 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Compositionality in Dual-Encoder Vision-Language Models: The Role of Inference
Apr 13, 2026Dual-encoder Vision-Language Models (VLMs) such as CLIP are often characterized as bag-of-words systems due to their poor performance on compositional benchmarks. We argue that this limitation may stem less from deficient representations than from the standard inference protocol based on global cosine similarity. First, through controlled diagnostic experiments, we show that explicitly enforcing fine-grained region-segment alignment at inference dramatically improves compositional performance without updating pretrained encoders. We then introduce a lightweight transformer that learns such alignments directly from frozen patch and token embeddings. Comparing against full fine-tuning and prior end-to-end compositional training methods, we find that although these approaches improve in-domain retrieval, their gains do not consistently transfer under distribution shift. In contrast, learning localized alignment over frozen representations matches full fine-tuning on in-domain retrieval while yielding substantial improvements on controlled out-of-domain compositional benchmarks. These results identify global embedding matching as a key bottleneck in dual-encoder VLMs and highlight the importance of alignment mechanisms for robust compositional generalization.
Multimodal Large Language Models for Low-Resource Languages: A Case Study for Basque
Nov 12, 2025Current Multimodal Large Language Models exhibit very strong performance for several demanding tasks. While commercial MLLMs deliver acceptable performance in low-resource languages, comparable results remain unattained within the open science community. In this paper, we aim to develop a strong MLLM for a low-resource language, namely Basque. For that purpose, we develop our own training and evaluation image-text datasets. Using two different Large Language Models as backbones, the Llama-3.1-Instruct model and a Basque-adapted variant called Latxa, we explore several data mixtures for training. We show that: i) low ratios of Basque multimodal data (around 20%) are already enough to obtain solid results on Basque benchmarks, and ii) contrary to expected, a Basque instructed backbone LLM is not required to obtain a strong MLLM in Basque. Our results pave the way to develop MLLMs for other low-resource languages by openly releasing our resources.
Adding simple structure at inference improves Vision-Language Compositionality
Jun 11, 2025Dual encoder Vision-Language Models (VLM) such as CLIP are widely used for image-text retrieval tasks. However, those models struggle with compositionality, showing a bag-of-words-like behavior that limits their retrieval performance. Many different training approaches have been proposed to improve the vision-language compositionality capabilities of those models. In comparison, inference-time techniques have received little attention. In this paper, we propose to add simple structure at inference, where, given an image and a caption: i) we divide the image into different smaller crops, ii) we extract text segments, capturing objects, attributes and relations, iii) using a VLM, we find the image crops that better align with text segments obtaining matches, and iv) we compute the final image-text similarity aggregating the individual similarities of the matches. Based on various popular dual encoder VLMs, we evaluate our approach in controlled and natural datasets for VL compositionality. We find that our approach consistently improves the performance of evaluated VLMs without any training, which shows the potential of inference-time techniques. The results are especially good for attribute-object binding as shown in the controlled dataset. As a result of an extensive analysis: i) we show that processing image crops is actually essential for the observed gains in performance, and ii) we identify specific areas to further improve inference-time approaches.
Vision-Language Models Struggle to Align Entities across Modalities
Mar 05, 2025Cross-modal entity linking refers to the ability to align entities and their attributes across different modalities. While cross-modal entity linking is a fundamental skill needed for real-world applications such as multimodal code generation, fake news detection, or scene understanding, it has not been thoroughly studied in the literature. In this paper, we introduce a new task and benchmark to address this gap. Our benchmark, MATE, consists of 5.5k evaluation instances featuring visual scenes aligned with their textual representations. To evaluate cross-modal entity linking performance, we design a question-answering task that involves retrieving one attribute of an object in one modality based on a unique attribute of that object in another modality. We evaluate state-of-the-art Vision-Language Models (VLMs) and humans on this task, and find that VLMs struggle significantly compared to humans, particularly as the number of objects in the scene increases. Our analysis also shows that, while chain-of-thought prompting can improve VLM performance, models remain far from achieving human-level proficiency. These findings highlight the need for further research in cross-modal entity linking and show that MATE is a strong benchmark to support that progress.
