 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROST-LLM: Progressively Enhancing the Speech-to-Speech Translation Capability in LLMs
Jan 23, 2026Although Large Language Models (LLMs) excel in many tasks, their application to Speech-to-Speech Translation (S2ST) is underexplored and hindered by data scarcity. To bridge this gap, we propose PROST-LLM (PROgressive Speech-to-speech Translation) to enhance the S2ST capabilities in LLMs progressively. First, we fine-tune the LLMs with the CVSS corpus, employing designed tri-task learning and chain of modality methods to boost the initial performance. Then, leveraging the fine-tuned model, we generate preference pairs through self-sampling and back-translation without human evaluation. Finally, these preference pairs are used for preference optimization to enhance the model's S2ST capability further. Extensive experiments confirm the effectiveness of our proposed PROST-LLM in improving the S2ST capability of LLMs.
DSA-Tokenizer: Disentangled Semantic-Acoustic Tokenization via Flow Matching-based Hierarchical Fusion
Jan 15, 2026Speech tokenizers serve as the cornerstone of discrete Speech Large Language Models (Speech LLMs). Existing tokenizers either prioritize semantic encoding, fuse semantic content with acoustic style inseparably, or achieve incomplete semantic-acoustic disentanglement. To achieve better disentanglement, we propose DSA-Tokenizer, which explicitly disentangles speech into discrete semantic and acoustic tokens via distinct optimization constraints. Specifically, semantic tokens are supervised by ASR to capture linguistic content, while acoustic tokens focus on mel-spectrograms restoration to encode style. To eliminate rigid length constraints between the two sequences, we introduce a hierarchical Flow-Matching decoder that further improve speech generation quality. Furthermore, We employ a joint reconstruction-recombination training strategy to enforce this separation. DSA-Tokenizer enables high fidelity reconstruction and flexible recombination through robust disentanglement, facilitating controllable generation in speech LLMs. Our analysis highlights disentangled tokenization as a pivotal paradigm for future speech modeling. Audio samples are avaialble at https://anonymous.4open.science/w/DSA_Tokenizer_demo/. The code and model will be made publicly available after the paper has been accepted.
AEQ-Bench: Measuring Empathy of Omni-Modal Large Models
Jan 15, 2026While the automatic evaluation of omni-modal large models (OLMs) is essential, assessing empathy remains a significant challenge due to its inherent affectivity. To investigate this challenge, we introduce AEQ-Bench (Audio Empathy Quotient Benchmark), a novel benchmark to systematically assess two core empathetic capabilities of OLMs: (i) generating empathetic responses by comprehending affective cues from multi-modal inputs (audio + text), and (ii) judging the empathy of audio responses without relying on text transcription. Compared to existing benchmarks, AEQ-Bench incorporates two novel settings that vary in context specificity and speech tone. Comprehensive assessment across linguistic and paralinguistic metrics reveals that (1) OLMs trained with audio output capabilities generally outperformed models with text-only outputs, and (2) while OLMs align with human judgments for coarse-grained quality assessment, they remain unreliable for evaluating fine-grained paralinguistic expressiveness.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024



GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
Enhancing Multilingual Speech Generation and Recognition Abilities in LLMs with Constructed Code-switched Data
Sep 17, 2024



While large language models (LLMs) have been explored in the speech domain for both generation and recognition tasks, their applications are predominantly confined to the monolingual scenario, with limited exploration in multilingual and code-switched (CS) contexts. Additionally, speech generation and recognition tasks are often handled separately, such as VALL-E and Qwen-Audio. In this paper, we propose a MutltiLingual MultiTask (MLMT) model, integrating multilingual speech generation and recognition tasks within the single LLM. Furthermore, we develop an effective data construction approach that splits and concatenates words from different languages to equip LLMs with CS synthesis ability without relying on CS data. The experimental results demonstrate that our model outperforms other baselines with a comparable data scale. Furthermore, our data construction approach not only equips LLMs with CS speech synthesis capability with comparable speaker consistency and similarity to any given speaker, but also improves the performance of LLMs in multilingual speech generation and recognition tasks.
Exploring SSL Discrete Tokens for Multilingual ASR
Sep 13, 2024



