 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Geometric Representations of Objects via Interaction
Sep 11, 2023



We address the problem of learning representations from observations of a scene involving an agent and an external object the agent interacts with. To this end, we propose a representation learning framework extracting the location in physical space of both the agent and the object from unstructured observations of arbitrary nature. Our framework relies on the actions performed by the agent as the only source of supervision, while assuming that the object is displaced by the agent via unknown dynamics. We provide a theoretical foundation and formally prove that an ideal learner is guaranteed to infer an isometric representation, disentangling the agent from the object and correctly extracting their locations. We evaluate empirically our framework on a variety of scenarios, showing that it outperforms vision-based approaches such as a state-of-the-art keypoint extractor. We moreover demonstrate how the extracted representations enable the agent to solve downstream tasks via reinforcement learning in an efficient manner.
Enabling Robot Manipulation of Soft and Rigid Objects with Vision-based Tactile Sensors
Jun 09, 2023



Endowing robots with tactile capabilities opens up new possibilities for their interaction with the environment, including the ability to handle fragile and/or soft objects. In this work, we equip the robot gripper with low-cost vision-based tactile sensors and propose a manipulation algorithm that adapts to both rigid and soft objects without requiring any knowledge of their properties. The algorithm relies on a touch and slip detection method, which considers the variation in the tactile images with respect to reference ones. We validate the approach on seven different objects, with different properties in terms of rigidity and fragility, to perform unplugging and lifting tasks. Furthermore, to enhance applicability, we combine the manipulation algorithm with a grasp sampler for the task of finding and picking a grape from a bunch without damaging~it.
TD-GEM: Text-Driven Garment Editing Mapper
May 29, 2023Language-based fashion image editing allows users to try out variations of desired garments through provided text prompts. Inspired by research on manipulating latent representations in StyleCLIP and HairCLIP, we focus on these latent spaces for editing fashion items of full-body human datasets. Currently, there is a gap in handling fashion image editing due to the complexity of garment shapes and textures and the diversity of human poses. In this paper, we propose an editing optimizer scheme method called Text-Driven Garment Editing Mapper (TD-GEM), aiming to edit fashion items in a disentangled way. To this end, we initially obtain a latent representation of an image through generative adversarial network inversions such as Encoder for Editing (e4e) or Pivotal Tuning Inversion (PTI) for more accurate results. An optimization-based Contrasive Language-Image Pre-training (CLIP) is then utilized to guide the latent representation of a fashion image in the direction of a target attribute expressed in terms of a text prompt. Our TD-GEM manipulates the image accurately according to the target attribute, while other parts of the image are kept untouched. In the experiments, we evaluate TD-GEM on two different attributes (i.e., "color" and "sleeve length"), which effectively generates realistic images compared to the recent manipulation schemes.
A Virtual Reality Framework for Human-Robot Collaboration in Cloth Folding
May 12, 2023We present a virtual reality (VR) framework to automate the data collection process in cloth folding tasks. The framework uses skeleton representations to help the user define the folding plans for different classes of garments, allowing for replicating the folding on unseen items of the same class. We evaluate the framework in the context of automating garment folding tasks. A quantitative analysis is performed on 3 classes of garments, demonstrating that the framework reduces the need for intervention by the user. We also compare skeleton representations with RGB and binary images in a classification task on a large dataset of clothing items, motivating the use of the framework for other classes of garments.
Controllable Motion Synthesis and Reconstruction with Autoregressive Diffusion Models
Apr 03, 2023



Data-driven and controllable human motion synthesis and prediction are active research areas with various applications in interactive media and social robotics. Challenges remain in these fields for generating diverse motions given past observations and dealing with imperfect poses. This paper introduces MoDiff, an autoregressive probabilistic diffusion model over motion sequences conditioned on control contexts of other modalities. Our model integrates a cross-modal Transformer encoder and a Transformer-based decoder, which are found effective in capturing temporal correlations in motion and control modalities. We also introduce a new data dropout method based on the diffusion forward process to provide richer data representations and robust generation. We demonstrate the superior performance of MoDiff in controllable motion synthesis for locomotion with respect to two baselines and show the benefits of diffusion data dropout for robust synthesis and reconstruction of high-fidelity motion close to recorded data.
