 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing Between the Lines: Unlocking the Reasoning Power of LLMs for Speech Evaluation
Jan 24, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
Dimension-First Evaluation of Speech-to-Speech Models with Structured Acoustic Cues
Jan 20, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
Universal Semantic Disentangled Privacy-preserving Speech Representation Learning
May 19, 2025



The use of audio recordings of human speech to train LLMs poses privacy concerns due to these models' potential to generate outputs that closely resemble artifacts in the training data. In this study, we propose a speaker privacy-preserving representation learning method through the Universal Speech Codec (USC), a computationally efficient encoder-decoder model that disentangles speech into: $\textit{(i)}$ privacy-preserving semantically rich representations, capturing content and speech paralinguistics, and $\textit{(ii)}$ residual acoustic and speaker representations that enables high-fidelity reconstruction. Extensive evaluations presented show that USC's semantic representation preserves content, prosody, and sentiment, while removing potentially identifiable speaker attributes. Combining both representations, USC achieves state-of-the-art speech reconstruction. Additionally, we introduce an evaluation methodology for measuring privacy-preserving properties, aligning with perceptual tests. We compare USC against other codecs in the literature and demonstrate its effectiveness on privacy-preserving representation learning, illustrating the trade-offs of speaker anonymization, paralinguistics retention and content preservation in the learned semantic representations. Audio samples are shared in $\href{https://www.amazon.science/usc-samples}{https://www.amazon.science/usc-samples}$.
Analysis and Utilization of Entrainment on Acoustic and Emotion Features in User-agent Dialogue
Dec 07, 2022



Entrainment is the phenomenon by which an interlocutor adapts their speaking style to align with their partner in conversations. It has been found in different dimensions as acoustic, prosodic, lexical or syntactic. In this work, we explore and utilize the entrainment phenomenon to improve spoken dialogue systems for voice assistants. We first examine the existence of the entrainment phenomenon in human-to-human dialogues in respect to acoustic feature and then extend the analysis to emotion features. The analysis results show strong evidence of entrainment in terms of both acoustic and emotion features. Based on this findings, we implement two entrainment policies and assess if the integration of entrainment principle into a Text-to-Speech (TTS) system improves the synthesis performance and the user experience. It is found that the integration of the entrainment principle into a TTS system brings performance improvement when considering acoustic features, while no obvious improvement is observed when considering emotion features.
Contrastive Unsupervised Learning for Speech Emotion Recognition
Feb 12, 2021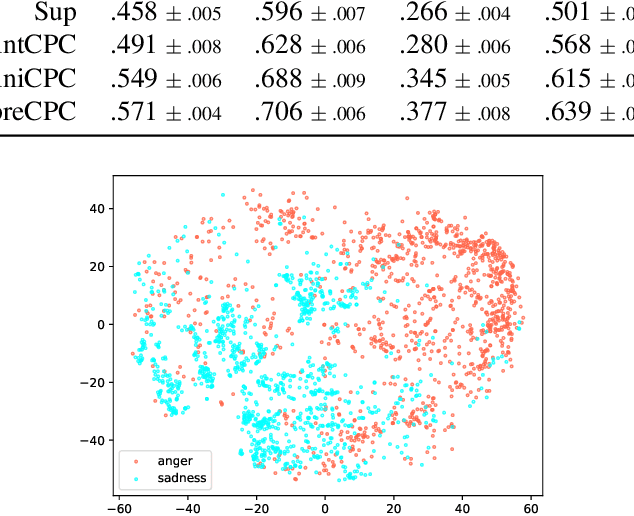

Speech emotion recognition (SER) is a key technology to enable more natural human-machine communication. However, SER has long suffered from a lack of public large-scale labeled datasets. To circumvent this problem, we investigate how unsupervised representation learning on unlabeled datasets can benefit SER. We show that the contrastive predictive coding (CPC) method can learn salient representations from unlabeled datasets, which improves emotion recognition performance. In our experiments, this method achieved state-of-the-art concordance correlation coefficient (CCC) performance for all emotion primitives (activation, valence, and dominance) on IEMOCAP. Additionally, on the MSP- Podcast dataset, our method obtained considerable performance improvements compared to baselines.