 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIXA/Cogcomp at SemEval-2023 Task 2: Context-enriched Multilingual Named Entity Recognition using Knowledge Bases
Apr 27, 2023Named Entity Recognition (NER) is a core natural language processing task in which pre-trained language models have shown remarkable performance. However, standard benchmarks like CoNLL 2003 do not address many of the challenges that deployed NER systems face, such as having to classify emerging or complex entities in a fine-grained way. In this paper we present a novel NER cascade approach comprising three steps: first, identifying candidate entities in the input sentence; second, linking the each candidate to an existing knowledge base; third, predicting the fine-grained category for each entity candidate. We empirically demonstrate the significance of external knowledge bases in accurately classifying fine-grained and emerging entities. Our system exhibits robust performance in the MultiCoNER2 shared task, even in the low-resource language setting where we leverage knowledge bases of high-resource languages.
Towards Corpus-Scale Discovery of Selection Biases in News Coverage: Comparing What Sources Say About Entities as a Start
Apr 06, 2023News sources undergo the process of selecting newsworthy information when covering a certain topic. The process inevitably exhibits selection biases, i.e. news sources' typical patterns of choosing what information to include in news coverage, due to their agenda differences. To understand the magnitude and implications of selection biases, one must first discover (1) on what topics do sources typically have diverging definitions of "newsworthy" information, and (2) do the content selection patterns correlate with certain attributes of the news sources, e.g. ideological leaning, etc. The goal of the paper is to investigate and discuss the challenges of building scalable NLP systems for discovering patterns of media selection biases directly from news content in massive-scale news corpora, without relying on labeled data. To facilitate research in this domain, we propose and study a conceptual framework, where we compare how sources typically mention certain controversial entities, and use such as indicators for the sources' content selection preferences. We empirically show the capabilities of the framework through a case study on NELA-2020, a corpus of 1.8M news articles in English from 519 news sources worldwide. We demonstrate an unsupervised representation learning method to capture the selection preferences for how sources typically mention controversial entities. Our experiments show that that distributional divergence of such representations, when studied collectively across entities and news sources, serve as good indicators for an individual source's ideological leaning. We hope our findings will provide insights for future research on media selection biases.
Conversation Style Transfer using Few-Shot Learning
Feb 16, 2023