Ensemble Latent Space Roadmap for Improved Robustness in Visual Action Planning
Mar 27, 2023



Planning in learned latent spaces helps to decrease the dimensionality of raw observations. In this work, we propose to leverage the ensemble paradigm to enhance the robustness of latent planning systems. We rely on our Latent Space Roadmap (LSR) framework, which builds a graph in a learned structured latent space to perform planning. Given multiple LSR framework instances, that differ either on their latent spaces or on the parameters for constructing the graph, we use the action information as well as the embedded nodes of the produced plans to define similarity measures. These are then utilized to select the most promising plans. We validate the performance of our Ensemble LSR (ENS-LSR) on simulated box stacking and grape harvesting tasks as well as on a real-world robotic T-shirt folding experiment.
GoNet: An Approach-Constrained Generative Grasp Sampling Network
Mar 14, 2023Constraining the approach direction of grasps is important when picking objects in confined spaces, such as when emptying a shelf. Yet, such capabilities are not available in state-of-the-art data-driven grasp sampling methods that sample grasps all around the object. In this work, we address the specific problem of training approach-constrained data-driven grasp samplers and how to generate good grasping directions automatically. Our solution is GoNet: a generative grasp sampler that can constrain the grasp approach direction to lie close to a specified direction. This is achieved by discretizing SO(3) into bins and training GoNet to generate grasps from those bins. At run-time, the bin aligning with the second largest principal component of the observed point cloud is selected. GoNet is benchmarked against GraspNet, a state-of-the-art unconstrained grasp sampler, in an unconfined grasping experiment in simulation and on an unconfined and confined grasping experiment in the real world. The results demonstrate that GoNet achieves higher success-over-coverage in simulation and a 12%-18% higher success rate in real-world table-picking and shelf-picking tasks than the baseline.
Equivariant Representations for Non-Free Group Actions
Jan 12, 2023We introduce a method for learning representations that are equivariant with respect to general group actions over data. Differently from existing equivariant representation learners, our method is suitable for actions that are not free i.e., that stabilize data via nontrivial symmetries. Our method is grounded in the orbit-stabilizer theorem from group theory, which guarantees that an ideal learner infers an isomorphic representation. Finally, we provide an empirical investigation on image datasets with rotational symmetries and show that taking stabilizers into account improves the quality of the representations.
EDO-Net: Learning Elastic Properties of Deformable Objects from Graph Dynamics
Sep 19, 2022
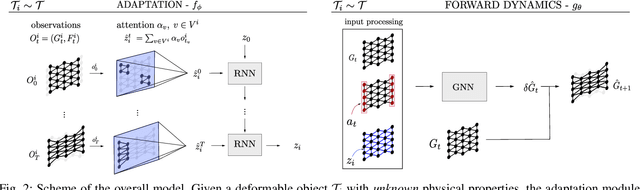
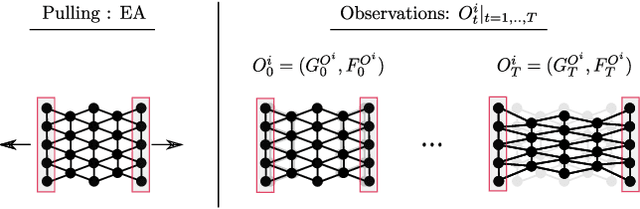
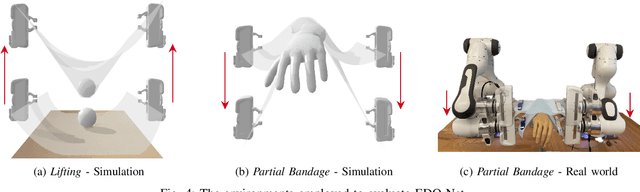
We study the problem of learning graph dynamics of deformable objects which generalize to unknown physical properties. In particular, we leverage a latent representation of elastic physical properties of cloth-like deformable objects which we explore through a pulling interaction. We propose EDO-Net (Elastic Deformable Object - Net), a model trained in a self-supervised fashion on a large variety of samples with different elastic properties. EDO-Net jointly learns an adaptation module, responsible for extracting a latent representation of the physical properties of the object, and a forward-dynamics module, which leverages the latent representation to predict future states of cloth-like objects, represented as graphs. We evaluate EDO-Net both in simulation and real world, assessing its capabilities of: 1) generalizing to unknown physical properties of cloth-like deformable objects, 2) transferring the learned representation to new downstream tasks.
