 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODESTRUCT: Code Agents over Structured Action Spaces
Apr 07, 2026LLM-based code agents treat repositories as unstructured text, applying edits through brittle string matching that frequently fails due to formatting drift or ambiguous patterns. We propose reframing the codebase as a structured action space where agents operate on named AST entities rather than text spans. Our framework, CODESTRUCT, provides readCode for retrieving complete syntactic units and editCode for applying syntax-validated transformations to semantic program elements. Evaluated on SWE-Bench Verified across six LLMs, CODESTRUCT improves Pass@1 accuracy by 1.2-5.0% while reducing token consumption by 12-38% for most models. Models that frequently fail to produce valid patches under text-based interfaces benefit most: GPT-5-nano improves by 20.8% as empty-patch failures drop from 46.6% to 7.2%. On CodeAssistBench, we observe consistent accuracy gains (+0.8-4.4%) with cost reductions up to 33%. Our results show that structure-aware interfaces offer a more reliable foundation for code agents.
On Mitigating Code LLM Hallucinations with API Documentation
Jul 13, 2024



In this study, we address the issue of API hallucinations in various software engineering contexts. We introduce CloudAPIBench, a new benchmark designed to measure API hallucination occurrences. CloudAPIBench also provides annotations for frequencies of API occurrences in the public domain, allowing us to study API hallucinations at various frequency levels. Our findings reveal that Code LLMs struggle with low frequency APIs: for e.g., GPT-4o achieves only 38.58% valid low frequency API invocations. We demonstrate that Documentation Augmented Generation (DAG) significantly improves performance for low frequency APIs (increase to 47.94% with DAG) but negatively impacts high frequency APIs when using sub-optimal retrievers (a 39.02% absolute drop). To mitigate this, we propose to intelligently trigger DAG where we check against an API index or leverage Code LLMs' confidence scores to retrieve only when needed. We demonstrate that our proposed methods enhance the balance between low and high frequency API performance, resulting in more reliable API invocations (8.20% absolute improvement on CloudAPIBench for GPT-4o).
Repoformer: Selective Retrieval for Repository-Level Code Completion
Mar 15, 2024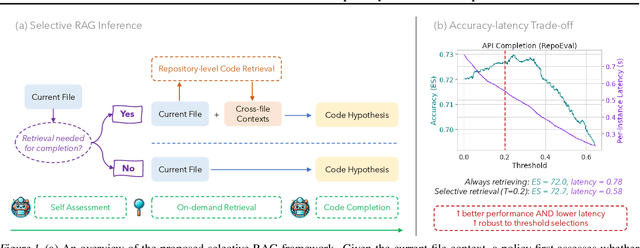
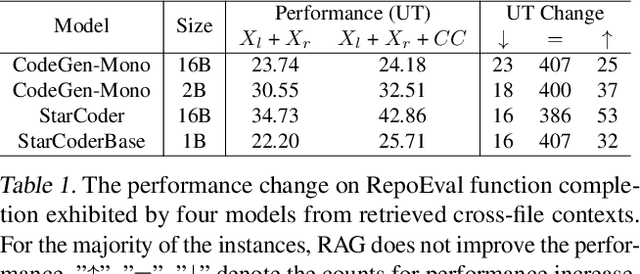
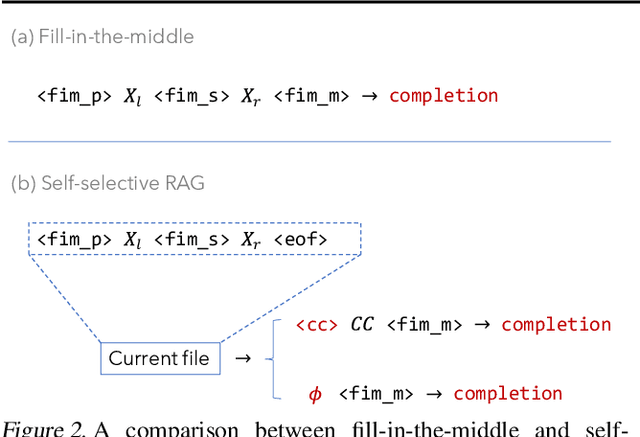
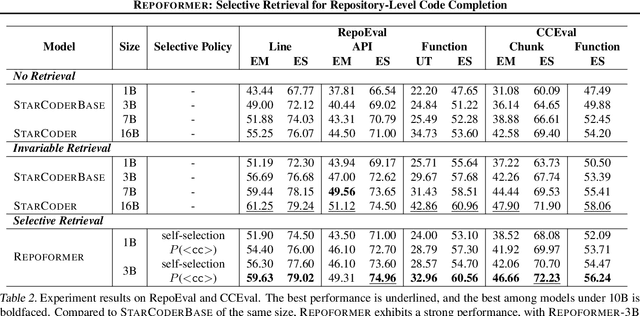
Recent advances in retrieval-augmented generation (RAG) have initiated a new era in repository-level code completion. However, the invariable use of retrieval in existing methods exposes issues in both efficiency and robustness, with a large proportion of the retrieved contexts proving unhelpful or harmful to code language models (code LMs). To tackle the challenges, this paper proposes a selective RAG framework where retrieval is avoided when unnecessary. To power this framework, we design a self-supervised learning approach that enables a code LM to accurately self-evaluate whether retrieval can improve its output quality and robustly leverage the potentially noisy retrieved contexts. Using this LM as both the selective retrieval policy and the generation model, our framework consistently outperforms the state-of-the-art prompting with an invariable retrieval approach on diverse benchmarks including RepoEval, CrossCodeEval, and a new benchmark. Meanwhile, our selective retrieval strategy results in strong efficiency improvements by as much as 70% inference speedup without harming the performance. We demonstrate that our framework effectively accommodates different generation models, retrievers, and programming languages. These advancements position our framework as an important step towards more accurate and efficient repository-level code completion.
Code-Aware Prompting: A study of Coverage Guided Test Generation in Regression Setting using LLM
Jan 31, 2024