BiVLC: Extending Vision-Language Compositionality Evaluation with Text-to-Image Retrieval
Jun 14, 2024Existing Vision-Language Compositionality (VLC) benchmarks like SugarCrepe are formulated as image-to-text retrieval problems, where, given an image, the models need to select between the correct textual description and a synthetic hard negative text. In this work we present the Bidirectional Vision-Language Compositionality (BiVLC) dataset. The novelty of BiVLC is to add a synthetic hard negative image generated from the synthetic text, resulting in two image-to-text retrieval examples (one for each image) and, more importantly, two text-to-image retrieval examples (one for each text). Human annotators filter out ill-formed examples ensuring the validity of the benchmark. The experiments on BiVLC uncover a weakness of current multimodal models, as they perform poorly in the text-to-image direction. In fact, when considering both retrieval directions, the conclusions obtained in previous works change significantly. In addition to the benchmark, we show that a contrastive model trained using synthetic images and texts improves the state of the art in SugarCrepe and in BiVLC for both retrieval directions. The gap to human performance in BiVLC confirms that Vision-Language Compositionality is still a challenging problem. BiVLC and code are available at https://imirandam.github.io/BiVLC_project_page.
Grounding Spatial Relations in Text-Only Language Models
Mar 20, 2024



This paper shows that text-only Language Models (LM) can learn to ground spatial relations like "left of" or "below" if they are provided with explicit location information of objects and they are properly trained to leverage those locations. We perform experiments on a verbalized version of the Visual Spatial Reasoning (VSR) dataset, where images are coupled with textual statements which contain real or fake spatial relations between two objects of the image. We verbalize the images using an off-the-shelf object detector, adding location tokens to every object label to represent their bounding boxes in textual form. Given the small size of VSR, we do not observe any improvement when using locations, but pretraining the LM over a synthetic dataset automatically derived by us improves results significantly when using location tokens. We thus show that locations allow LMs to ground spatial relations, with our text-only LMs outperforming Vision-and-Language Models and setting the new state-of-the-art for the VSR dataset. Our analysis show that our text-only LMs can generalize beyond the relations seen in the synthetic dataset to some extent, learning also more useful information than that encoded in the spatial rules we used to create the synthetic dataset itself.
Improving Explicit Spatial Relationships in Text-to-Image Generation through an Automatically Derived Dataset
Mar 01, 2024



Existing work has observed that current text-to-image systems do not accurately reflect explicit spatial relations between objects such as 'left of' or 'below'. We hypothesize that this is because explicit spatial relations rarely appear in the image captions used to train these models. We propose an automatic method that, given existing images, generates synthetic captions that contain 14 explicit spatial relations. We introduce the Spatial Relation for Generation (SR4G) dataset, which contains 9.9 millions image-caption pairs for training, and more than 60 thousand captions for evaluation. In order to test generalization we also provide an 'unseen' split, where the set of objects in the train and test captions are disjoint. SR4G is the first dataset that can be used to spatially fine-tune text-to-image systems. We show that fine-tuning two different Stable Diffusion models (denoted as SD$_{SR4G}$) yields up to 9 points improvements in the VISOR metric. The improvement holds in the 'unseen' split, showing that SD$_{SR4G}$ is able to generalize to unseen objects. SD$_{SR4G}$ improves the state-of-the-art with fewer parameters, and avoids complex architectures. Our analysis shows that improvement is consistent for all relations. The dataset and the code will be publicly available.
IXA/Cogcomp at SemEval-2023 Task 2: Context-enriched Multilingual Named Entity Recognition using Knowledge Bases
Apr 27, 2023Named Entity Recognition (NER) is a core natural language processing task in which pre-trained language models have shown remarkable performance. However, standard benchmarks like CoNLL 2003 do not address many of the challenges that deployed NER systems face, such as having to classify emerging or complex entities in a fine-grained way. In this paper we present a novel NER cascade approach comprising three steps: first, identifying candidate entities in the input sentence; second, linking the each candidate to an existing knowledge base; third, predicting the fine-grained category for each entity candidate. We empirically demonstrate the significance of external knowledge bases in accurately classifying fine-grained and emerging entities. Our system exhibits robust performance in the MultiCoNER2 shared task, even in the low-resource language setting where we leverage knowledge bases of high-resource languages.