With the advancement of Self-supervised Learning (SSL) in speech-related tasks, there has been growing interest in utilizing discrete tokens generated by SSL for automatic speech recognition (ASR), as they offer faster processing techniques. However, previous studies primarily focused on multilingual ASR with Fbank features or English ASR with discrete tokens, leaving a gap in adapting discrete tokens for multilingual ASR scenarios. This study presents a comprehensive comparison of discrete tokens generated by various leading SSL models across multiple language domains. We aim to explore the performance and efficiency of speech discrete tokens across multiple language domains for both monolingual and multilingual ASR scenarios. Experimental results demonstrate that discrete tokens achieve comparable results against systems trained on Fbank features in ASR tasks across seven language domains with an average word error rate (WER) reduction of 0.31% and 1.76% absolute (2.80% and 15.70% relative) on dev and test sets respectively, with particularly WER reduction of 6.82% absolute (41.48% relative) on the Polish test set.
ToneUnit: A Speech Discretization Approach for Tonal Language Speech Synthesis
Jun 13, 2024



Representing speech as discretized units has numerous benefits in supporting downstream spoken language processing tasks. However, the approach has been less explored in speech synthesis of tonal languages like Mandarin Chinese. Our preliminary experiments on Chinese speech synthesis reveal the issue of "tone shift", where a synthesized speech utterance contains correct base syllables but incorrect tones. To address the issue, we propose the ToneUnit framework, which leverages annotated data with tone labels as CTC supervision to learn tone-aware discrete speech units for Mandarin Chinese speech. Our findings indicate that the discrete units acquired through the TonUnit resolve the "tone shift" issue in synthesized Chinese speech and yield favorable results in English synthesis. Moreover, the experimental results suggest that finite scalar quantization enhances the effectiveness of ToneUnit. Notably, ToneUnit can work effectively even with minimal annotated data.
Analysis and Utilization of Entrainment on Acoustic and Emotion Features in User-agent Dialogue
Dec 07, 2022



