 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Hallucination in Natural Language Generation
Feb 08, 2022
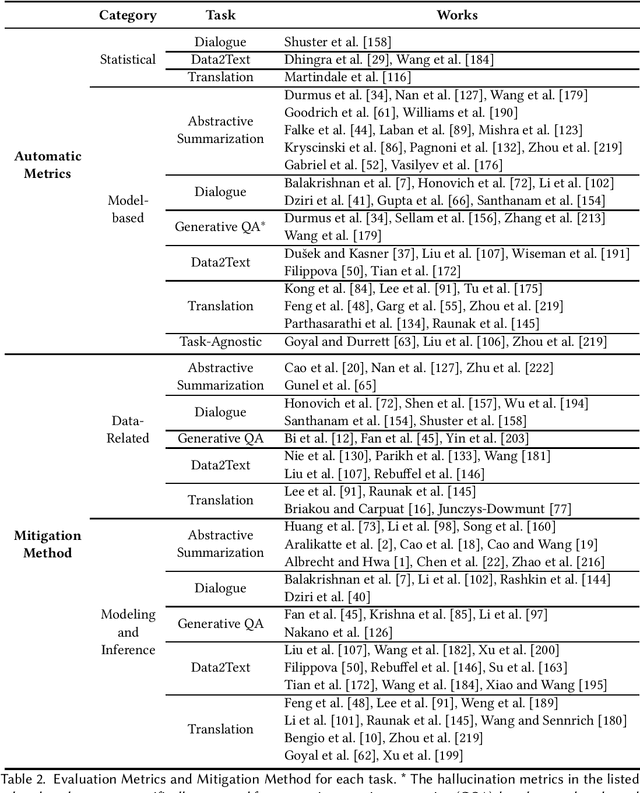
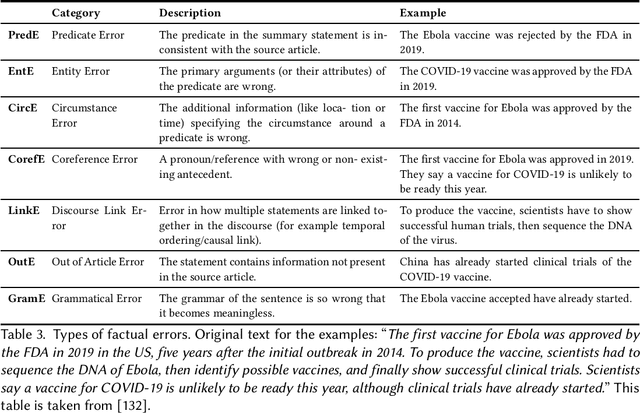
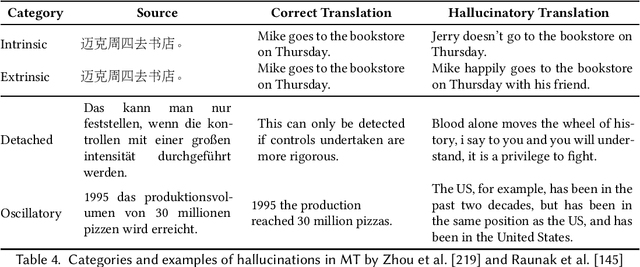
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent natural language generation, naturally leading to development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also investigated that such generation includes hallucinated texts, which makes the performances of text generation fail to meet users' expectations in many real-world scenarios. In order to address this issue, studies in evaluation and mitigation methods of hallucinations have been presented in various tasks, but have not been reviewed in a combined manner. In this survey, we provide a broad overview of the research progress and challenges in the hallucination problem of NLG. The survey is organized into two big divisions: (i) a general overview of metrics, mitigation methods, and future directions; (ii) task-specific research progress for hallucinations in a large set of downstream tasks: abstractive summarization, dialogue generation, generative question answering, data-to-text generation, and machine translation. This survey could facilitate collaborative efforts among researchers in these tasks.
