 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Convolution: Advancing Hypergraph Neural Networks with Hypergraph U-Nets
Jun 08, 2026Convolutions have successfully transitioned from image processing to the complex realm of non-Euclidean higher-order domains, particularly in hypergraphs. Despite the success in convolution, the exploration of a popular architecture named U-Net remains largely unexplored for hypergraph data due to the lack of well-defined pooling and unpooling operations. This work pioneers the study of U-Net architectures for hypergraph data, addressing the critical challenge of designing effective pooling and unpooling operations that retain maximal structural information from the input hypergraph. Motivated by hierarchical clustering, we propose to construct the pooling and unpooling operators all at once by cutting the clustering dendrogram at different granularities, named the Parallel Hierarchical Pooling (PHPool) and Unpooling (PHUnpool) operators. Unlike existing pooling methods that risk local structural damage through a sequential learning procedure, our PHPool operators are designed in a global and parallel manner to ensure fidelity to the original hypergraph structure with efficient computation while the PHUnpool operators are tailored to perform inverse operations of the PHPools for hypergraph reconstruction. We validate our model through hypergraph reconstruction simulation, hypergraph classification, and node-level anomaly detection, where it demonstrates superior performance over existing state-of-the-art graph and hypergraph deep learning methods.
Spatial-Temporal Decoupled Adapter for Micro-gesture Online Recognition
Jun 05, 2026Micro-gesture online recognition aims to temporally localize and classify subtle gestures in untrimmed videos. Owing to their extremely short duration, low motion amplitude, and ambiguous visual cues, capturing discriminative spatiotemporal representations remains highly challenging. Existing parameter-efficient adapters typically employ a single branch to model spatial and temporal cues jointly, which may fail to capture the fine-grained patterns of micro-gestures. To address this limitation, we propose a Spatial-Temporal Decoupled Adapter that decomposes video adaptation into independent temporal and spatial branches via lightweight depthwise convolutions. In addition, to address the long-tail distribution problem in the benchmark dataset, we introduce Adaptive Soft Balanced Augmentation, which dynamically allocates augmentation intensity based on class rarity and learning difficulty, without manual thresholds. Our method achieves an F1 score of 0.43808, ranking 1st in Track 2 of the 4th EI-MiGA-IJCAI Challenge.
Selective Forgetting for Large Reasoning Models
Apr 04, 2026Large Reasoning Models (LRMs) generate structured chains of thought (CoTs) before producing final answers, making them especially vulnerable to knowledge leakage through intermediate reasoning steps. Yet, the memorization of sensitive information in the training data such as copyrighted and private content has led to ethical and legal concerns. To address these issues, selective forgetting (also known as machine unlearning) has emerged as a potential remedy for LRMs. However, existing unlearning methods primarily target final answers and may degrade the overall reasoning ability of LRMs after forgetting. Additionally, directly applying unlearning on the entire CoTs could degrade the general reasoning capabilities. The key challenge for LRM unlearning lies in achieving precise unlearning of targeted knowledge while preserving the integrity of general reasoning capabilities. To bridge this gap, we in this paper propose a novel LRM unlearning framework that selectively removes sensitive reasoning components while preserving general reasoning capabilities. Our approach leverages multiple LLMs with retrieval-augmented generation (RAG) to analyze CoT traces, identify forget-relevant segments, and replace them with benign placeholders that maintain logical structure. We also introduce a new feature replacement unlearning loss for LRMs, which can simultaneously suppress the probability of generating forgotten content while reinforcing structurally valid replacements. Extensive experiments on both synthetic and medical datasets verify the desired properties of our proposed method.