Image Captioning for Effective Use of Language Models in Knowledge-Based Visual Question Answering
Sep 15, 2021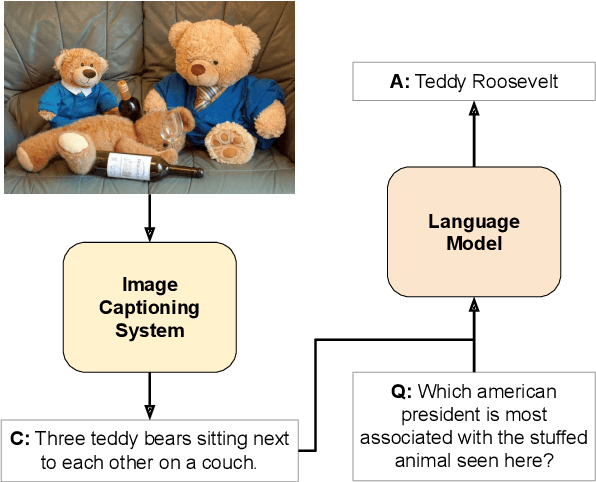



Integrating outside knowledge for reasoning in visio-linguistic tasks such as visual question answering (VQA) is an open problem. Given that pretrained language models have been shown to include world knowledge, we propose to use a unimodal (text-only) train and inference procedure based on automatic off-the-shelf captioning of images and pretrained language models. Our results on a visual question answering task which requires external knowledge (OK-VQA) show that our text-only model outperforms pretrained multimodal (image-text) models of comparable number of parameters. In contrast, our model is less effective in a standard VQA task (VQA 2.0) confirming that our text-only method is specially effective for tasks requiring external knowledge. In addition, we show that our unimodal model is complementary to multimodal models in both OK-VQA and VQA 2.0, and yield the best result to date in OK-VQA among systems not using external knowledge graphs, and comparable to systems that do use them. Our qualitative analysis on OK-VQA reveals that automatic captions often fail to capture relevant information in the images, which seems to be balanced by the better inference ability of the text-only language models. Our work opens up possibilities to further improve inference in visio-linguistic tasks.
Evaluating Multimodal Representations on Visual Semantic Textual Similarity
Apr 04, 2020

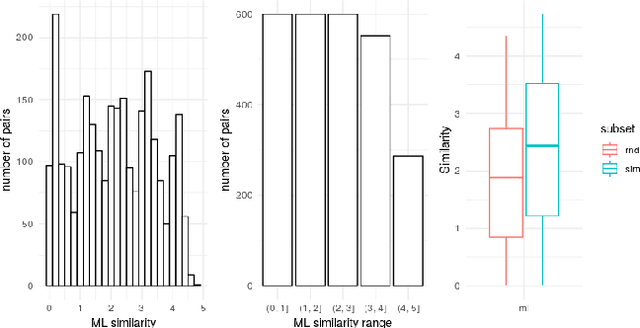
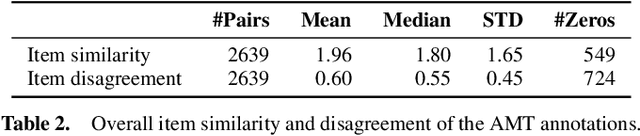
The combination of visual and textual representations has produced excellent results in tasks such as image captioning and visual question answering, but the inference capabilities of multimodal representations are largely untested. In the case of textual representations, inference tasks such as Textual Entailment and Semantic Textual Similarity have been often used to benchmark the quality of textual representations. The long term goal of our research is to devise multimodal representation techniques that improve current inference capabilities. We thus present a novel task, Visual Semantic Textual Similarity (vSTS), where such inference ability can be tested directly. Given two items comprised each by an image and its accompanying caption, vSTS systems need to assess the degree to which the captions in context are semantically equivalent to each other. Our experiments using simple multimodal representations show that the addition of image representations produces better inference, compared to text-only representations. The improvement is observed both when directly computing the similarity between the representations of the two items, and when learning a siamese network based on vSTS training data. Our work shows, for the first time, the successful contribution of visual information to textual inference, with ample room for benchmarking more complex multimodal representation options.