 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngagement Process: Rethinking the Temporal Interface of Action and Observation
May 12, 2026Task completion in digital and physical environments increasingly involves complex temporal interaction, where actions and observations unfold over different time scales rather than align with fixed observation--action steps. To model such interactions, we propose \emph{Engagement Process} (EP), an interaction formalism that inherits the decision-theoretic structure of POMDPs while making time explicit in the action--observation interface. EP represents actions and observations as decoupled event streams along time, rather than updates paired at fixed decision steps. This interface captures single-agent timing issues such as deliberation latency, delayed feedback, and persistent actions, while supporting richer agent-side organization, multi-rate coordination, and compositional interaction among subsystems. Across toy, LLM-agent, and learning experiments, EP exposes temporal behaviors hidden by step-based interfaces and enables policies to adapt under explicit time costs.
DSA-Tokenizer: Disentangled Semantic-Acoustic Tokenization via Flow Matching-based Hierarchical Fusion
Jan 15, 2026Speech tokenizers serve as the cornerstone of discrete Speech Large Language Models (Speech LLMs). Existing tokenizers either prioritize semantic encoding, fuse semantic content with acoustic style inseparably, or achieve incomplete semantic-acoustic disentanglement. To achieve better disentanglement, we propose DSA-Tokenizer, which explicitly disentangles speech into discrete semantic and acoustic tokens via distinct optimization constraints. Specifically, semantic tokens are supervised by ASR to capture linguistic content, while acoustic tokens focus on mel-spectrograms restoration to encode style. To eliminate rigid length constraints between the two sequences, we introduce a hierarchical Flow-Matching decoder that further improve speech generation quality. Furthermore, We employ a joint reconstruction-recombination training strategy to enforce this separation. DSA-Tokenizer enables high fidelity reconstruction and flexible recombination through robust disentanglement, facilitating controllable generation in speech LLMs. Our analysis highlights disentangled tokenization as a pivotal paradigm for future speech modeling. Audio samples are avaialble at https://anonymous.4open.science/w/DSA_Tokenizer_demo/. The code and model will be made publicly available after the paper has been accepted.
CAKE: Cascading and Adaptive KV Cache Eviction with Layer Preferences
Mar 16, 2025



Large language models (LLMs) excel at processing long sequences, boosting demand for key-value (KV) caching. While recent efforts to evict KV cache have alleviated the inference burden, they often fail to allocate resources rationally across layers with different attention patterns. In this paper, we introduce Cascading and Adaptive KV cache Eviction (CAKE), a novel approach that frames KV cache eviction as a "cake-slicing problem." CAKE assesses layer-specific preferences by considering attention dynamics in both spatial and temporal dimensions, allocates rational cache size for layers accordingly, and manages memory constraints in a cascading manner. This approach enables a global view of cache allocation, adaptively distributing resources across diverse attention mechanisms while maintaining memory budgets. CAKE also employs a new eviction indicator that considers the shifting importance of tokens over time, addressing limitations in existing methods that overlook temporal dynamics. Comprehensive experiments on LongBench and NeedleBench show that CAKE maintains model performance with only 3.2% of the KV cache and consistently outperforms current baselines across various models and memory constraints, particularly in low-memory settings. Additionally, CAKE achieves over 10x speedup in decoding latency compared to full cache when processing contexts of 128K tokens with FlashAttention-2. Our code is available at https://github.com/antgroup/cakekv.
Multi-Strategy Enhanced COA for Path Planning in Autonomous Navigation
Mar 04, 2025



Autonomous navigation is reshaping various domains in people's life by enabling efficient and safe movement in complex environments. Reliable navigation requires algorithmic approaches that compute optimal or near-optimal trajectories while satisfying task-specific constraints and ensuring obstacle avoidance. However, existing methods struggle with slow convergence and suboptimal solutions, particularly in complex environments, limiting their real-world applicability. To address these limitations, this paper presents the Multi-Strategy Enhanced Crayfish Optimization Algorithm (MCOA), a novel approach integrating three key strategies: 1) Refractive Opposition Learning, enhancing population diversity and global exploration, 2) Stochastic Centroid-Guided Exploration, balancing global and local search to prevent premature convergence, and 3) Adaptive Competition-Based Selection, dynamically adjusting selection pressure for faster convergence and improved solution quality. Empirical evaluations underscore the remarkable planning speed and the amazing solution quality of MCOA in both 3D Unmanned Aerial Vehicle (UAV) and 2D mobile robot path planning. Against 11 baseline algorithms, MCOA achieved a 69.2% reduction in computational time and a 16.7% improvement in minimizing overall path cost in 3D UAV scenarios. Furthermore, in 2D path planning, MCOA outperformed baseline approaches by 44% on average, with an impressive 75.6% advantage in the largest 60*60 grid setting. These findings validate MCOA as a powerful tool for optimizing autonomous navigation in complex environments. The source code is available at: https://github.com/coedv-hub/MCOA.
