 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRAJEVAL: Decomposing Code Agent Trajectories for Fine-Grained Diagnosis
Mar 25, 2026Code agents can autonomously resolve GitHub issues, yet when they fail, current evaluation provides no visibility into where or why. Metrics such as Pass@1 collapse an entire execution into a single binary outcome, making it difficult to identify where and why the agent went wrong. To address this limitation, we introduce TRAJEVAL, a diagnostic framework that decomposes agent trajectories into three interpretable stages: search (file localization), read (function comprehension), and edit (modification targeting). For each stage, we compute precision and recall by comparing against reference patches. Analyzing 16,758 trajectories across three agent architectures and seven models, we find universal inefficiencies (all agents examine approximately 22x more functions than necessary) yet distinct failure modes: GPT-5 locates relevant code but targets edits incorrectly, while Qwen-32B fails at file discovery entirely. We validate that these diagnostics are predictive, achieving model-level Pass@1 prediction within 0.87-2.1% MAE, and actionable: real-time feedback based on trajectory signals improves two state-of-the-art models by 2.2-4.6 percentage points while reducing costs by 20-31%. These results demonstrate that our framework not only provides a more fine-grained analysis of agent behavior, but also translates diagnostic signals into tangible performance gains. More broadly, TRAJEVAL transforms agent evaluation beyond outcome-based benchmarking toward mechanism-driven diagnosis of agent success and failure.
SWE-Spot: Building Small Repo-Experts with Repository-Centric Learning
Jan 29, 2026The deployment of coding agents in privacy-sensitive and resource-constrained environments drives the demand for capable open-weight Small Language Models (SLMs). However, they suffer from a fundamental capability gap: unlike frontier large models, they lack the inference-time strong generalization to work with complicated, unfamiliar codebases. We identify that the prevailing Task-Centric Learning (TCL) paradigm, which scales exposure across disparate repositories, fails to address this limitation. In response, we propose Repository-Centric Learning (RCL), a paradigm shift that prioritizes vertical repository depth over horizontal task breadth, suggesting SLMs must internalize the "physics" of a target software environment through parametric knowledge acquisition, rather than attempting to recover it via costly inference-time search. Following this new paradigm, we design a four-unit Repository-Centric Experience, transforming static codebases into interactive learning signals, to train SWE-Spot-4B, a family of highly compact models built as repo-specialized experts that breaks established scaling trends, outperforming open-weight models up to larger (e.g., CWM by Meta, Qwen3-Coder-30B) and surpassing/matching efficiency-focused commercial models (e.g., GPT-4.1-mini, GPT-5-nano) across multiple SWE tasks. Further analysis reveals that RCL yields higher training sample efficiency and lower inference costs, emphasizing that for building efficient intelligence, repository mastery is a distinct and necessary dimension that complements general coding capability.
Mechanics of Learned Reasoning 1: TempoBench, A Benchmark for Interpretable Deconstruction of Reasoning System Performance
Oct 31, 2025Large Language Models (LLMs) are increasingly excelling and outpacing human performance on many tasks. However, to improve LLM reasoning, researchers either rely on ad-hoc generated datasets or formal mathematical proof systems such as the Lean proof assistant. Whilst ad-hoc generated methods can capture the decision chains of real-world reasoning processes, they may encode some inadvertent bias in the space of reasoning they cover; they also cannot be formally verified. On the other hand, systems like Lean can guarantee verifiability, but are not well-suited to capture the nature of agentic decision chain-based tasks. This creates a gap both in performance for functions such as business agents or code assistants, and in the usefulness of LLM reasoning benchmarks, whereby these fall short in reasoning structure or real-world alignment. We introduce TempoBench, the first formally grounded and verifiable diagnostic benchmark that parametrizes difficulty to systematically analyze how LLMs perform reasoning. TempoBench uses two evaluation benchmarks to break down reasoning ability. First, temporal trace evaluation (TTE) tests the ability of an LLM to understand and simulate the execution of a given multi-step reasoning system. Subsequently, temporal causal evaluation (TCE) tests an LLM's ability to perform multi-step causal reasoning and to distill cause-and-effect relations from complex systems. We find that models score 65.6% on TCE-normal, and 7.5% on TCE-hard. This shows that state-of-the-art LLMs clearly understand the TCE task but perform poorly as system complexity increases. Our code is available at our \href{https://github.com/nik-hz/tempobench}{GitHub repository}.
AppForge: From Assistant to Independent Developer - Are GPTs Ready for Software Development?