The CUHK-TENCENT speaker diarization system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 04, 2022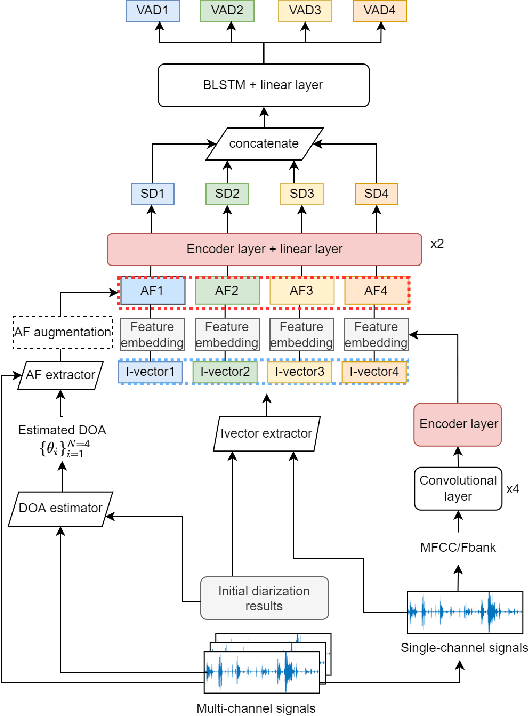
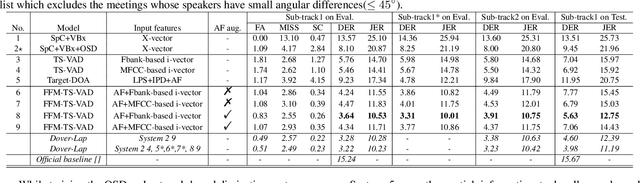
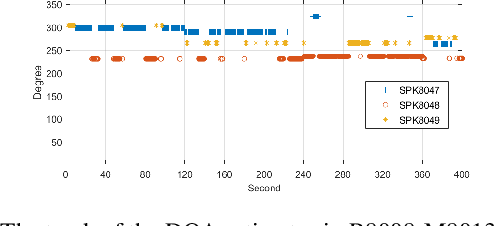
This paper describes our speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription (M2MeT) challenge, where Mandarin meeting data were recorded in multi-channel format for diarization and automatic speech recognition (ASR) tasks. In these meeting scenarios, the uncertainty of the speaker number and the high ratio of overlapped speech present great challenges for diarization. Based on the assumption that there is valuable complementary information between acoustic features, spatial-related and speaker-related features, we propose a multi-level feature fusion mechanism based target-speaker voice activity detection (FFM-TS-VAD) system to improve the performance of the conventional TS-VAD system. Furthermore, we propose a data augmentation method during training to improve the system robustness when the angular difference between two speakers is relatively small. We provide comparisons for different sub-systems we used in M2MeT challenge. Our submission is a fusion of several sub-systems and ranks second in the diarization task.
DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
Jan 28, 2022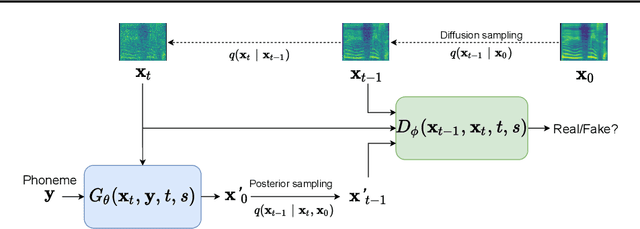
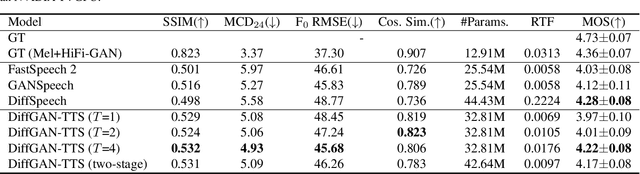
