 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning robust driving policies without online exploration
Mar 15, 2021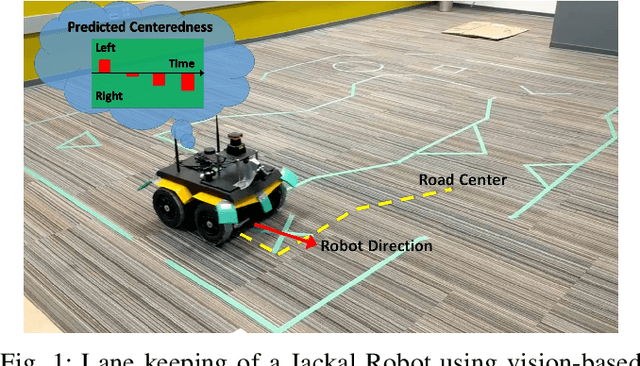
We propose a multi-time-scale predictive representation learning method to efficiently learn robust driving policies in an offline manner that generalize well to novel road geometries, and damaged and distracting lane conditions which are not covered in the offline training data. We show that our proposed representation learning method can be applied easily in an offline (batch) reinforcement learning setting demonstrating the ability to generalize well and efficiently under novel conditions compared to standard batch RL methods. Our proposed method utilizes training data collected entirely offline in the real-world which removes the need of intensive online explorations that impede applying deep reinforcement learning on real-world robot training. Various experiments were conducted in both simulator and real-world scenarios for the purpose of evaluation and analysis of our proposed claims.
Diverse Auto-Curriculum is Critical for Successful Real-World Multiagent Learning Systems
Feb 16, 2021Multiagent reinforcement learning (MARL) has achieved a remarkable amount of success in solving various types of video games. A cornerstone of this success is the auto-curriculum framework, which shapes the learning process by continually creating new challenging tasks for agents to adapt to, thereby facilitating the acquisition of new skills. In order to extend MARL methods to real-world domains outside of video games, we envision in this blue sky paper that maintaining a diversity-aware auto-curriculum is critical for successful MARL applications. Specifically, we argue that \emph{behavioural diversity} is a pivotal, yet under-explored, component for real-world multiagent learning systems, and that significant work remains in understanding how to design a diversity-aware auto-curriculum. We list four open challenges for auto-curriculum techniques, which we believe deserve more attention from this community. Towards validating our vision, we recommend modelling realistic interactive behaviours in autonomous driving as an important test bed, and recommend the SMARTS/ULTRA benchmark.
LISPR: An Options Framework for Policy Reuse with Reinforcement Learning
Dec 29, 2020
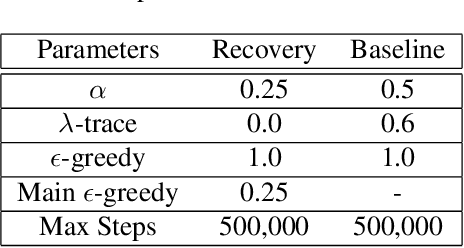
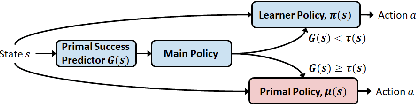
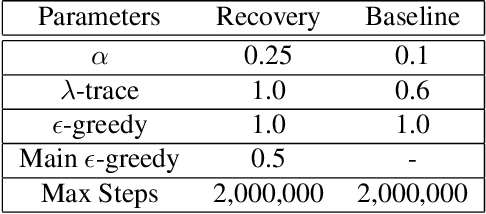
We propose a framework for transferring any existing policy from a potentially unknown source MDP to a target MDP. This framework (1) enables reuse in the target domain of any form of source policy, including classical controllers, heuristic policies, or deep neural network-based policies, (2) attains optimality under suitable theoretical conditions, and (3) guarantees improvement over the source policy in the target MDP. These are achieved by packaging the source policy as a black-box option in the target MDP and providing a theoretically grounded way to learn the option's initiation set through general value functions. Our approach facilitates the learning of new policies by (1) maximizing the target MDP reward with the help of the black-box option, and (2) returning the agent to states in the learned initiation set of the black-box option where it is already optimal. We show that these two variants are equivalent in performance under some conditions. Through a series of experiments in simulated environments, we demonstrate that our framework performs excellently in sparse reward problems given (sub-)optimal source policies and improves upon prior art in transfer methods such as continual learning and progressive networks, which lack our framework's desirable theoretical properties.
