 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferee: Towards reference-free cross-speaker style transfer with low-quality data for expressive speech synthesis
Paper and Code
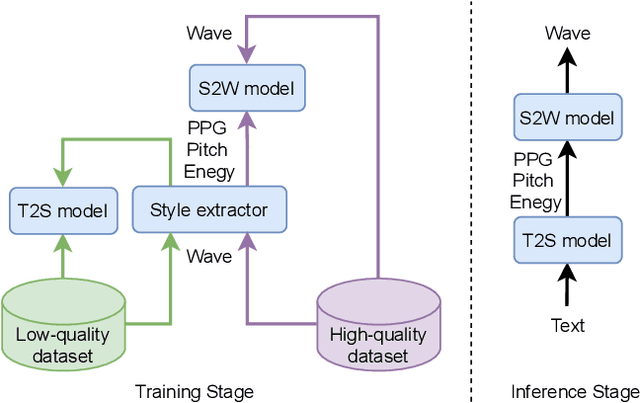
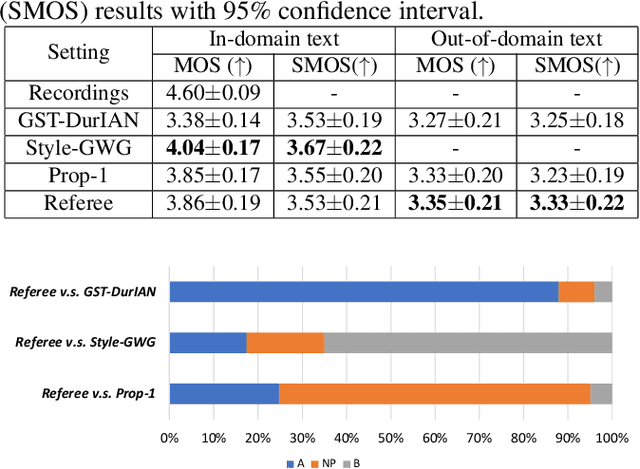
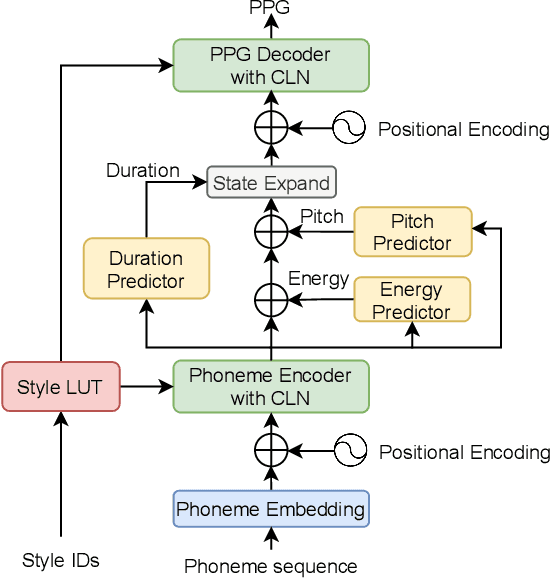
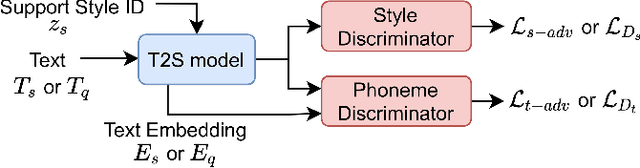
Cross-speaker style transfer (CSST) in text-to-speech (TTS) synthesis aims at transferring a speaking style to the synthesised speech in a target speaker's voice. Most previous CSST approaches rely on expensive high-quality data carrying desired speaking style during training and require a reference utterance to obtain speaking style descriptors as conditioning on the generation of a new sentence. This work presents Referee, a robust reference-free CSST approach for expressive TTS, which fully leverages low-quality data to learn speaking styles from text. Referee is built by cascading a text-to-style (T2S) model with a style-to-wave (S2W) model. Phonetic PosteriorGram (PPG), phoneme-level pitch and energy contours are adopted as fine-grained speaking style descriptors, which are predicted from text using the T2S model. A novel pretrain-refinement method is adopted to learn a robust T2S model by only using readily accessible low-quality data. The S2W model is trained with high-quality target data, which is adopted to effectively aggregate style descriptors and generate high-fidelity speech in the target speaker's voice. Experimental results are presented, showing that Referee outperforms a global-style-token (GST)-based baseline approach in CSST.