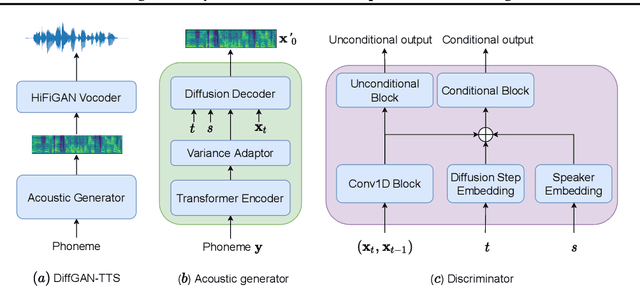
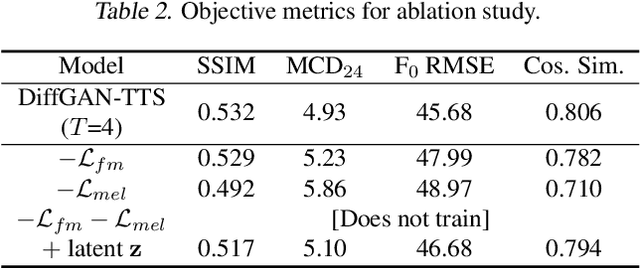
Denoising diffusion probabilistic models (DDPMs) are expressive generative models that have been used to solve a variety of speech synthesis problems. However, because of their high sampling costs, DDPMs are difficult to use in real-time speech processing applications. In this paper, we introduce DiffGAN-TTS, a novel DDPM-based text-to-speech (TTS) model achieving high-fidelity and efficient speech synthesis. DiffGAN-TTS is based on denoising diffusion generative adversarial networks (GANs), which adopt an adversarially-trained expressive model to approximate the denoising distribution. We show with multi-speaker TTS experiments that DiffGAN-TTS can generate high-fidelity speech samples within only 4 denoising steps. We present an active shallow diffusion mechanism to further speed up inference. A two-stage training scheme is proposed, with a basic TTS acoustic model trained at stage one providing valuable prior information for a DDPM trained at stage two. Our experiments show that DiffGAN-TTS can achieve high synthesis performance with only 1 denoising step.
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 30, 2021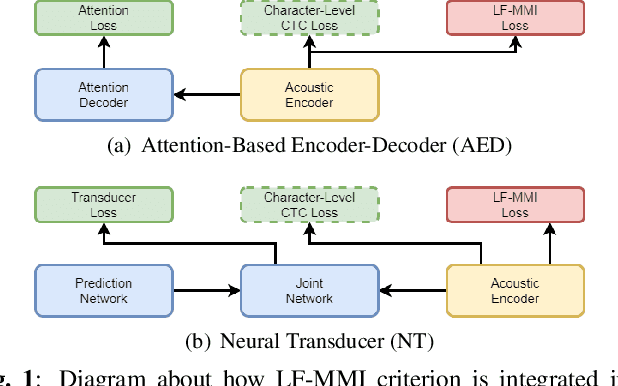
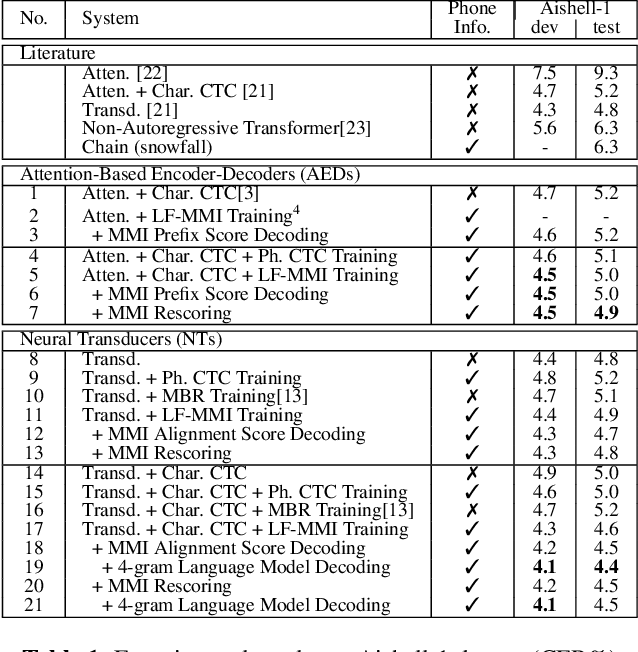
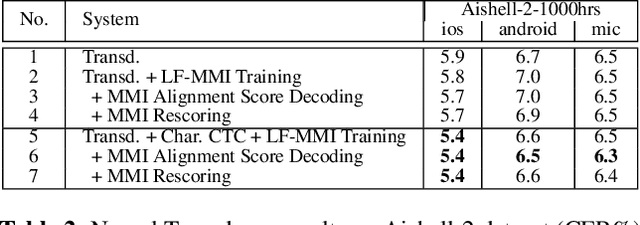
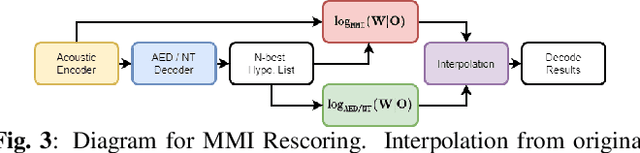
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