Offline Learning of Counterfactual Perception as Prediction for Real-World Robotic Reinforcement Learning
Nov 11, 2020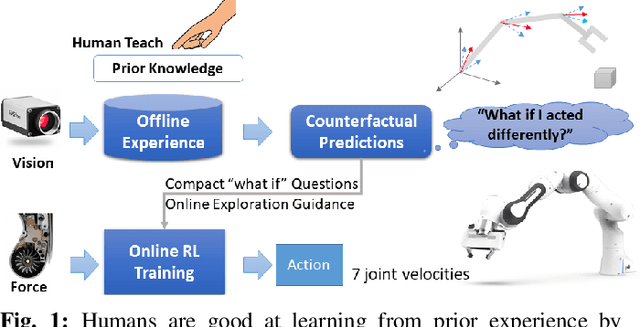
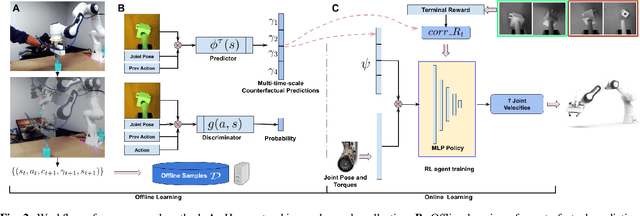
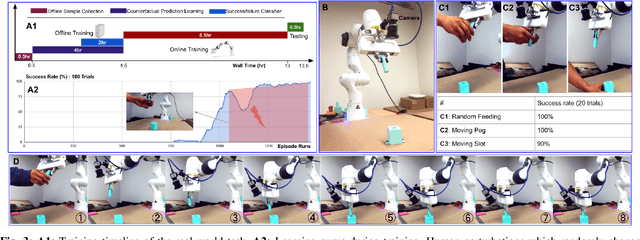

We propose a method for offline learning of counterfactual predictions to address real world robotic reinforcement learning challenges. The proposed method encodes action-oriented visual observations as several "what if" questions learned offline from prior experience using reinforcement learning methods. These "what if" questions counterfactually predict how action-conditioned observation would evolve on multiple temporal scales if the agent were to stick to its current action. We show that combining these offline counterfactual predictions along with online in-situ observations (e.g. force feedback) allows efficient policy learning with only a sparse terminal (success/failure) reward. We argue that the learned predictions form an effective representation of the visual task, and guide the online exploration towards high-potential success interactions (e.g. contact-rich regions). Experiments were conducted in both simulation and real-world scenarios for evaluation. Our results demonstrate that it is practical to train a reinforcement learning agent to perform real-world fine manipulation in about half a day, without hand engineered perception systems or calibrated instrumentation. Recordings of the real robot training can be found via https://sites.google.com/view/realrl.
SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving
Nov 01, 2020
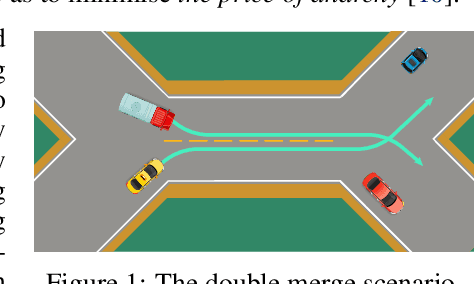
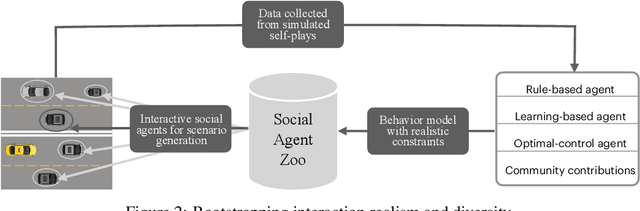
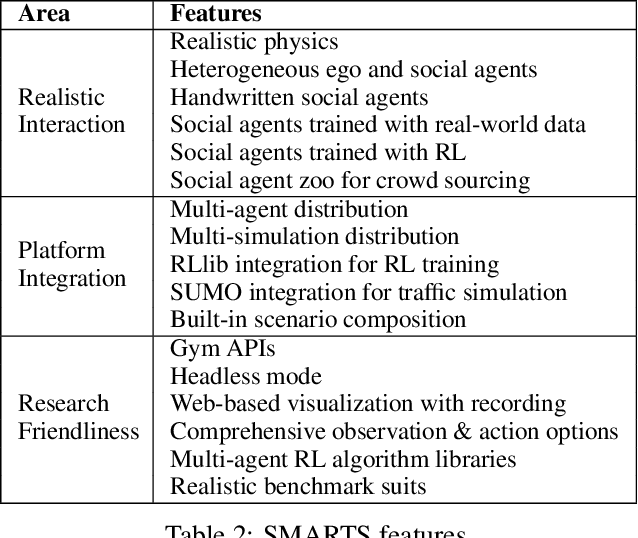
Multi-agent interaction is a fundamental aspect of autonomous driving in the real world. Despite more than a decade of research and development, the problem of how to competently interact with diverse road users in diverse scenarios remains largely unsolved. Learning methods have much to offer towards solving this problem. But they require a realistic multi-agent simulator that generates diverse and competent driving interactions. To meet this need, we develop a dedicated simulation platform called SMARTS (Scalable Multi-Agent RL Training School). SMARTS supports the training, accumulation, and use of diverse behavior models of road users. These are in turn used to create increasingly more realistic and diverse interactions that enable deeper and broader research on multi-agent interaction. In this paper, we describe the design goals of SMARTS, explain its basic architecture and its key features, and illustrate its use through concrete multi-agent experiments on interactive scenarios. We open-source the SMARTS platform and the associated benchmark tasks and evaluation metrics to encourage and empower research on multi-agent learning for autonomous driving. Our code is available at https://github.com/huawei-noah/SMARTS.
Affordance as general value function: A computational model
Oct 27, 2020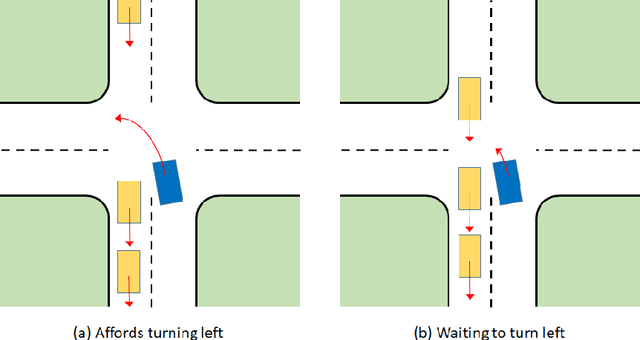
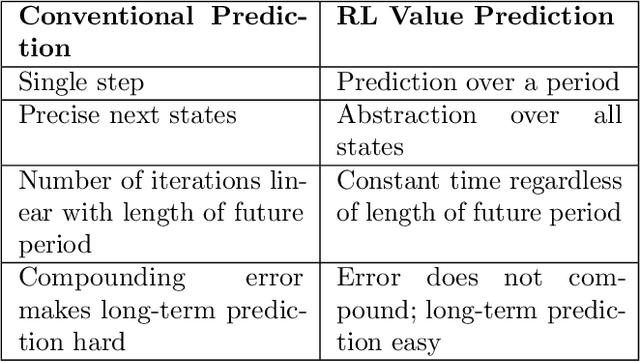
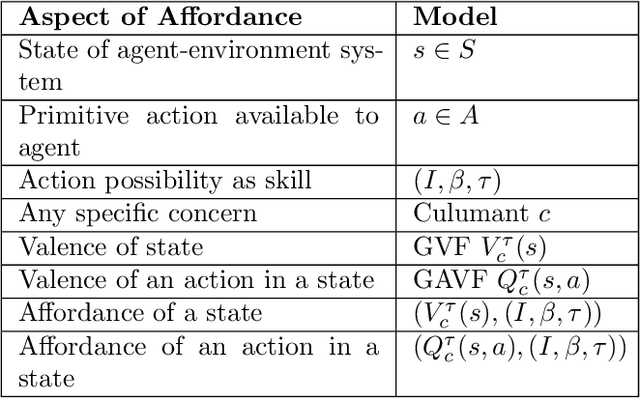

General value functions (GVFs) in the reinforcement learning (RL) literature are long-term predictive summaries of the outcomes of agents following specific policies in the environment. Affordances as perceived valences of action possibilities may be cast into predicted policy-relative goodness and modelled as GVFs. A systematic explication of this connection shows that GVFs and especially their deep learning embodiments (1) realize affordance prediction as a form of direct perception, (2) illuminate the fundamental connection between action and perception in affordance, and (3) offer a scalable way to learn affordances using RL methods. Through a comprehensive review of existing literature on recent successes of GVF applications in robotics, rehabilitation, industrial automation, and autonomous driving, we demonstrate that GVFs provide the right framework for learning affordances in real-world applications. In addition, we highlight a few new avenues of research opened up by the perspective of "affordance as GVF", including using GVFs for orchestrating complex behaviors.
