering the boost of performance. Based on the proposed instance depth disentanglement strategy, we can alleviate this problem. Evaluated on KITTI, our method achieves new state-of-the-art results, and extensive ablation studies validate the effectiveness of each component in our method. The codes are released at https://github.com/SPengLiang/DID-M3D.
Towards Efficient Adversarial Training on Vision Transformers
Jul 21, 2022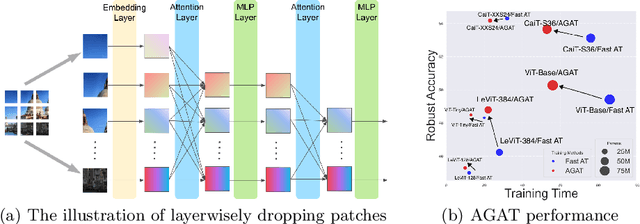
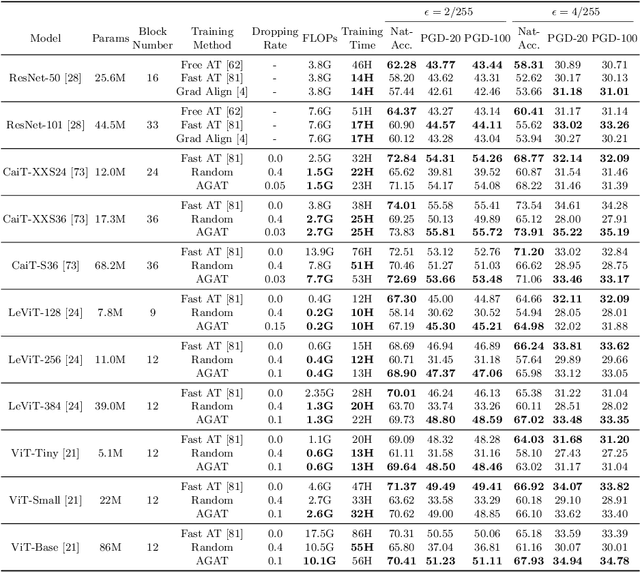
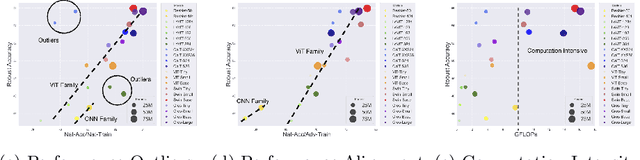
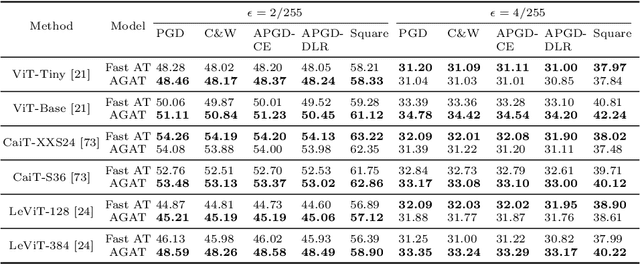
Vision Transformer (ViT), as a powerful alternative to Convolutional Neural Network (CNN), has received much attention. Recent work showed that ViTs are also vulnerable to adversarial examples like CNNs. To build robust ViTs, an intuitive way is to apply adversarial training since it has been shown as one of the most effective ways to accomplish robust CNNs. However, one major limitation of adversarial training is its heavy computational cost. The self-attention mechanism adopted by ViTs is a computationally intense operation whose expense increases quadratically with the number of input patches, making adversarial training on ViTs even more time-consuming. In this work, we first comprehensively study fast adversarial training on a variety of vision transformers and illustrate the relationship between the efficiency and robustness. Then, to expediate adversarial training on ViTs, we propose an efficient Attention Guided Adversarial Training mechanism. Specifically, relying on the specialty of self-attention, we actively remove certain patch embeddings of each layer with an attention-guided dropping strategy during adversarial training. The slimmed self-attention modules accelerate the adversarial training on ViTs significantly. With only 65\% of the fast adversarial training time, we match the state-of-the-art results on the challenging ImageNet benchmark.