SpeechMoE2: Mixture-of-Experts Model with Improved Routing
Nov 23, 2021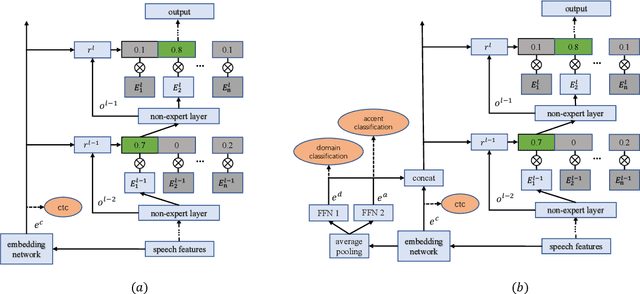
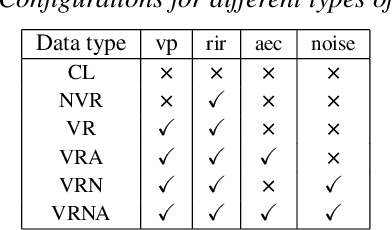
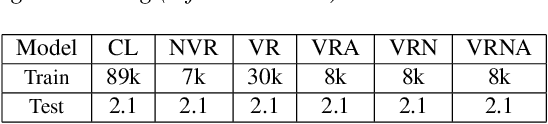
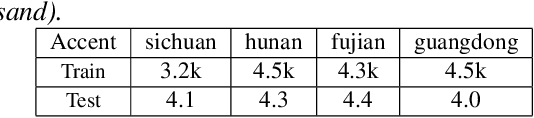
Mixture-of-experts based acoustic models with dynamic routing mechanisms have proved promising results for speech recognition. The design principle of router architecture is important for the large model capacity and high computational efficiency. Our previous work SpeechMoE only uses local grapheme embedding to help routers to make route decisions. To further improve speech recognition performance against varying domains and accents, we propose a new router architecture which integrates additional global domain and accent embedding into router input to promote adaptability. Experimental results show that the proposed SpeechMoE2 can achieve lower character error rate (CER) with comparable parameters than SpeechMoE on both multi-domain and multi-accent task. Primarily, the proposed method provides up to 1.6% - 4.8% relative CER improvement for the multidomain task and 1.9% - 17.7% relative CER improvement for the multi-accent task respectively. Besides, increasing the number of experts also achieves consistent performance improvement and keeps the computational cost constant.
Meta-Voice: Fast few-shot style transfer for expressive voice cloning using meta learning