Conventional text style transfer approaches for natural language focus on sentence-level style transfer without considering contextual information, and the style is described with attributes (e.g., formality). When applying style transfer on conversations such as task-oriented dialogues, existing approaches suffer from these limitations as context can play an important role and the style attributes are often difficult to define in conversations. In this paper, we introduce conversation style transfer as a few-shot learning problem, where the model learns to perform style transfer by observing only the target-style dialogue examples. We propose a novel in-context learning approach to solve the task with style-free dialogues as a pivot. Human evaluation shows that by incorporating multi-turn context, the model is able to match the target style while having better appropriateness and semantic correctness compared to utterance-level style transfer. Additionally, we show that conversation style transfer can also benefit downstream tasks. Results on multi-domain intent classification tasks show improvement in F1 scores after transferring the style of training data to match the style of test data.
GLUECons: A Generic Benchmark for Learning Under Constraints
Feb 16, 2023Recent research has shown that integrating domain knowledge into deep learning architectures is effective -- it helps reduce the amount of required data, improves the accuracy of the models' decisions, and improves the interpretability of models. However, the research community is missing a convened benchmark for systematically evaluating knowledge integration methods. In this work, we create a benchmark that is a collection of nine tasks in the domains of natural language processing and computer vision. In all cases, we model external knowledge as constraints, specify the sources of the constraints for each task, and implement various models that use these constraints. We report the results of these models using a new set of extended evaluation criteria in addition to the task performances for a more in-depth analysis. This effort provides a framework for a more comprehensive and systematic comparison of constraint integration techniques and for identifying related research challenges. It will facilitate further research for alleviating some problems of state-of-the-art neural models.
STREET: A Multi-Task Structured Reasoning and Explanation Benchmark
Feb 13, 2023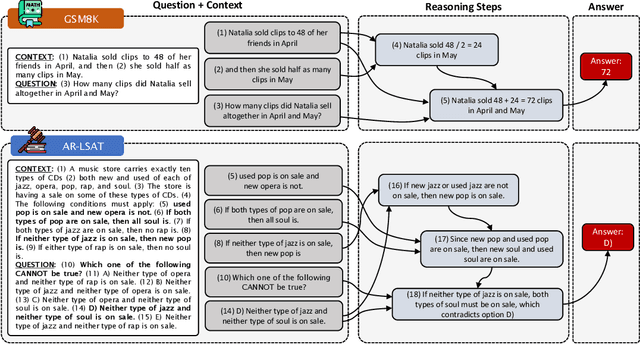
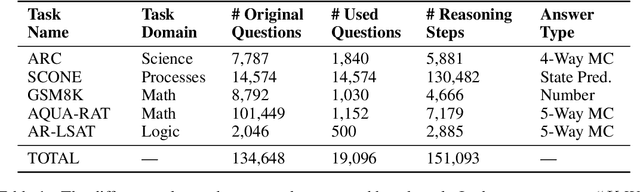
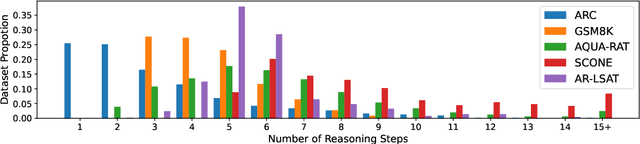
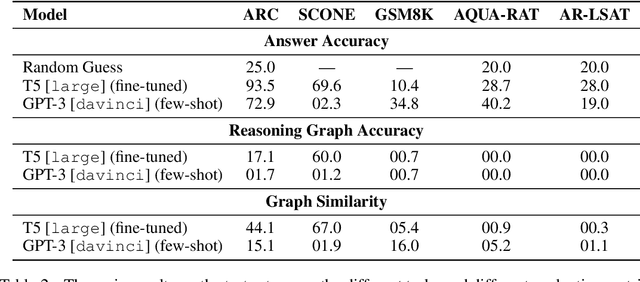
We introduce STREET, a unified multi-task and multi-domain natural language reasoning and explanation benchmark. Unlike most existing question-answering (QA) datasets, we expect models to not only answer questions, but also produce step-by-step structured explanations describing how premises in the question are used to produce intermediate conclusions that can prove the correctness of a certain answer. We perform extensive evaluation with popular language models such as few-shot prompting GPT-3 and fine-tuned T5. We find that these models still lag behind human performance when producing such structured reasoning steps. We believe this work will provide a way for the community to better train and test systems on multi-step reasoning and explanations in natural language.
Rethinking with Retrieval: Faithful Large Language Model Inference
Dec 31, 2022