Elastic Context: Encoding Elasticity for Data-driven Models of Textiles
Sep 19, 2022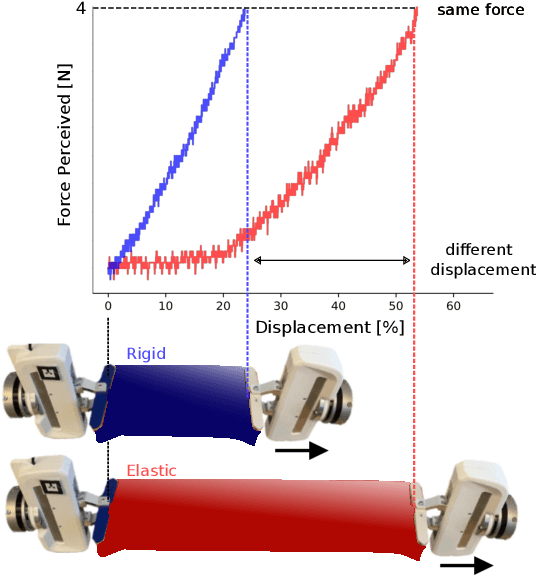
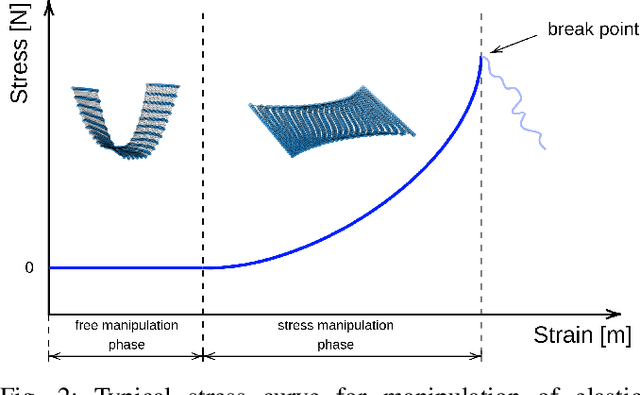
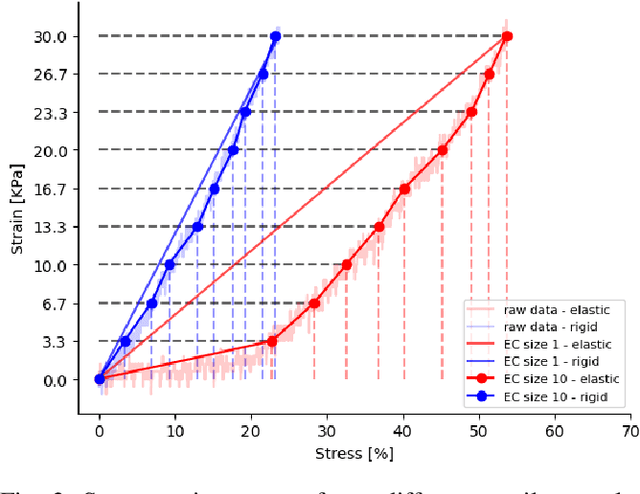
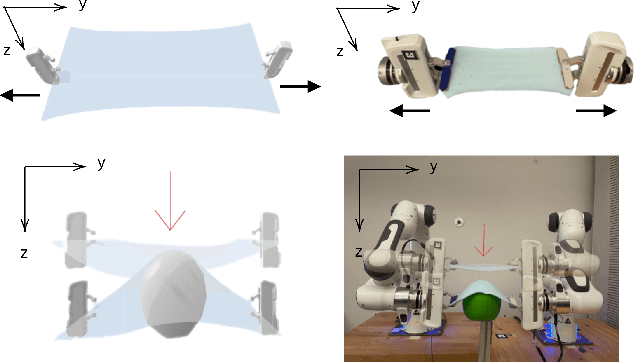
Physical interaction with textiles, such as assistive dressing, relies on advanced dextreous capabilities. The underlying complexity in textile behavior when being pulled and stretched, is due to both the yarn material properties and the textile construction technique. Today, there are no commonly adopted and annotated datasets on which the various interaction or property identification methods are assessed. One important property that affects the interaction is material elasticity that results from both the yarn material and construction technique: these two are intertwined and, if not known a-priori, almost impossible to identify through sensing commonly available on robotic platforms. We introduce Elastic Context (EC), a concept that integrates various properties that affect elastic behavior, to enable a more effective physical interaction with textiles. The definition of EC relies on stress/strain curves commonly used in textile engineering, which we reformulated for robotic applications. We employ EC using Graph Neural Network (GNN) to learn generalized elastic behaviors of textiles. Furthermore, we explore the effect the dimension of the EC has on accurate force modeling of non-linear real-world elastic behaviors, highlighting the challenges of current robotic setups to sense textile properties.