Nov 14, 2021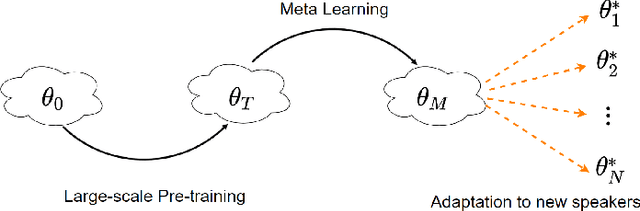
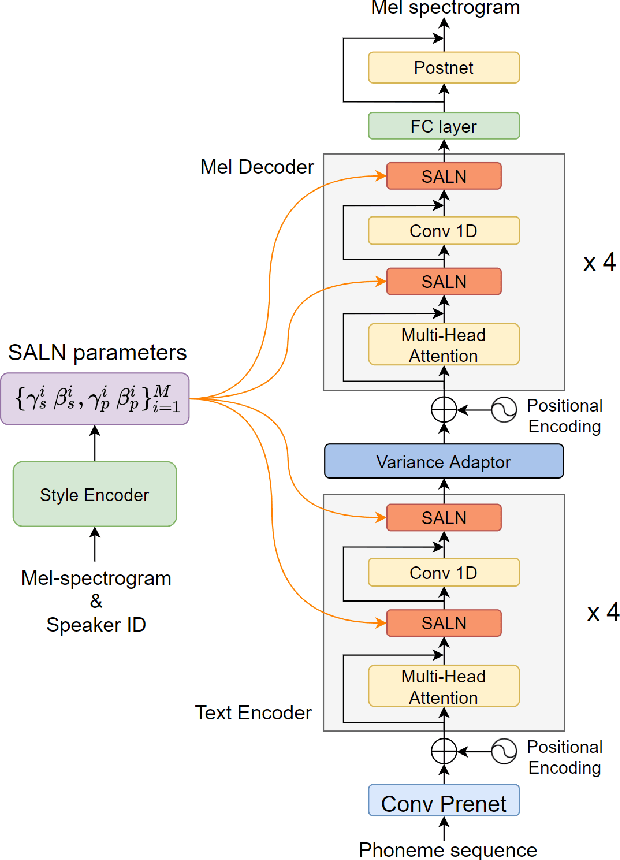
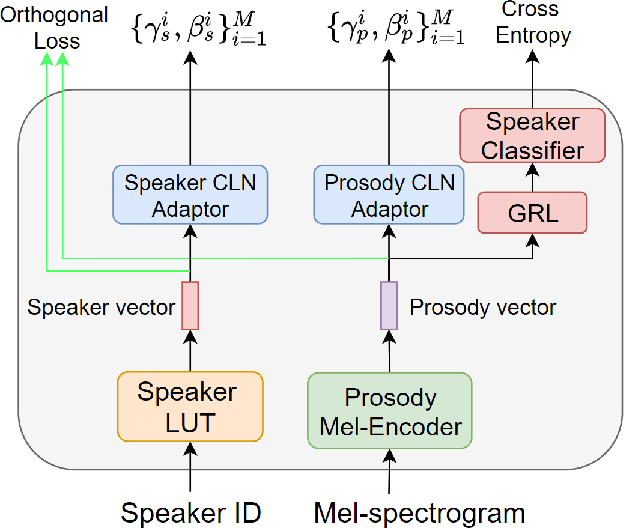
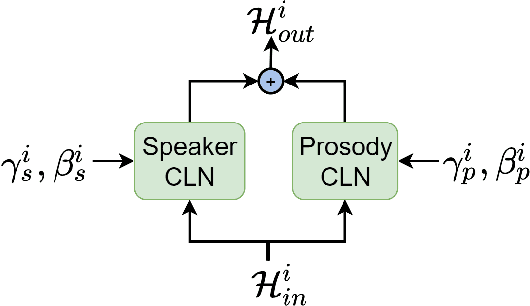
The task of few-shot style transfer for voice cloning in text-to-speech (TTS) synthesis aims at transferring speaking styles of an arbitrary source speaker to a target speaker's voice using very limited amount of neutral data. This is a very challenging task since the learning algorithm needs to deal with few-shot voice cloning and speaker-prosody disentanglement at the same time. Accelerating the adaptation process for a new target speaker is of importance in real-world applications, but even more challenging. In this paper, we approach to the hard fast few-shot style transfer for voice cloning task using meta learning. We investigate the model-agnostic meta-learning (MAML) algorithm and meta-transfer a pre-trained multi-speaker and multi-prosody base TTS model to be highly sensitive for adaptation with few samples. Domain adversarial training mechanism and orthogonal constraint are adopted to disentangle speaker and prosody representations for effective cross-speaker style transfer. Experimental results show that the proposed approach is able to conduct fast voice cloning using only 5 samples (around 12 second speech data) from a target speaker, with only 100 adaptation steps. Audio samples are available online.