What About Taking Policy as Input of Value Function: Policy-extended Value Function Approximator
Oct 19, 2020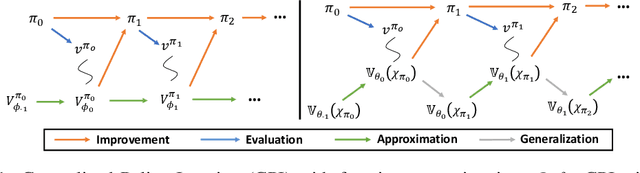

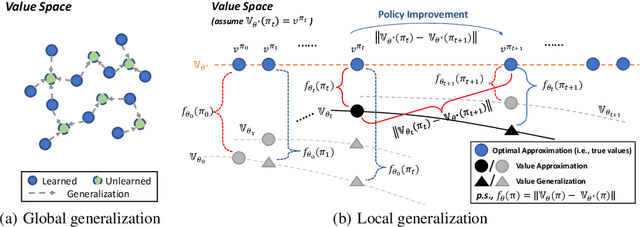
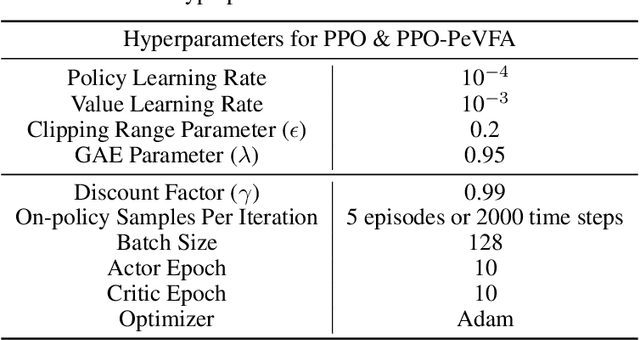
The value function lies in the heart of Reinforcement Learning (RL), which defines the long-term evaluation of a policy in a given state. In this paper, we propose Policy-extended Value Function Approximator (PeVFA) which extends the conventional value to be not only a function of state but also an explicit policy representation. Such an extension enables PeVFA to preserve values of multiple policies in contrast to a conventional one with limited capacity for only one policy, inducing the new characteristic of \emph{value generalization among policies}. From both the theoretical and empirical lens, we study value generalization along the policy improvement path (called local generalization), from which we derive a new form of Generalized Policy Iteration with PeVFA to improve the conventional learning process. Besides, we propose a framework to learn the representation of an RL policy, studying several different approaches to learn an effective policy representation from policy network parameters and state-action pairs through contrastive learning and action prediction. In our experiments, Proximal Policy Optimization (PPO) with PeVFA significantly outperforms its vanilla counterpart in MuJoCo continuous control tasks, demonstrating the effectiveness of value generalization offered by PeVFA and policy representation learning.
