 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Paper and Code
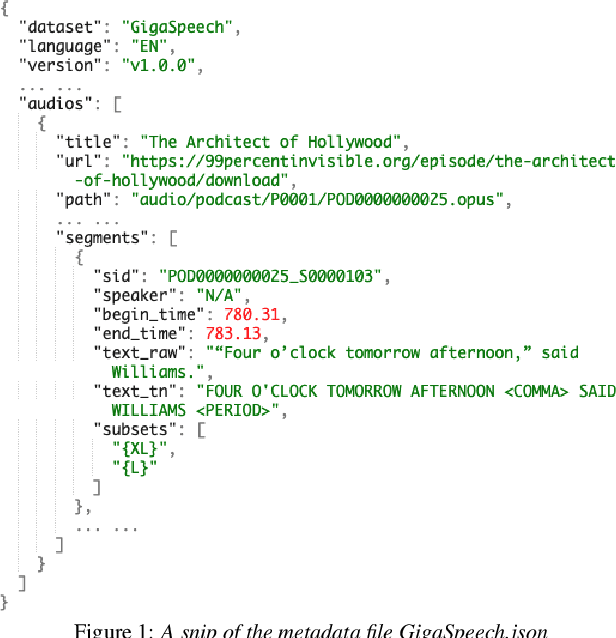
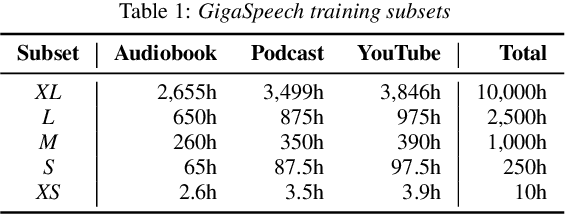
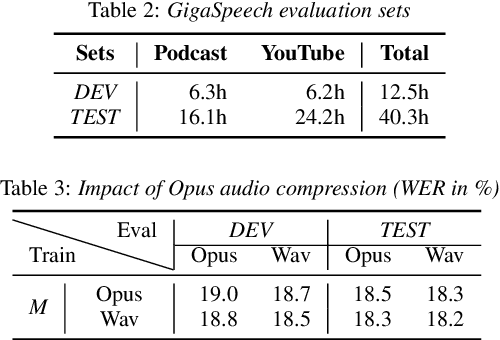
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.