Simple Attention Module based Speaker Verification with Iterative noisy label detection
Oct 13, 2021
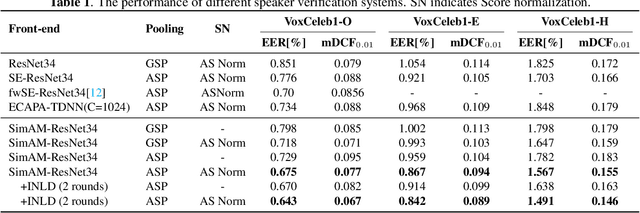
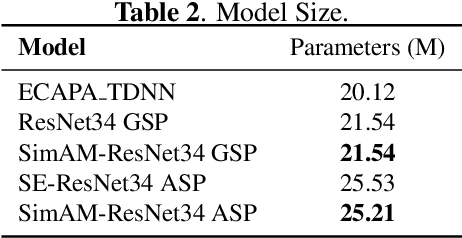
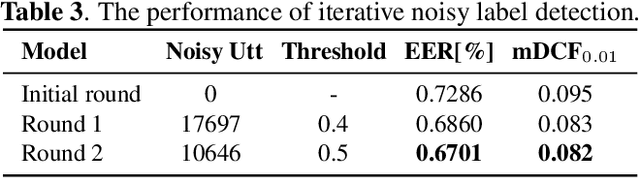
Recently, the attention mechanism such as squeeze-and-excitation module (SE) and convolutional block attention module (CBAM) has achieved great success in deep learning-based speaker verification system. This paper introduces an alternative effective yet simple one, i.e., simple attention module (SimAM), for speaker verification. The SimAM module is a plug-and-play module without extra modal parameters. In addition, we propose a noisy label detection method to iteratively filter out the data samples with a noisy label from the training data, considering that a large-scale dataset labeled with human annotation or other automated processes may contain noisy labels. Data with the noisy label may over parameterize a deep neural network (DNN) and result in a performance drop due to the memorization effect of the DNN. Experiments are conducted on VoxCeleb dataset. The speaker verification model with SimAM achieves the 0.675% equal error rate (EER) on VoxCeleb1 original test trials. Our proposed iterative noisy label detection method further reduces the EER to 0.643%.
AppQ: Warm-starting App Recommendation Based on View Graphs
Sep 08, 2021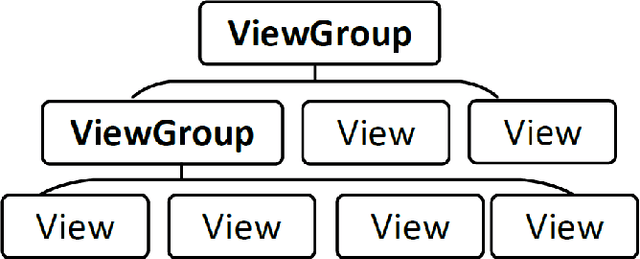
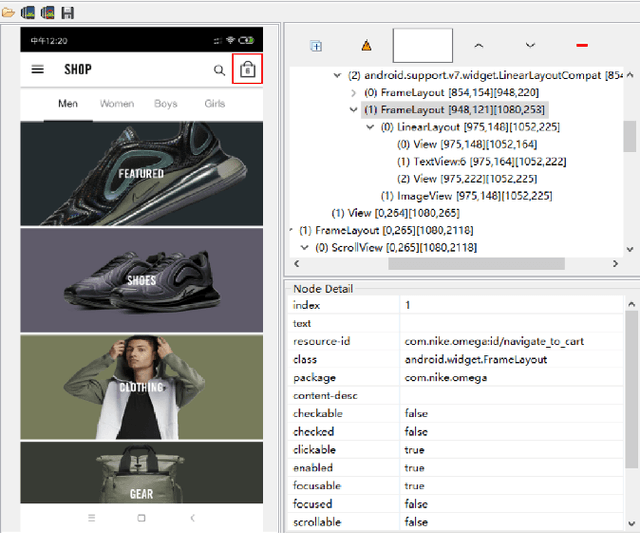
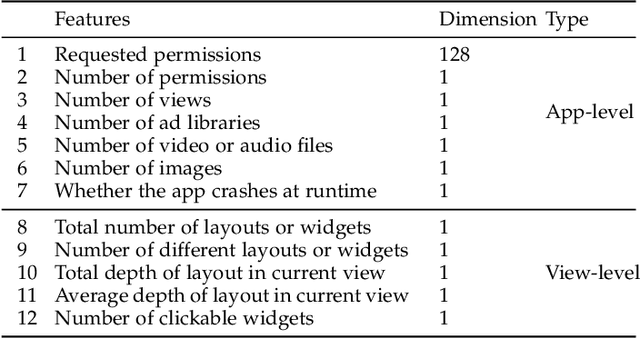
Current app ranking and recommendation systems are mainly based on user-generated information, e.g., number of downloads and ratings. However, new apps often have few (or even no) user feedback, suffering from the classic cold-start problem. How to quickly identify and then recommend new apps of high quality is a challenging issue. Here, a fundamental requirement is the capability to accurately measure an app's quality based on its inborn features, rather than user-generated features. Since users obtain first-hand experience of an app by interacting with its views, we speculate that the inborn features are largely related to the visual quality of individual views in an app and the ways the views switch to one another. In this work, we propose AppQ, a novel app quality grading and recommendation system that extracts inborn features of apps based on app source code. In particular, AppQ works in parallel to perform code analysis to extract app-level features as well as dynamic analysis to capture view-level layout hierarchy and the switching among views. Each app is then expressed as an attributed view graph, which is converted into a vector and fed to classifiers for recognizing its quality classes. Our evaluation with an app dataset from Google Play reports that AppQ achieves the best performance with accuracy of 85.0\%. This shows a lot of promise to warm-start app grading and recommendation systems with AppQ.