Automatic Prosody Annotation with Pre-Trained Text-Speech Model
Jun 16, 2022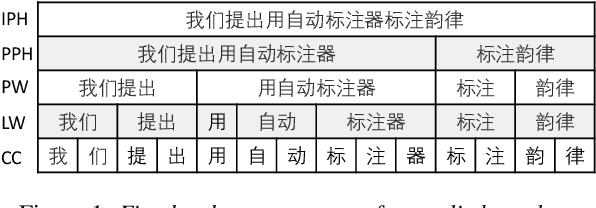
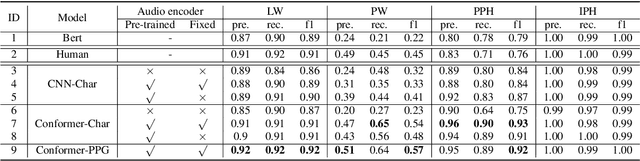

Prosodic boundary plays an important role in text-to-speech synthesis (TTS) in terms of naturalness and readability. However, the acquisition of prosodic boundary labels relies on manual annotation, which is costly and time-consuming. In this paper, we propose to automatically extract prosodic boundary labels from text-audio data via a neural text-speech model with pre-trained audio encoders. This model is pre-trained on text and speech data separately and jointly fine-tuned on TTS data in a triplet format: {speech, text, prosody}. The experimental results on both automatic evaluation and human evaluation demonstrate that: 1) the proposed text-speech prosody annotation framework significantly outperforms text-only baselines; 2) the quality of automatic prosodic boundary annotations is comparable to human annotations; 3) TTS systems trained with model-annotated boundaries are slightly better than systems that use manual ones.
Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation
Jun 06, 2022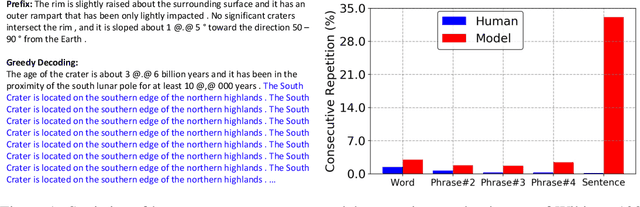
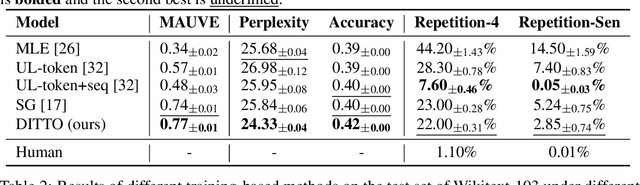
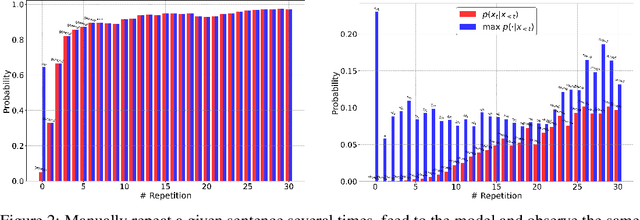
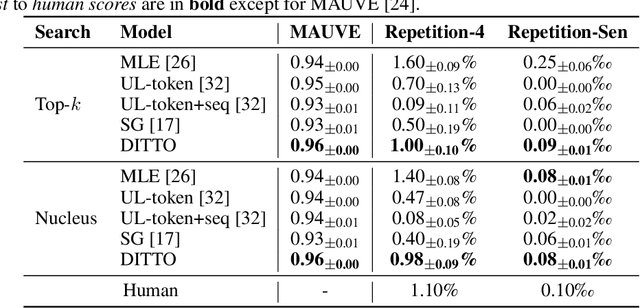
While large-scale neural language models, such as GPT2 and BART, have achieved impressive results on various text generation tasks, they tend to get stuck in undesirable sentence-level loops with maximization-based decoding algorithms (\textit{e.g.}, greedy search). This phenomenon is counter-intuitive since there are few consecutive sentence-level repetitions in human corpora (e.g., 0.02\% in Wikitext-103). To investigate the underlying reasons for generating consecutive sentence-level repetitions, we study the relationship between the probabilities of the repetitive tokens and their previous repetitions in the context. Through our quantitative experiments, we find that 1) Language models have a preference to repeat the previous sentence; 2) The sentence-level repetitions have a \textit{self-reinforcement effect}: the more times a sentence is repeated in the context, the higher the probability of continuing to generate that sentence; 3) The sentences with higher initial probabilities usually have a stronger self-reinforcement effect. Motivated by our findings, we propose a simple and effective training method \textbf{DITTO} (Pseu\underline{D}o-Repet\underline{IT}ion Penaliza\underline{T}i\underline{O}n), where the model learns to penalize probabilities of sentence-level repetitions from pseudo repetitive data. Although our method is motivated by mitigating repetitions, experiments show that DITTO not only mitigates the repetition issue without sacrificing perplexity, but also achieves better generation quality. Extensive experiments on open-ended text generation (Wikitext-103) and text summarization (CNN/DailyMail) demonstrate the generality and effectiveness of our method.