FreqPhys: Repurposing Implicit Physiological Frequency Prior for Robust Remote Photoplethysmography
Apr 01, 2026Remote photoplethysmography (rPPG) enables contactless physiological monitoring by capturing subtle skin-color variations from facial videos. However, most existing methods predominantly rely on time-domain modeling, making them vulnerable to motion artifacts and illumination fluctuations, where weak physiological clues are easily overwhelmed by noise. To address these challenges, we propose FreqPhys, a frequency-guided rPPG framework that explicitly leverages physiological frequency priors for robust signal recovery. Specifically, FreqPhys first applies a Physiological Bandpass Filtering module to suppress out-of-band interference, and then performs Physiological Spectrum Modulation together with adaptive spectral selection to emphasize pulse-related frequency components while suppress residual in-band noise. A Cross-domain Representation Learning module further fuses these spectral priors with deep time-domain features to capture informative spatial--temporal dependencies. Finally, a frequency-aware conditional diffusion process progressively reconstructs high-fidelity rPPG signals. Extensive experiments on six benchmarks demonstrate that FreqPhys yields significant improvements over state-of-the-art approaches, particularly under challenging motion conditions. It highlights the importance of explicitly modeling physiological frequency priors. The source code will be released.
Face-Guided Sentiment Boundary Enhancement for Weakly-Supervised Temporal Sentiment Localization
Mar 16, 2026Point-level weakly-supervised temporal sentiment localization (P-WTSL) aims to detect sentiment-relevant segments in untrimmed multimodal videos using timestamp sentiment annotations, which greatly reduces the costly frame-level labeling. To further tackle the challenges of imprecise sentiment boundaries in P-WTSL, we propose the Face-guided Sentiment Boundary Enhancement Network (\textbf{FSENet}), a unified framework that leverages fine-grained facial features to guide sentiment localization. Specifically, our approach \textit{first} introduces the Face-guided Sentiment Discovery (FSD) module, which integrates facial features into multimodal interaction via dual-branch modeling for effective sentiment stimuli clues; We \textit{then} propose the Point-aware Sentiment Semantics Contrast (PSSC) strategy to discriminate sentiment semantics of candidate points (frame-level) near annotation points via contrastive learning, thereby enhancing the model's ability to recognize sentiment boundaries. At \textit{last}, we design the Boundary-aware Sentiment Pseudo-label Generation (BSPG) approach to convert sparse point annotations into temporally smooth supervisory pseudo-labels. Extensive experiments and visualizations on the benchmark demonstrate the effectiveness of our framework, achieving state-of-the-art performance under full supervision, video-level, and point-level weak supervision, thereby showcasing the strong generalization ability of our FSENet across different annotation settings.
Towards Benchmarking Privacy Vulnerabilities in Selective Forgetting with Large Language Models
Dec 19, 2025The rapid advancements in artificial intelligence (AI) have primarily focused on the process of learning from data to acquire knowledgeable learning systems. As these systems are increasingly deployed in critical areas, ensuring their privacy and alignment with human values is paramount. Recently, selective forgetting (also known as machine unlearning) has shown promise for privacy and data removal tasks, and has emerged as a transformative paradigm shift in the field of AI. It refers to the ability of a model to selectively erase the influence of previously seen data, which is especially important for compliance with modern data protection regulations and for aligning models with human values. Despite its promise, selective forgetting raises significant privacy concerns, especially when the data involved come from sensitive domains. While new unlearning-induced privacy attacks are continuously proposed, each is shown to outperform its predecessors using different experimental settings, which can lead to overly optimistic and potentially unfair assessments that may disproportionately favor one particular attack over the others. In this work, we present the first comprehensive benchmark for evaluating privacy vulnerabilities in selective forgetting. We extensively investigate privacy vulnerabilities of machine unlearning techniques and benchmark privacy leakage across a wide range of victim data, state-of-the-art unlearning privacy attacks, unlearning methods, and model architectures. We systematically evaluate and identify critical factors related to unlearning-induced privacy leakage. With our novel insights, we aim to provide a standardized tool for practitioners seeking to deploy customized unlearning applications with faithful privacy assessments.