Referee: Towards reference-free cross-speaker style transfer with low-quality data for expressive speech synthesis
Sep 08, 2021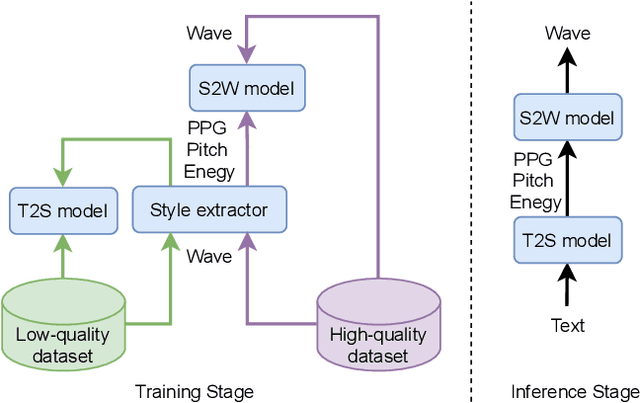
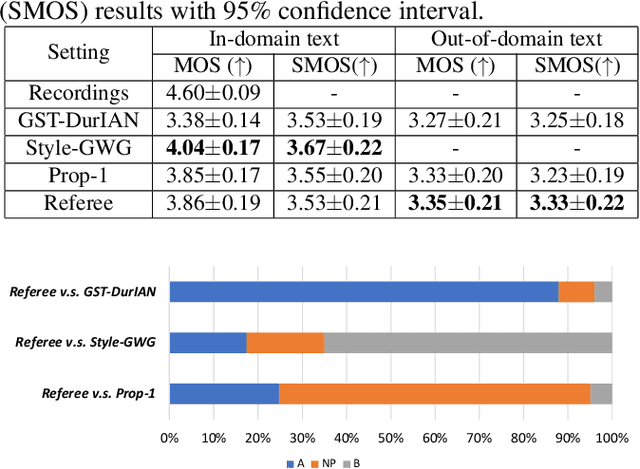
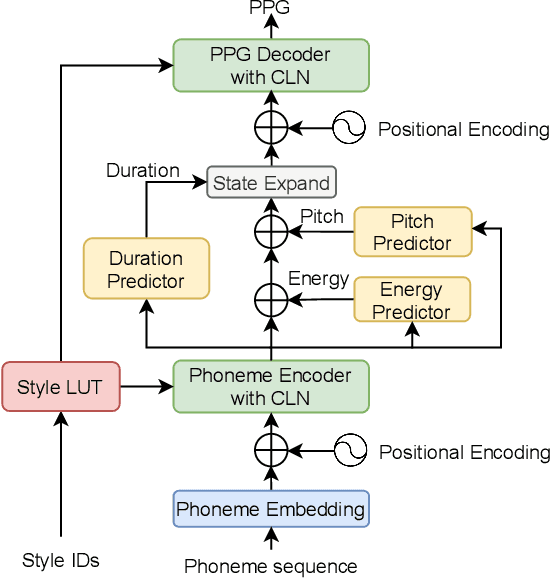
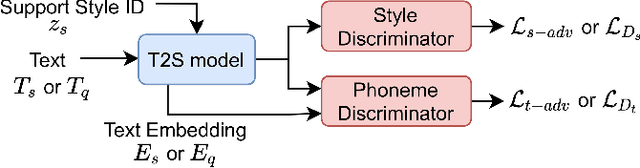
Cross-speaker style transfer (CSST) in text-to-speech (TTS) synthesis aims at transferring a speaking style to the synthesised speech in a target speaker's voice. Most previous CSST approaches rely on expensive high-quality data carrying desired speaking style during training and require a reference utterance to obtain speaking style descriptors as conditioning on the generation of a new sentence. This work presents Referee, a robust reference-free CSST approach for expressive TTS, which fully leverages low-quality data to learn speaking styles from text. Referee is built by cascading a text-to-style (T2S) model with a style-to-wave (S2W) model. Phonetic PosteriorGram (PPG), phoneme-level pitch and energy contours are adopted as fine-grained speaking style descriptors, which are predicted from text using the T2S model. A novel pretrain-refinement method is adopted to learn a robust T2S model by only using readily accessible low-quality data. The S2W model is trained with high-quality target data, which is adopted to effectively aggregate style descriptors and generate high-fidelity speech in the target speaker's voice. Experimental results are presented, showing that Referee outperforms a global-style-token (GST)-based baseline approach in CSST.
