 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrofitting Multilingual Sentence Embeddings with Abstract Meaning Representation
Oct 18, 2022

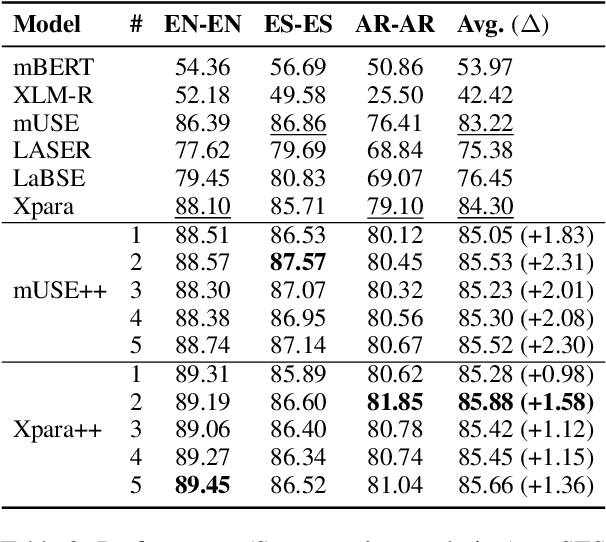
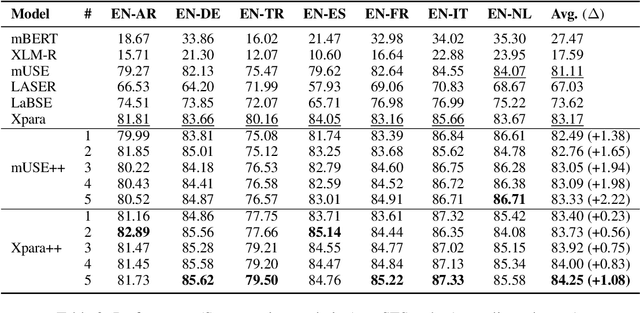
We introduce a new method to improve existing multilingual sentence embeddings with Abstract Meaning Representation (AMR). Compared with the original textual input, AMR is a structured semantic representation that presents the core concepts and relations in a sentence explicitly and unambiguously. It also helps reduce surface variations across different expressions and languages. Unlike most prior work that only evaluates the ability to measure semantic similarity, we present a thorough evaluation of existing multilingual sentence embeddings and our improved versions, which include a collection of five transfer tasks in different downstream applications. Experiment results show that retrofitting multilingual sentence embeddings with AMR leads to better state-of-the-art performance on both semantic textual similarity and transfer tasks. Our codebase and evaluation scripts can be found at \url{https://github.com/jcyk/MSE-AMR}.
Multilingual AMR Parsing with Noisy Knowledge Distillation
Oct 14, 2021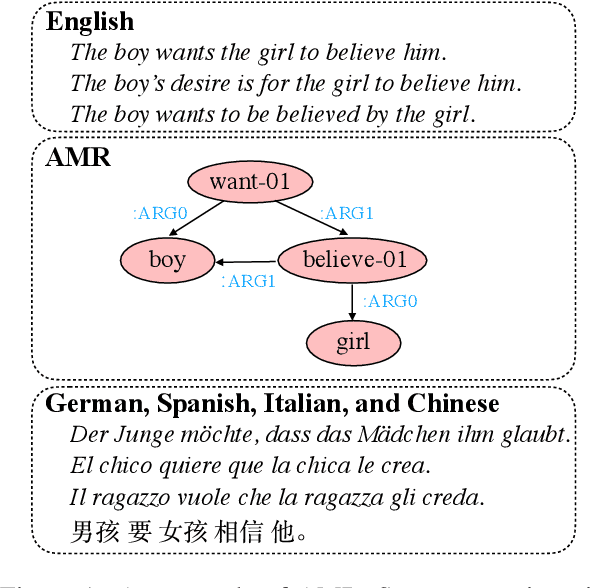
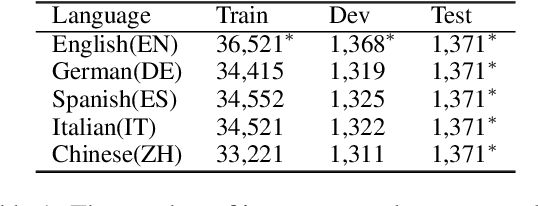
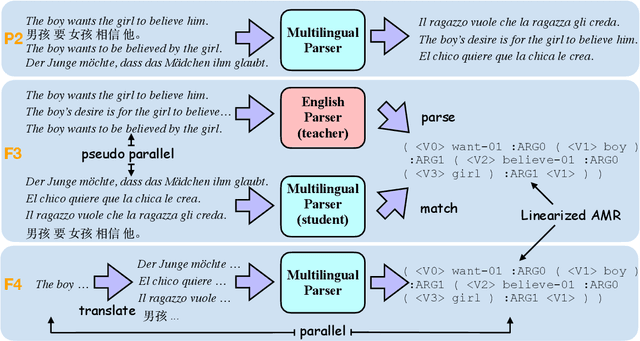
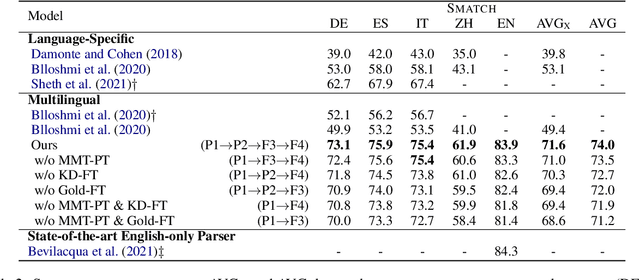
We study multilingual AMR parsing from the perspective of knowledge distillation, where the aim is to learn and improve a multilingual AMR parser by using an existing English parser as its teacher. We constrain our exploration in a strict multilingual setting: there is but one model to parse all different languages including English. We identify that noisy input and precise output are the key to successful distillation. Together with extensive pre-training, we obtain an AMR parser whose performances surpass all previously published results on four different foreign languages, including German, Spanish, Italian, and Chinese, by large margins (up to 18.8 \textsc{Smatch} points on Chinese and on average 11.3 \textsc{Smatch} points). Our parser also achieves comparable performance on English to the latest state-of-the-art English-only parser.