Learning predictive representations in autonomous driving to improve deep reinforcement learning
Jun 26, 2020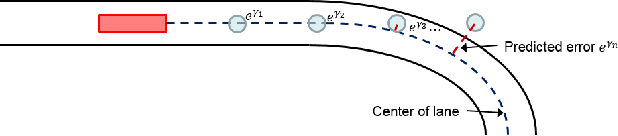
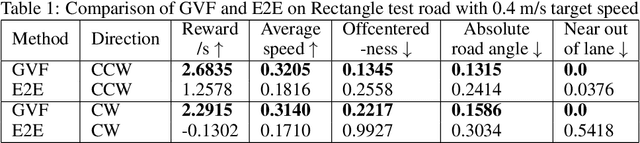

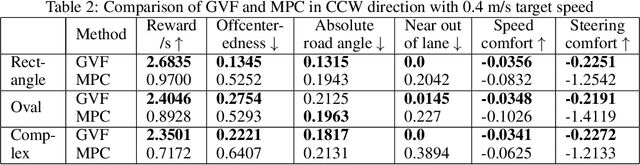
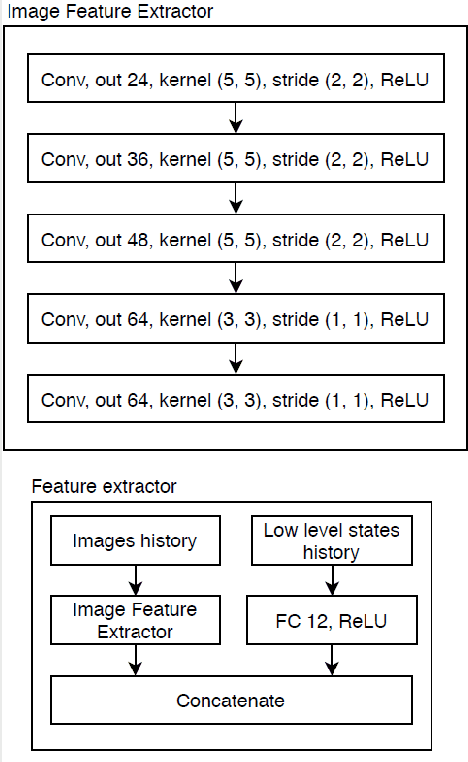
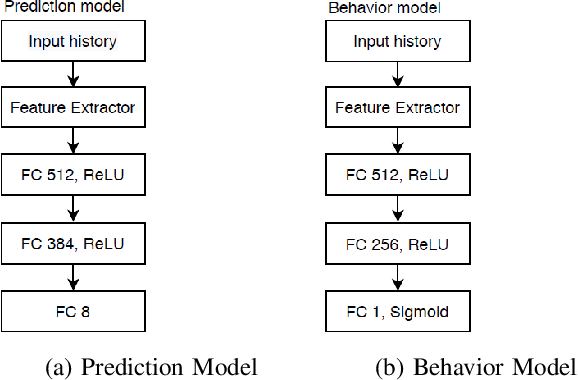
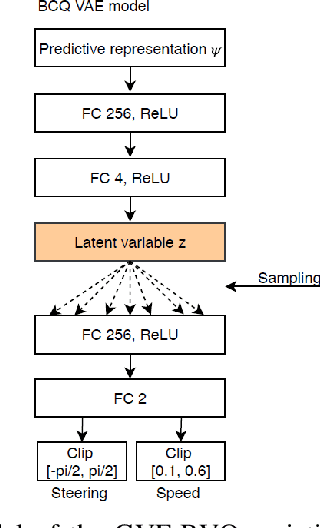
Reinforcement learning using a novel predictive representation is applied to autonomous driving to accomplish the task of driving between lane markings where substantial benefits in performance and generalization are observed on unseen test roads in both simulation and on a real Jackal robot. The novel predictive representation is learned by general value functions (GVFs) to provide out-of-policy, or counter-factual, predictions of future lane centeredness and road angle that form a compact representation of the state of the agent improving learning in both online and offline reinforcement learning to learn to drive an autonomous vehicle with methods that generalizes well to roads not in the training data. Experiments in both simulation and the real-world demonstrate that predictive representations in reinforcement learning improve learning efficiency, smoothness of control and generalization to roads that the agent was never shown during training, including damaged lane markings. It was found that learning a predictive representation that consists of several predictions over different time scales, or discount factors, improves the performance and smoothness of the control substantially. The Jackal robot was trained in a two step process where the predictive representation is learned first followed by a batch reinforcement learning algorithm (BCQ) from data collected through both automated and human-guided exploration in the environment. We conclude that out-of-policy predictive representations with GVFs offer reinforcement learning many benefits in real-world problems.