Oct 09, 2025



Large language models (LLMs) have demonstrated remarkable capability in function-level code generation tasks. Unlike isolated functions, real-world applications demand reasoning over the entire software system: developers must orchestrate how different components interact, maintain consistency across states over time, and ensure the application behaves correctly within the lifecycle and framework constraints. Yet, no existing benchmark adequately evaluates whether LLMs can bridge this gap and construct entire software systems from scratch. To address this gap, we propose APPFORGE, a benchmark consisting of 101 software development problems drawn from real-world Android apps. Given a natural language specification detailing the app functionality, a language model is tasked with implementing the functionality into an Android app from scratch. Developing an Android app from scratch requires understanding and coordinating app states, lifecycle management, and asynchronous operations, calling for LLMs to generate context-aware, robust, and maintainable code. To construct APPFORGE, we design a multi-agent system to automatically summarize the main functionalities from app documents and navigate the app to synthesize test cases validating the functional correctness of app implementation. Following rigorous manual verification by Android development experts, APPFORGE incorporates the test cases within an automated evaluation framework that enables reproducible assessment without human intervention, making it easily adoptable for future research. Our evaluation on 12 flagship LLMs show that all evaluated models achieve low effectiveness, with the best-performing model (GPT-5) developing only 18.8% functionally correct applications, highlighting fundamental limitations in current models' ability to handle complex, multi-component software engineering challenges.
Understanding Software Engineering Agents Through the Lens of Traceability: An Empirical Study
Jun 10, 2025



With the advent of large language models (LLMs), software engineering agents (SWE agents) have emerged as a powerful paradigm for automating a range of software tasks -- from code generation and repair to test case synthesis. These agents operate autonomously by interpreting user input and responding to environmental feedback. While various agent architectures have demonstrated strong empirical performance, the internal decision-making worfklows that drive their behavior remain poorly understood. Deeper insight into these workflows hold promise for improving both agent reliability and efficiency. In this work, we present the first systematic study of SWE agent behavior through the lens of execution traces. Our contributions are as follows: (1) we propose the first taxonomy of decision-making pathways across five representative agents; (2) using this taxonomy, we identify three core components essential to agent success -- bug localization, patch generation, and reproduction test generation -- and study each in depth; (3) we study the impact of test generation on successful patch production; and analyze strategies that can lead to successful test generation; (4) we further conduct the first large-scale code clone analysis comparing agent-generated and developer-written patches and provide a qualitative study revealing structural and stylistic differences in patch content. Together, these findings offer novel insights into agent design and open avenues for building agents that are both more effective and more aligned with human development practices.
CrashFixer: A crash resolution agent for the Linux kernel
Apr 29, 2025



Code large language models (LLMs) have shown impressive capabilities on a multitude of software engineering tasks. In particular, they have demonstrated remarkable utility in the task of code repair. However, common benchmarks used to evaluate the performance of code LLMs are often limited to small-scale settings. In this work, we build upon kGym, which shares a benchmark for system-level Linux kernel bugs and a platform to run experiments on the Linux kernel. This paper introduces CrashFixer, the first LLM-based software repair agent that is applicable to Linux kernel bugs. Inspired by the typical workflow of a kernel developer, we identify the key capabilities an expert developer leverages to resolve a kernel crash. Using this as our guide, we revisit the kGym platform and identify key system improvements needed to practically run LLM-based agents at the scale of the Linux kernel (50K files and 20M lines of code). We implement these changes by extending kGym to create an improved platform - called kGymSuite, which will be open-sourced. Finally, the paper presents an evaluation of various repair strategies for such complex kernel bugs and showcases the value of explicitly generating a hypothesis before attempting to fix bugs in complex systems such as the Linux kernel. We also evaluated CrashFixer's capabilities on still open bugs, and found at least two patch suggestions considered plausible to resolve the reported bug.