Efficient or Powerful? Trade-offs Between Machine Learning and Deep Learning for Mental Illness Detection on Social Media
Mar 03, 2025Social media platforms provide valuable insights into mental health trends by capturing user-generated discussions on conditions such as depression, anxiety, and suicidal ideation. Machine learning (ML) and deep learning (DL) models have been increasingly applied to classify mental health conditions from textual data, but selecting the most effective model involves trade-offs in accuracy, interpretability, and computational efficiency. This study evaluates multiple ML models, including logistic regression, random forest, and LightGBM, alongside deep learning architectures such as ALBERT and Gated Recurrent Units (GRUs), for both binary and multi-class classification of mental health conditions. Our findings indicate that ML and DL models achieve comparable classification performance on medium-sized datasets, with ML models offering greater interpretability through variable importance scores, while DL models are more robust to complex linguistic patterns. Additionally, ML models require explicit feature engineering, whereas DL models learn hierarchical representations directly from text. Logistic regression provides the advantage of capturing both positive and negative associations between features and mental health conditions, whereas tree-based models prioritize decision-making power through split-based feature selection. This study offers empirical insights into the advantages and limitations of different modeling approaches and provides recommendations for selecting appropriate methods based on dataset size, interpretability needs, and computational constraints.
Systematic Review: Text Processing Algorithms in Machine Learning and Deep Learning for Mental Health Detection on Social Media
Oct 21, 2024



The global rise in depression necessitates innovative detection methods for early intervention. Social media provides a unique opportunity to identify depression through user-generated posts. This systematic review evaluates machine learning (ML) models for depression detection on social media, focusing on biases and methodological challenges throughout the ML lifecycle. A search of PubMed, IEEE Xplore, and Google Scholar identified 47 relevant studies published after 2010. The Prediction model Risk Of Bias ASsessment Tool (PROBAST) was utilized to assess methodological quality and risk of bias. Significant biases impacting model reliability and generalizability were found. There is a predominant reliance on Twitter (63.8%) and English-language content (over 90%), with most studies focusing on users from the United States and Europe. Non-probability sampling methods (approximately 80%) limit representativeness. Only 23% of studies explicitly addressed linguistic nuances like negations, crucial for accurate sentiment analysis. Inconsistent hyperparameter tuning was observed, with only 27.7% properly tuning models. About 17% did not adequately partition data into training, validation, and test sets, risking overfitting. While 74.5% used appropriate evaluation metrics for imbalanced data, others relied on accuracy without addressing class imbalance, potentially skewing results. Reporting transparency varied, often lacking critical methodological details. These findings highlight the need to diversify data sources, standardize preprocessing protocols, ensure consistent model development practices, address class imbalance, and enhance reporting transparency. By overcoming these challenges, future research can develop more robust and generalizable ML models for depression detection on social media, contributing to improved mental health outcomes globally.
Uniformly Distributed Category Prototype-Guided Vision-Language Framework for Long-Tail Recognition
Aug 24, 2023



Recently, large-scale pre-trained vision-language models have presented benefits for alleviating class imbalance in long-tailed recognition. However, the long-tailed data distribution can corrupt the representation space, where the distance between head and tail categories is much larger than the distance between two tail categories. This uneven feature space distribution causes the model to exhibit unclear and inseparable decision boundaries on the uniformly distributed test set, which lowers its performance. To address these challenges, we propose the uniformly category prototype-guided vision-language framework to effectively mitigate feature space bias caused by data imbalance. Especially, we generate a set of category prototypes uniformly distributed on a hypersphere. Category prototype-guided mechanism for image-text matching makes the features of different classes converge to these distinct and uniformly distributed category prototypes, which maintain a uniform distribution in the feature space, and improve class boundaries. Additionally, our proposed irrelevant text filtering and attribute enhancement module allows the model to ignore irrelevant noisy text and focus more on key attribute information, thereby enhancing the robustness of our framework. In the image recognition fine-tuning stage, to address the positive bias problem of the learnable classifier, we design the class feature prototype-guided classifier, which compensates for the performance of tail classes while maintaining the performance of head classes. Our method outperforms previous vision-language methods for long-tailed learning work by a large margin and achieves state-of-the-art performance.