Towards Unveiling Predictive Uncertainty Vulnerabilities in the Context of the Right to Be Forgotten
Aug 10, 2025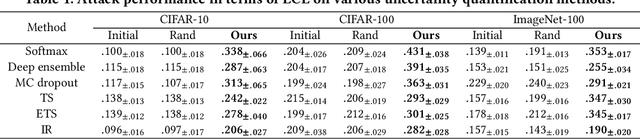
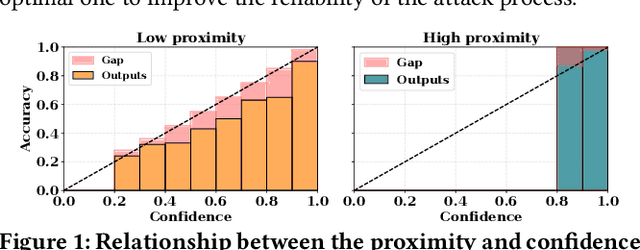
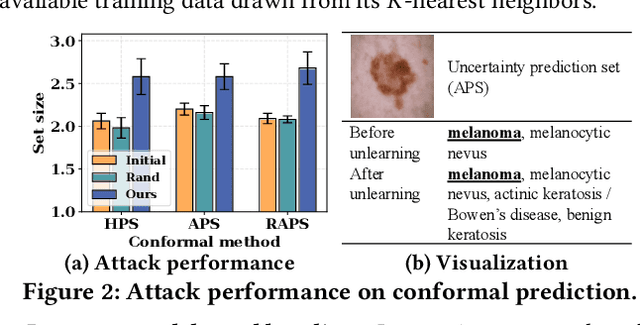
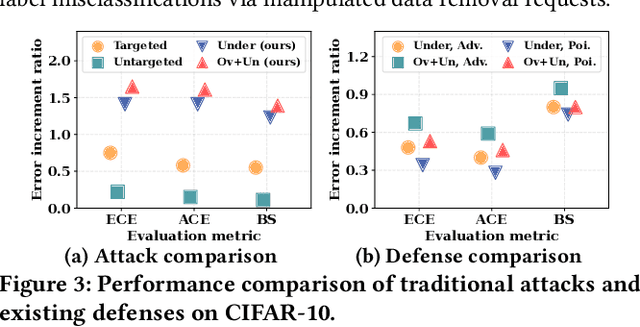
Currently, various uncertainty quantification methods have been proposed to provide certainty and probability estimates for deep learning models' label predictions. Meanwhile, with the growing demand for the right to be forgotten, machine unlearning has been extensively studied as a means to remove the impact of requested sensitive data from a pre-trained model without retraining the model from scratch. However, the vulnerabilities of such generated predictive uncertainties with regard to dedicated malicious unlearning attacks remain unexplored. To bridge this gap, for the first time, we propose a new class of malicious unlearning attacks against predictive uncertainties, where the adversary aims to cause the desired manipulations of specific predictive uncertainty results. We also design novel optimization frameworks for our attacks and conduct extensive experiments, including black-box scenarios. Notably, our extensive experiments show that our attacks are more effective in manipulating predictive uncertainties than traditional attacks that focus on label misclassifications, and existing defenses against conventional attacks are ineffective against our attacks.
Membership Inference Attacks with False Discovery Rate Control
Aug 09, 2025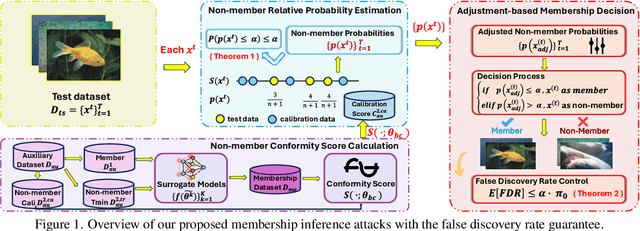

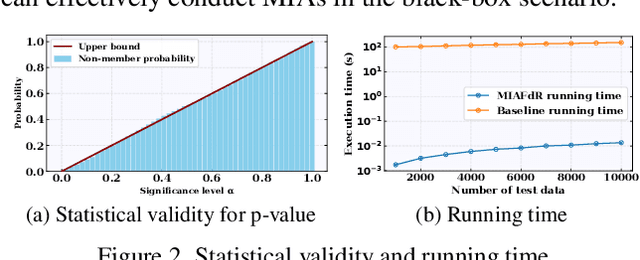
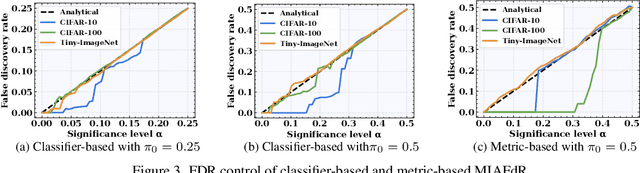
Recent studies have shown that deep learning models are vulnerable to membership inference attacks (MIAs), which aim to infer whether a data record was used to train a target model or not. To analyze and study these vulnerabilities, various MIA methods have been proposed. Despite the significance and popularity of MIAs, existing works on MIAs are limited in providing guarantees on the false discovery rate (FDR), which refers to the expected proportion of false discoveries among the identified positive discoveries. However, it is very challenging to ensure the false discovery rate guarantees, because the underlying distribution is usually unknown, and the estimated non-member probabilities often exhibit interdependence. To tackle the above challenges, in this paper, we design a novel membership inference attack method, which can provide the guarantees on the false discovery rate. Additionally, we show that our method can also provide the marginal probability guarantee on labeling true non-member data as member data. Notably, our method can work as a wrapper that can be seamlessly integrated with existing MIA methods in a post-hoc manner, while also providing the FDR control. We perform the theoretical analysis for our method. Extensive experiments in various settings (e.g., the black-box setting and the lifelong learning setting) are also conducted to verify the desirable performance of our method.
Dense Audio-Visual Event Localization under Cross-Modal Consistency and Multi-Temporal Granularity Collaboration