Dynamic Benchmarking of Reasoning Capabilities in Code Large Language Models Under Data Contamination
Mar 06, 2025
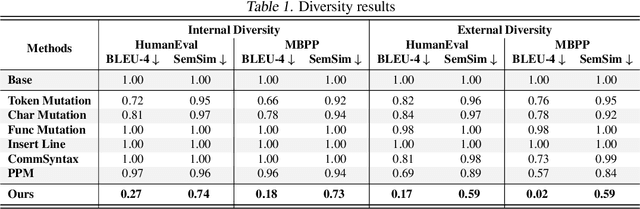
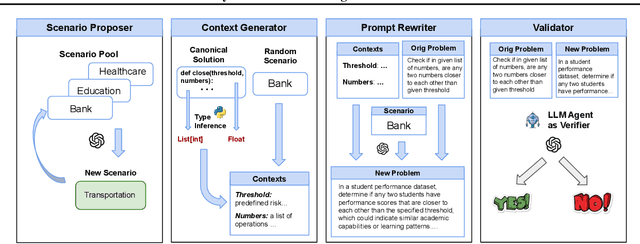
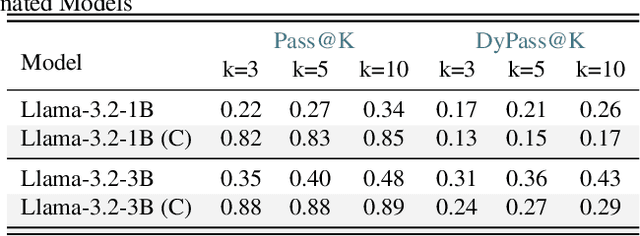
The rapid evolution of code largelanguage models underscores the need for effective and transparent benchmarking of their reasoning capabilities. However, the current benchmarking approach heavily depends on publicly available, human-created datasets. The widespread use of these fixed benchmark datasets makes the benchmarking process to be static and thus particularly susceptible to data contamination, an unavoidable consequence of the extensive data collection processes used to train Code LLMs. Existing approaches that address data contamination often suffer from human effort limitations and imbalanced problem complexity. To tackle these challenges, we propose \tool, a novel benchmarking suite for evaluating Code LLMs under potential data contamination. Given a seed programming problem, \tool employs multiple agents to extract and modify the context without altering the core logic, generating semantically equivalent variations. We introduce a dynamic data generation methods and conduct empirical studies on two seed datasets across 21 Code LLMs. Results show that \tool effectively benchmarks reasoning capabilities under contamination risks while generating diverse problem sets to ensure consistent and reliable evaluations.
Recent Advances in Large Langauge Model Benchmarks against Data Contamination: From Static to Dynamic Evaluation
Feb 23, 2025Data contamination has received increasing attention in the era of large language models (LLMs) due to their reliance on vast Internet-derived training corpora. To mitigate the risk of potential data contamination, LLM benchmarking has undergone a transformation from static to dynamic benchmarking. In this work, we conduct an in-depth analysis of existing static to dynamic benchmarking methods aimed at reducing data contamination risks. We first examine methods that enhance static benchmarks and identify their inherent limitations. We then highlight a critical gap-the lack of standardized criteria for evaluating dynamic benchmarks. Based on this observation, we propose a series of optimal design principles for dynamic benchmarking and analyze the limitations of existing dynamic benchmarks. This survey provides a concise yet comprehensive overview of recent advancements in data contamination research, offering valuable insights and a clear guide for future research efforts. We maintain a GitHub repository to continuously collect both static and dynamic benchmarking methods for LLMs. The repository can be found at this link.
AI Software Engineer: Programming with Trust
Feb 19, 2025
Large Language Models (LLMs) have shown surprising proficiency in generating code snippets, promising to automate large parts of software engineering via artificial intelligence (AI). We argue that successfully deploying AI software engineers requires a level of trust equal to or even greater than the trust established by human-driven software engineering practices. The recent trend toward LLM agents offers a path toward integrating the power of LLMs to create new code with the power of analysis tools to increase trust in the code. This opinion piece comments on whether LLM agents could dominate software engineering workflows in the future and whether the focus of programming will shift from programming at scale to programming with trust.
CWEval: Outcome-driven Evaluation on Functionality and Security of LLM Code Generation
Jan 14, 2025



Large Language Models (LLMs) have significantly aided developers by generating or assisting in code writing, enhancing productivity across various tasks. While identifying incorrect code is often straightforward, detecting vulnerabilities in functionally correct code is more challenging, especially for developers with limited security knowledge, which poses considerable security risks of using LLM-generated code and underscores the need for robust evaluation benchmarks that assess both functional correctness and security. Current benchmarks like CyberSecEval and SecurityEval attempt to solve it but are hindered by unclear and impractical specifications, failing to assess both functionality and security accurately. To tackle these deficiencies, we introduce CWEval, a novel outcome-driven evaluation framework designed to enhance the evaluation of secure code generation by LLMs. This framework not only assesses code functionality but also its security simultaneously with high-quality task specifications and outcome-driven test oracles which provides high accuracy. Coupled with CWEval-bench, a multilingual, security-critical coding benchmark, CWEval provides a rigorous empirical security evaluation on LLM-generated code, overcoming previous benchmarks' shortcomings. Through our evaluations, CWEval reveals a notable portion of functional but insecure code produced by LLMs, and shows a serious inaccuracy of previous evaluations, ultimately contributing significantly to the field of secure code generation. We open-source our artifact at: https://github.com/Co1lin/CWEval .