Perception as prediction using general value functions in autonomous driving applications
Jan 24, 2020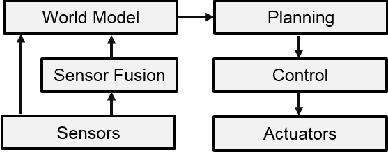
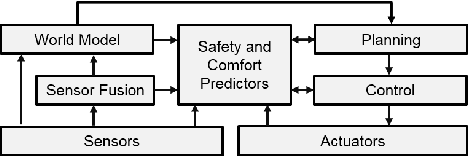
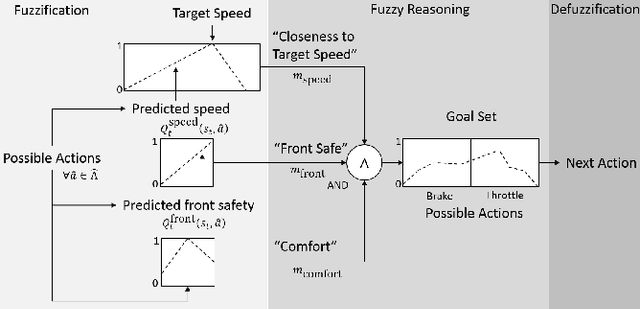
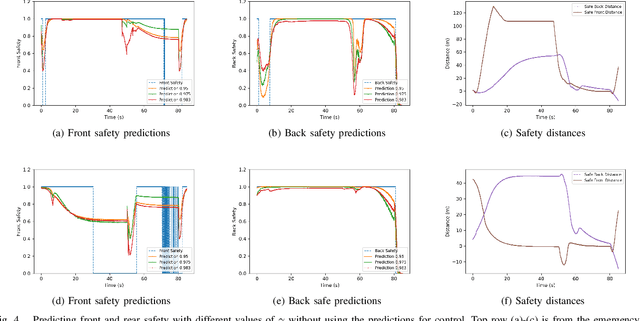
We propose and demonstrate a framework called perception as prediction for autonomous driving that uses general value functions (GVFs) to learn predictions. Perception as prediction learns data-driven predictions relating to the impact of actions on the agent's perception of the world. It also provides a data-driven approach to predict the impact of the anticipated behavior of other agents on the world without explicitly learning their policy or intentions. We demonstrate perception as prediction by learning to predict an agent's front safety and rear safety with GVFs, which encapsulate anticipation of the behavior of the vehicle in front and in the rear, respectively. The safety predictions are learned through random interactions in a simulated environment containing other agents. We show that these predictions can be used to produce similar control behavior to an LQR-based controller in an adaptive cruise control problem as well as provide advanced warning when the vehicle behind is approaching dangerously. The predictions are compact policy-based predictions that support prediction of the long term impact on safety when following a given policy. We analyze two controllers that use the learned predictions in a racing simulator to understand the value of the predictions and demonstrate their use in the real-world on a Clearpath Jackal robot and an autonomous vehicle platform.