Despite the success of large language models (LLMs) in various natural language processing (NLP) tasks, the stored knowledge in these models may inevitably be incomplete, out-of-date, or incorrect. This motivates the need to utilize external knowledge to assist LLMs. Unfortunately, current methods for incorporating external knowledge often require additional training or fine-tuning, which can be costly and may not be feasible for LLMs. To address this issue, we propose a novel post-processing approach, rethinking with retrieval (RR), which retrieves relevant external knowledge based on the decomposed reasoning steps obtained from the chain-of-thought (CoT) prompting. This lightweight approach does not require additional training or fine-tuning and is not limited by the input length of LLMs. We evaluate the effectiveness of RR through extensive experiments with GPT-3 on three complex reasoning tasks: commonsense reasoning, temporal reasoning, and tabular reasoning. Our results show that RR can produce more faithful explanations and improve the performance of LLMs.
PropSegmEnt: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition
Dec 21, 2022The widely studied task of Natural Language Inference (NLI) requires a system to recognize whether one piece of text is textually entailed by another, i.e. whether the entirety of its meaning can be inferred from the other. In current NLI datasets and models, textual entailment relations are typically defined on the sentence- or paragraph-level. However, even a simple sentence often contains multiple propositions, i.e. distinct units of meaning conveyed by the sentence. As these propositions can carry different truth values in the context of a given premise, we argue for the need to recognize the textual entailment relation of each proposition in a sentence individually. We propose PropSegmEnt, a corpus of over 35K propositions annotated by expert human raters. Our dataset structure resembles the tasks of (1) segmenting sentences within a document to the set of propositions, and (2) classifying the entailment relation of each proposition with respect to a different yet topically-aligned document, i.e. documents describing the same event or entity. We establish strong baselines for the segmentation and entailment tasks. Through case studies on summary hallucination detection and document-level NLI, we demonstrate that our conceptual framework is potentially useful for understanding and explaining the compositionality of NLI labels.
In and Out-of-Domain Text Adversarial Robustness via Label Smoothing
Dec 20, 2022



Recently it has been shown that state-of-the-art NLP models are vulnerable to adversarial attacks, where the predictions of a model can be drastically altered by slight modifications to the input (such as synonym substitutions). While several defense techniques have been proposed, and adapted, to the discrete nature of text adversarial attacks, the benefits of general-purpose regularization methods such as label smoothing for language models, have not been studied. In this paper, we study the adversarial robustness provided by various label smoothing strategies in foundational models for diverse NLP tasks in both in-domain and out-of-domain settings. Our experiments show that label smoothing significantly improves adversarial robustness in pre-trained models like BERT, against various popular attacks. We also analyze the relationship between prediction confidence and robustness, showing that label smoothing reduces over-confident errors on adversarial examples.
CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context
Dec 20, 2022



While pre-trained language models (LM) for code have achieved great success in code completion, they generate code conditioned only on the contents within the file, i.e., in-file context, but ignore the rich semantics in other files within the same project, i.e., cross-file context, a critical source of information that is especially useful in modern modular software development. Such overlooking constrains code language models' capacity in code completion, leading to unexpected behaviors such as generating hallucinated class member functions or function calls with unexpected arguments. In this work, we develop a cross-file context finder tool, CCFINDER, that effectively locates and retrieves the most relevant cross-file context. We propose CoCoMIC, a framework that incorporates cross-file context to learn the in-file and cross-file context jointly on top of pretrained code LMs. CoCoMIC successfully improves the existing code LM with a 19.30% relative increase in exact match and a 15.41% relative increase in identifier matching for code completion when the cross-file context is provided.
ReCode: Robustness Evaluation of Code Generation Models
Dec 20, 2022



Code generation models have achieved impressive performance. However, they tend to be brittle as slight edits to a prompt could lead to very different generations; these robustness properties, critical for user experience when deployed in real-life applications, are not well understood. Most existing works on robustness in text or code tasks have focused on classification, while robustness in generation tasks is an uncharted area and to date there is no comprehensive benchmark for robustness in code generation. In this paper, we propose ReCode, a comprehensive robustness evaluation benchmark for code generation models. We customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format. They are carefully designed to be natural in real-life coding practice, preserve the original semantic meaning, and thus provide multifaceted assessments of a model's robustness performance. With human annotators, we verified that over 90% of the perturbed prompts do not alter the semantic meaning of the original prompt. In addition, we define robustness metrics for code generation models considering the worst-case behavior under each type of perturbation, taking advantage of the fact that executing the generated code can serve as objective evaluation. We demonstrate ReCode on SOTA models using HumanEval, MBPP, as well as function completion tasks derived from them. Interesting observations include: better robustness for CodeGen over InCoder and GPT-J; models are most sensitive to syntax perturbations; more challenging robustness evaluation on MBPP over HumanEval.