Bilateral Denoising Diffusion Models
Aug 31, 2021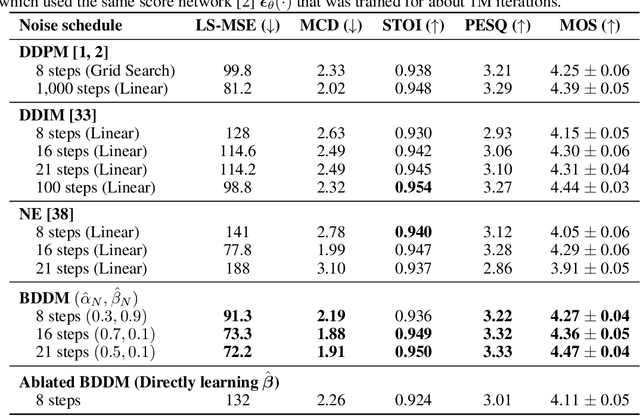
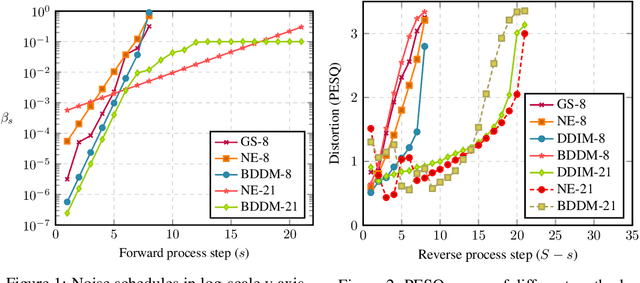
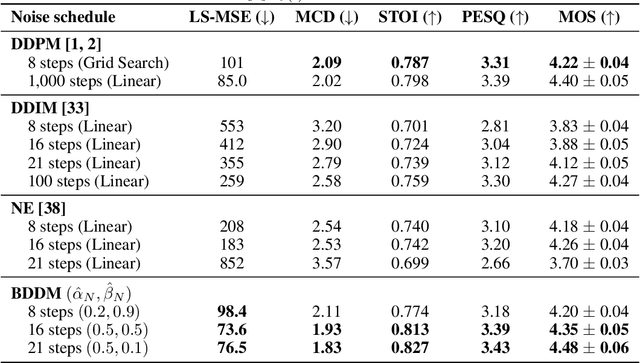
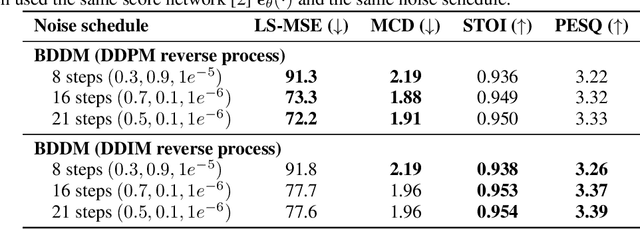
Denoising diffusion probabilistic models (DDPMs) have emerged as competitive generative models yet brought challenges to efficient sampling. In this paper, we propose novel bilateral denoising diffusion models (BDDMs), which take significantly fewer steps to generate high-quality samples. From a bilateral modeling objective, BDDMs parameterize the forward and reverse processes with a score network and a scheduling network, respectively. We show that a new lower bound tighter than the standard evidence lower bound can be derived as a surrogate objective for training the two networks. In particular, BDDMs are efficient, simple-to-train, and capable of further improving any pre-trained DDPM by optimizing the inference noise schedules. Our experiments demonstrated that BDDMs can generate high-fidelity samples with as few as 3 sampling steps and produce comparable or even higher quality samples than DDPMs using 1000 steps with only 16 sampling steps (a 62x speedup).