Dec 17, 2024



In the field of audio-visual learning, most research tasks focus exclusively on short videos. This paper focuses on the more practical Dense Audio-Visual Event Localization (DAVEL) task, advancing audio-visual scene understanding for longer, {untrimmed} videos. This task seeks to identify and temporally pinpoint all events simultaneously occurring in both audio and visual streams. Typically, each video encompasses dense events of multiple classes, which may overlap on the timeline, each exhibiting varied durations. Given these challenges, effectively exploiting the audio-visual relations and the temporal features encoded at various granularities becomes crucial. To address these challenges, we introduce a novel \ul{CC}Net, comprising two core modules: the Cross-Modal Consistency \ul{C}ollaboration (CMCC) and the Multi-Temporal Granularity \ul{C}ollaboration (MTGC). Specifically, the CMCC module contains two branches: a cross-modal interaction branch and a temporal consistency-gated branch. The former branch facilitates the aggregation of consistent event semantics across modalities through the encoding of audio-visual relations, while the latter branch guides one modality's focus to pivotal event-relevant temporal areas as discerned in the other modality. The MTGC module includes a coarse-to-fine collaboration block and a fine-to-coarse collaboration block, providing bidirectional support among coarse- and fine-grained temporal features. Extensive experiments on the UnAV-100 dataset validate our module design, resulting in a new state-of-the-art performance in dense audio-visual event localization. The code is available at \url{https://github.com/zzhhfut/CCNet-AAAI2025}.
Joint Spatial-Temporal Modeling and Contrastive Learning for Self-supervised Heart Rate Measurement
Jun 07, 2024



This paper briefly introduces the solutions developed by our team, HFUT-VUT, for Track 1 of self-supervised heart rate measurement in the 3rd Vision-based Remote Physiological Signal Sensing (RePSS) Challenge hosted at IJCAI 2024. The goal is to develop a self-supervised learning algorithm for heart rate (HR) estimation using unlabeled facial videos. To tackle this task, we present two self-supervised HR estimation solutions that integrate spatial-temporal modeling and contrastive learning, respectively. Specifically, we first propose a non-end-to-end self-supervised HR measurement framework based on spatial-temporal modeling, which can effectively capture subtle rPPG clues and leverage the inherent bandwidth and periodicity characteristics of rPPG to constrain the model. Meanwhile, we employ an excellent end-to-end solution based on contrastive learning, aiming to generalize across different scenarios from complementary perspectives. Finally, we combine the strengths of the above solutions through an ensemble strategy to generate the final predictions, leading to a more accurate HR estimation. As a result, our solutions achieved a remarkable RMSE score of 8.85277 on the test dataset, securing \textbf{2nd place} in Track 1 of the challenge.