Incremental Semantic Localization using Hierarchical Clustering of Object Association Sets
Aug 28, 2022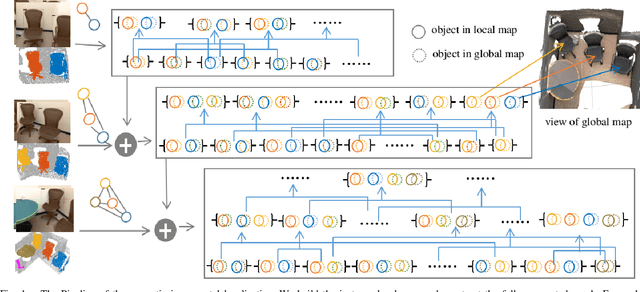
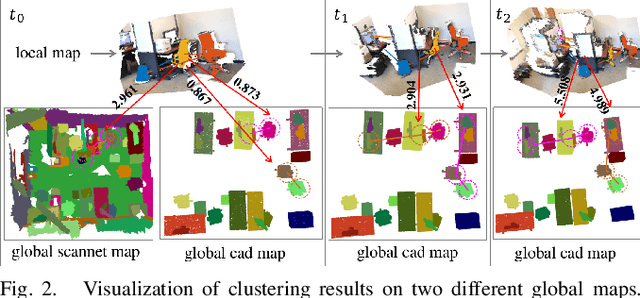
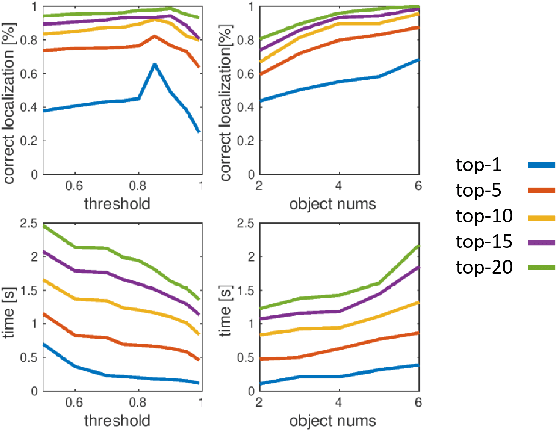
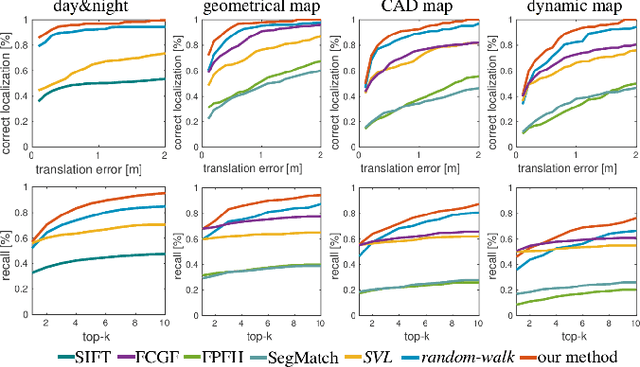
We present a novel approach for relocalization or place recognition, a fundamental problem to be solved in many robotics, automation, and AR applications. Rather than relying on often unstable appearance information, we consider a situation in which the reference map is given in the form of localized objects. Our localization framework relies on 3D semantic object detections, which are then associated to objects in the map. Possible pair-wise association sets are grown based on hierarchical clustering using a merge metric that evaluates spatial compatibility. The latter notably uses information about relative object configurations, which is invariant with respect to global transformations. Association sets are furthermore updated and expanded as the camera incrementally explores the environment and detects further objects. We test our algorithm in several challenging situations including dynamic scenes, large view-point changes, and scenes with repeated instances. Our experiments demonstrate that our approach outperforms prior art in terms of both robustness and accuracy.
CropDefender: deep watermark which is more convenient to train and more robust against cropping
Sep 12, 2021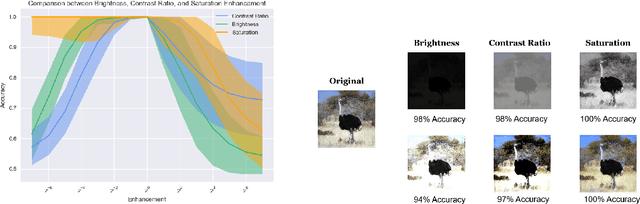
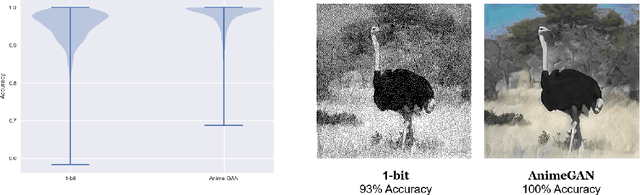
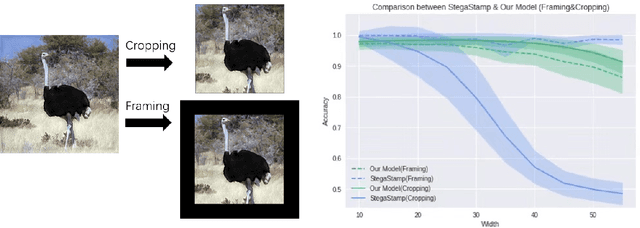
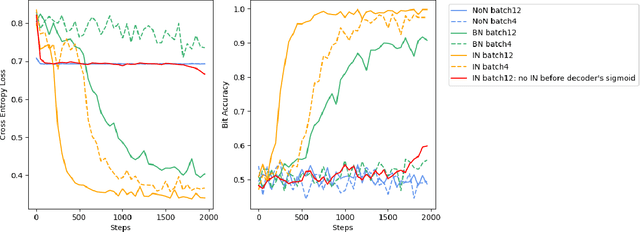
Digital image watermarking, which is a technique for invisibly embedding information into an image, is used in fields such as property rights protection. In recent years, some research has proposed the use of neural networks to add watermarks to natural images. We take StegaStamp as an example for our research. Whether facing traditional image editing methods, such as brightness, contrast, saturation adjustment, or style change like 1-bit conversion, GAN, StegaStamp has robustness far beyond traditional watermarking techniques, but it still has two drawbacks: it is vulnerable to cropping and is hard to train. We found that the causes of vulnerability to cropping is not the loss of information on the edge, but the movement of watermark position. By explicitly introducing the perturbation of cropping into the training, the cropping resistance is significantly improved. For the problem of difficult training, we introduce instance normalization to solve the vanishing gradient, set losses' weights as learnable parameters to reduce the number of hyperparameters, and use sigmoid to restrict pixel values of the generated image.