Neural Collapse Inspired Attraction-Repulsion-Balanced Loss for Imbalanced Learning
Apr 27, 2022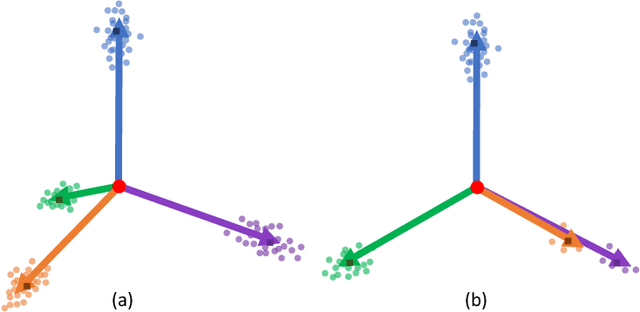
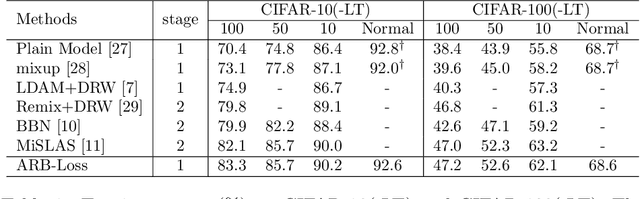
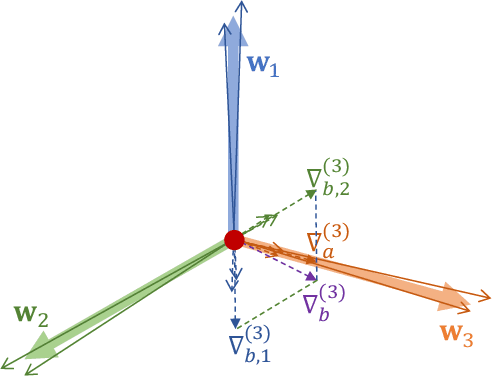
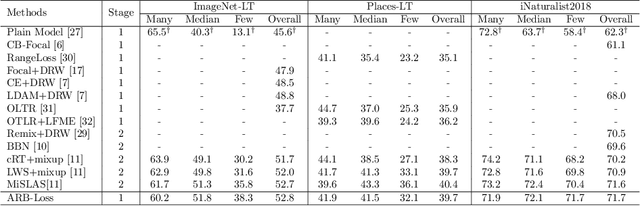
Class imbalance distribution widely exists in real-world engineering. However, the mainstream optimization algorithms that seek to minimize error will trap the deep learning model in sub-optimums when facing extreme class imbalance. It seriously harms the classification precision, especially on the minor classes. The essential reason is that the gradients of the classifier weights are imbalanced among the components from different classes. In this paper, we propose Attraction-Repulsion-Balanced Loss (ARB-Loss) to balance the different components of the gradients. We perform experiments on the large-scale classification and segmentation datasets and our ARB-Loss can achieve state-of-the-art performance via only one-stage training instead of 2-stage learning like nowadays SOTA works.