Entrainment is the phenomenon by which an interlocutor adapts their speaking style to align with their partner in conversations. It has been found in different dimensions as acoustic, prosodic, lexical or syntactic. In this work, we explore and utilize the entrainment phenomenon to improve spoken dialogue systems for voice assistants. We first examine the existence of the entrainment phenomenon in human-to-human dialogues in respect to acoustic feature and then extend the analysis to emotion features. The analysis results show strong evidence of entrainment in terms of both acoustic and emotion features. Based on this findings, we implement two entrainment policies and assess if the integration of entrainment principle into a Text-to-Speech (TTS) system improves the synthesis performance and the user experience. It is found that the integration of the entrainment principle into a TTS system brings performance improvement when considering acoustic features, while no obvious improvement is observed when considering emotion features.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022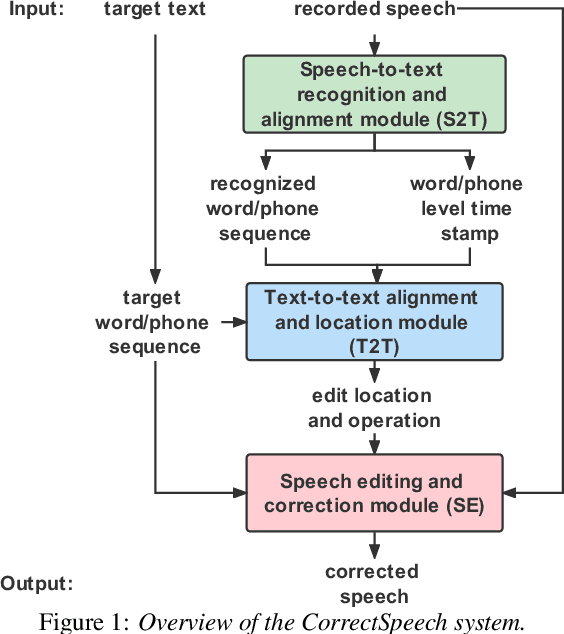
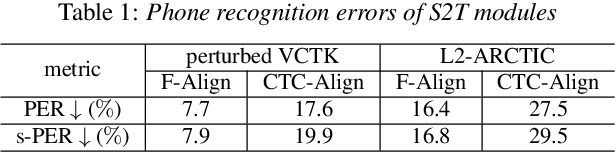
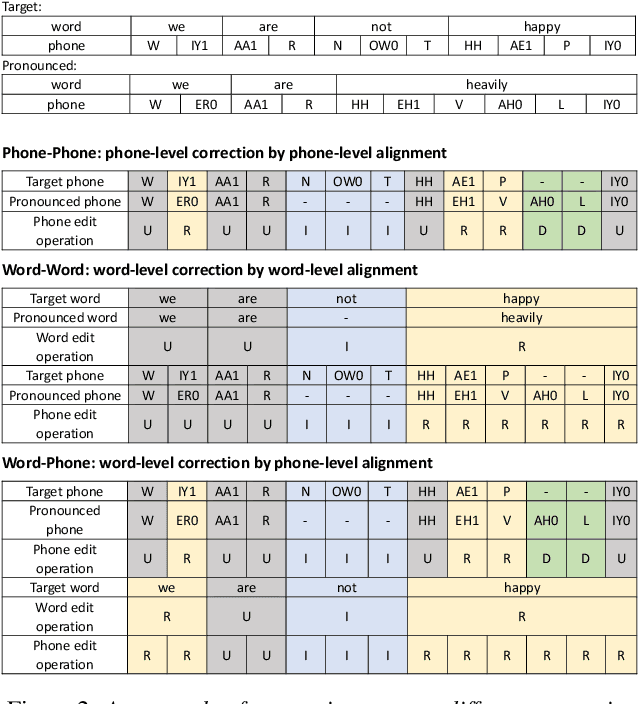
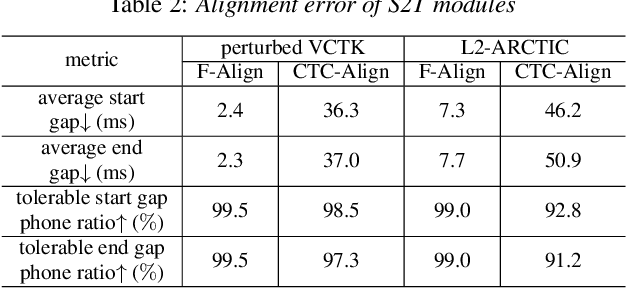
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .
Mixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech
Mar 31, 2022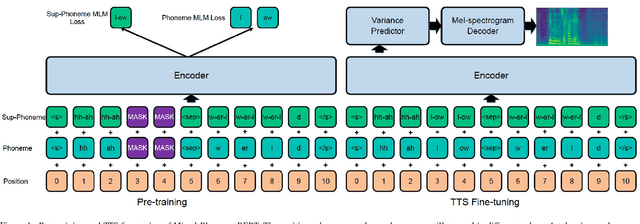
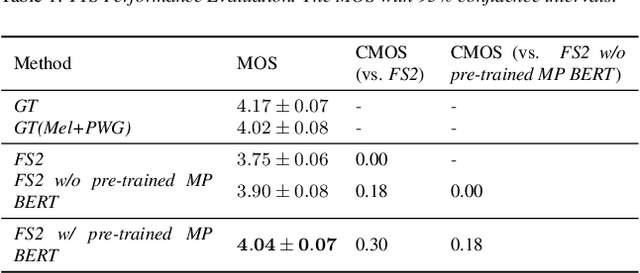

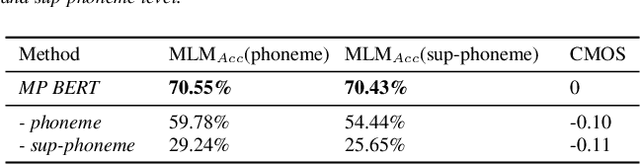
Recently, leveraging BERT pre-training to improve the phoneme encoder in text to speech (TTS) has drawn increasing attention. However, the works apply pre-training with character-based units to enhance the TTS phoneme encoder, which is inconsistent with the TTS fine-tuning that takes phonemes as input. Pre-training only with phonemes as input can alleviate the input mismatch but lack the ability to model rich representations and semantic information due to limited phoneme vocabulary. In this paper, we propose MixedPhoneme BERT, a novel variant of the BERT model that uses mixed phoneme and sup-phoneme representations to enhance the learning capability. Specifically, we merge the adjacent phonemes into sup-phonemes and combine the phoneme sequence and the merged sup-phoneme sequence as the model input, which can enhance the model capacity to learn rich contextual representations. Experiment results demonstrate that our proposed Mixed-Phoneme BERT significantly improves the TTS performance with 0.30 CMOS gain compared with the FastSpeech 2 baseline. The Mixed-Phoneme BERT achieves 3x inference speedup and similar voice quality to the previous TTS pre-trained model PnG BERT