Quantified limits of the nuclear landscape
Jan 16, 2020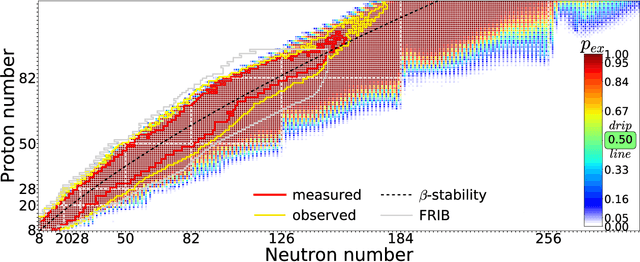
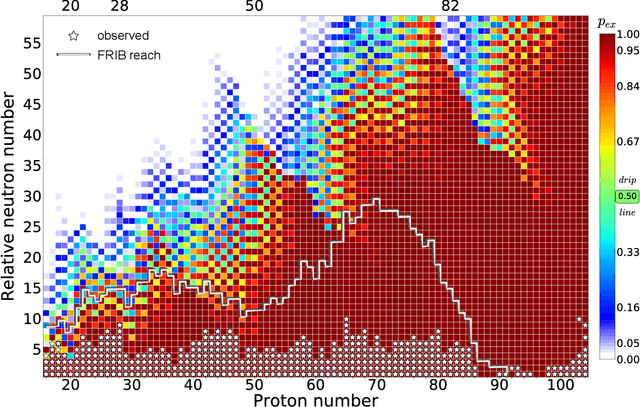
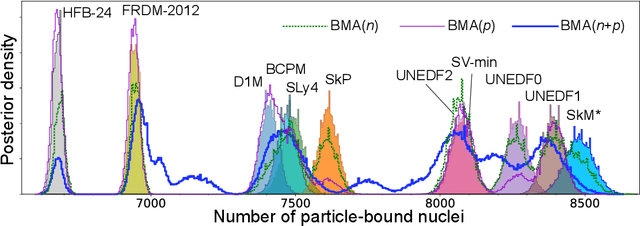

The chart of the nuclides is limited by particle drip lines beyond which nuclear stability to proton or neutron emission is lost. Predicting the range of particle-bound isotopes poses an appreciable challenge for nuclear theory as it involves extreme extrapolations of nuclear masses beyond the regions where experimental information is available. Still, quantified extrapolations are crucial for a variety of applications, including the modeling of stellar nucleosynthesis. We use microscopic nuclear mass models and Bayesian methodology to provide quantified predictions of proton and neutron separation energies as well as Bayesian probabilities of existence throughout the nuclear landscape all the way to the particle drip lines. We apply nuclear density functional theory with several energy density functionals. To account for uncertainties, Bayesian Gaussian processes are trained on the separation-energy residuals for each individual model, and the resulting predictions are combined via Bayesian model averaging. This framework allows to account for systematic and statistical uncertainties and propagate them to extrapolative predictions. We characterize the drip-line regions where the probability that the nucleus is particle-bound decreases from $1$ to $0$. In these regions, we provide quantified predictions for one- and two-nucleon separation energies. According to our Bayesian model averaging analysis, 7759 nuclei with $Z\leq 119$ have a probability of existence $\geq 0.5$. The extrapolations obtained in this study will be put through stringent tests when new experimental information on exotic nuclei becomes available. In this respect, the quantified landscape of nuclear existence obtained in this study should be viewed as a dynamical prediction that will be fine-tuned when new experimental information and improved global mass models become available.