Frame-wise Action Representations for Long Videos via Sequence Contrastive Learning
Mar 28, 2022
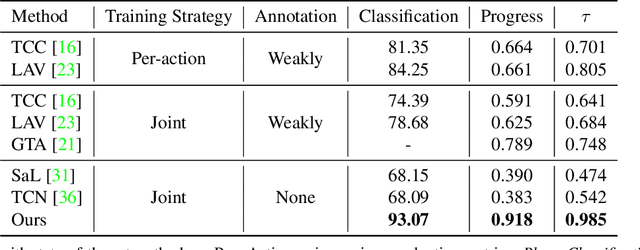
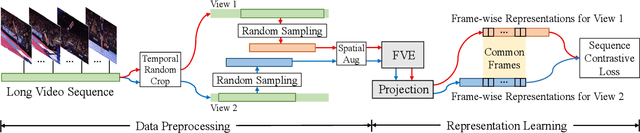
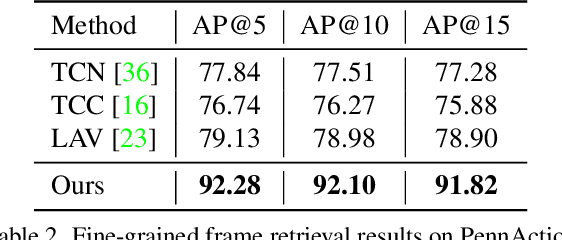
Prior works on action representation learning mainly focus on designing various architectures to extract the global representations for short video clips. In contrast, many practical applications such as video alignment have strong demand for learning dense representations for long videos. In this paper, we introduce a novel contrastive action representation learning (CARL) framework to learn frame-wise action representations, especially for long videos, in a self-supervised manner. Concretely, we introduce a simple yet efficient video encoder that considers spatio-temporal context to extract frame-wise representations. Inspired by the recent progress of self-supervised learning, we present a novel sequence contrastive loss (SCL) applied on two correlated views obtained through a series of spatio-temporal data augmentations. SCL optimizes the embedding space by minimizing the KL-divergence between the sequence similarity of two augmented views and a prior Gaussian distribution of timestamp distance. Experiments on FineGym, PennAction and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification. Surprisingly, although without training on paired videos, our approach also shows outstanding performance on video alignment and fine-grained frame retrieval tasks. Code and models are available at https://github.com/minghchen/CARL_code.
Linearizing Transformer with Key-Value Memory Bank
Mar 26, 2022
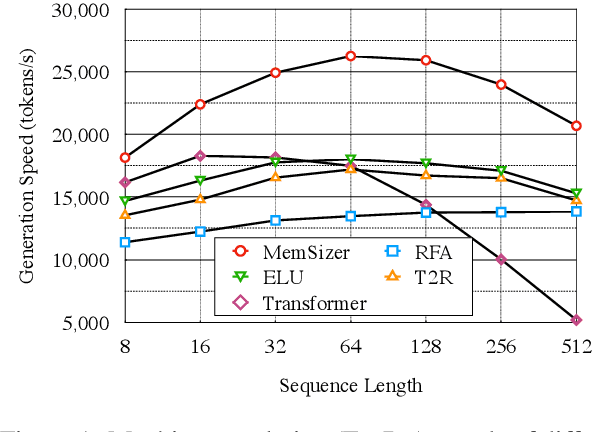
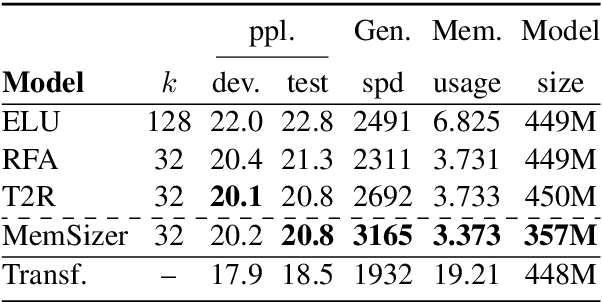
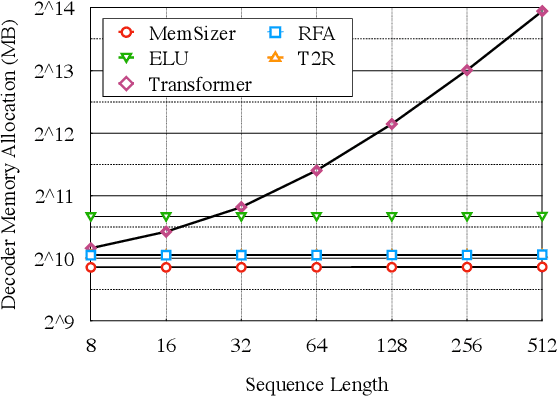
Transformer has brought great success to a wide range of natural language processing tasks. Nevertheless, the computational overhead of the vanilla transformer scales quadratically with sequence length. Many efforts have been made to develop more efficient transformer variants. A line of work (e.g., Linformer) projects the input sequence into a low-rank space, achieving linear time complexity. However, Linformer does not suit well for text generation tasks as the sequence length must be pre-specified. We propose MemSizer, an approach also projects the source sequence into lower dimension representation but can take input with dynamic length, with a different perspective of the attention mechanism. MemSizer not only achieves the same linear time complexity but also enjoys efficient recurrent-style autoregressive generation, which yields constant memory complexity and reduced computation at inference. We demonstrate that MemSizer provides an improved tradeoff between efficiency and accuracy over the vanilla transformer and other linear variants in language modeling and machine translation tasks, revealing a viable direction towards further inference efficiency improvement.