Efficient decorrelation of features using Gramian in Reinforcement Learning
Nov 19, 2019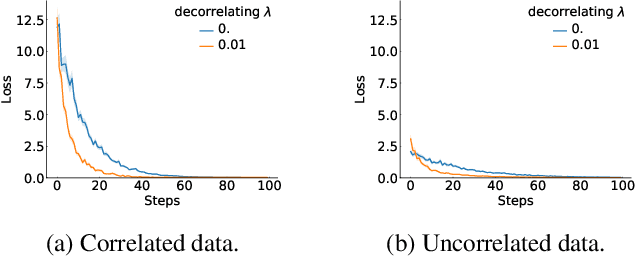
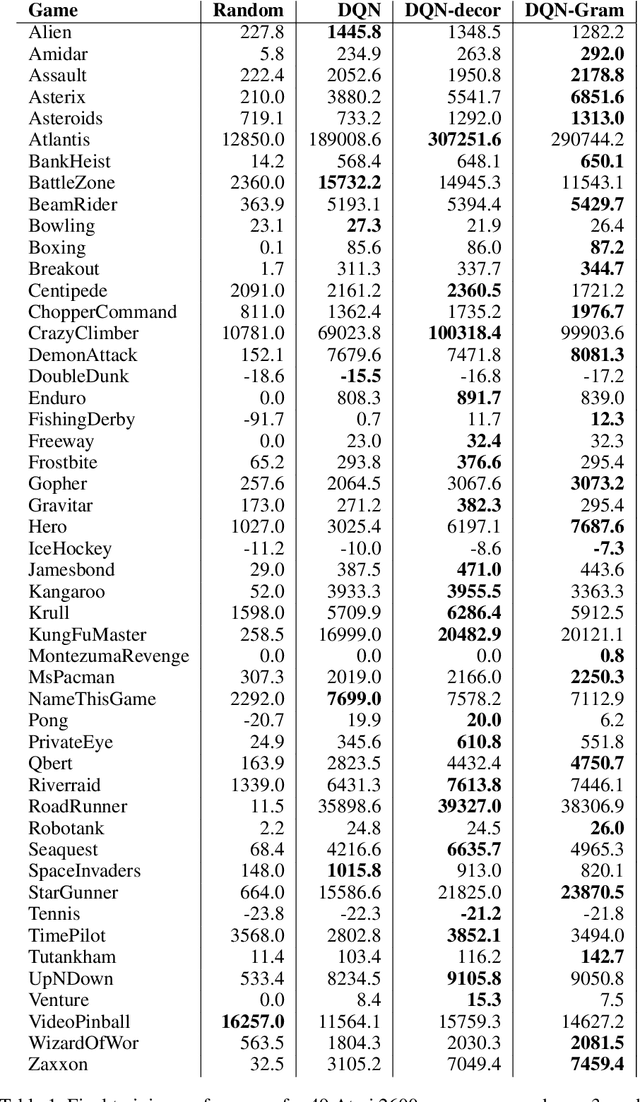
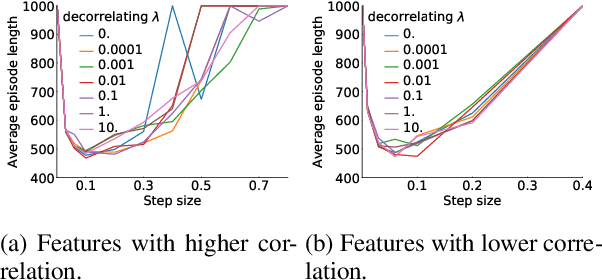
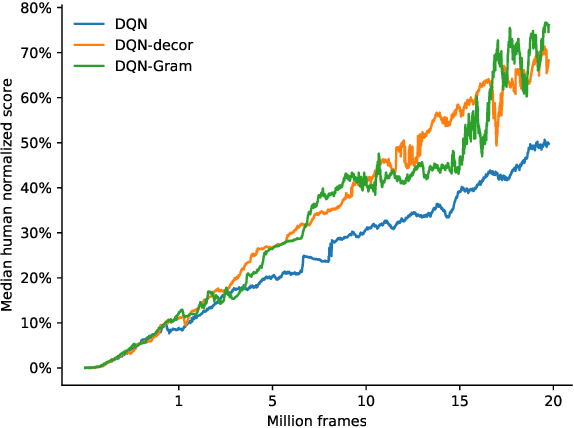
Learning good representations is a long standing problem in reinforcement learning (RL). One of the conventional ways to achieve this goal in the supervised setting is through regularization of the parameters. Extending some of these ideas to the RL setting has not yielded similar improvements in learning. In this paper, we develop an online regularization framework for decorrelating features in RL and demonstrate its utility in several test environments. We prove that the proposed algorithm converges in the linear function approximation setting and does not change the main objective of maximizing cumulative reward. We demonstrate how to scale the approach to deep RL using the Gramian of the features achieving linear computational complexity in the number of features and squared complexity in size of the batch. We conduct an extensive empirical study of the new approach on Atari 2600 games and show a significant improvement in sample efficiency in 40 out of 49 games.