Testing plays a pivotal role in ensuring software quality, yet conventional Search Based Software Testing (SBST) methods often struggle with complex software units, achieving suboptimal test coverage. Recent work using large language models (LLMs) for test generation have focused on improving generation quality through optimizing the test generation context and correcting errors in model outputs, but use fixed prompting strategies that prompt the model to generate tests without additional guidance. As a result LLM-generated test suites still suffer from low coverage. In this paper, we present SymPrompt, a code-aware prompting strategy for LLMs in test generation. SymPrompt's approach is based on recent work that demonstrates LLMs can solve more complex logical problems when prompted to reason about the problem in a multi-step fashion. We apply this methodology to test generation by deconstructing the testsuite generation process into a multi-stage sequence, each of which is driven by a specific prompt aligned with the execution paths of the method under test, and exposing relevant type and dependency focal context to the model. Our approach enables pretrained LLMs to generate more complete test cases without any additional training. We implement SymPrompt using the TreeSitter parsing framework and evaluate on a benchmark challenging methods from open source Python projects. SymPrompt enhances correct test generations by a factor of 5 and bolsters relative coverage by 26% for CodeGen2. Notably, when applied to GPT-4, symbolic path prompts improve coverage by over 2x compared to baseline prompting strategies.
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion
Oct 17, 2023



Code completion models have made significant progress in recent years, yet current popular evaluation datasets, such as HumanEval and MBPP, predominantly focus on code completion tasks within a single file. This over-simplified setting falls short of representing the real-world software development scenario where repositories span multiple files with numerous cross-file dependencies, and accessing and understanding cross-file context is often required to complete the code correctly. To fill in this gap, we propose CrossCodeEval, a diverse and multilingual code completion benchmark that necessitates an in-depth cross-file contextual understanding to complete the code accurately. CrossCodeEval is built on a diverse set of real-world, open-sourced, permissively-licensed repositories in four popular programming languages: Python, Java, TypeScript, and C#. To create examples that strictly require cross-file context for accurate completion, we propose a straightforward yet efficient static-analysis-based approach to pinpoint the use of cross-file context within the current file. Extensive experiments on state-of-the-art code language models like CodeGen and StarCoder demonstrate that CrossCodeEval is extremely challenging when the relevant cross-file context is absent, and we see clear improvements when adding these context into the prompt. However, despite such improvements, the pinnacle of performance remains notably unattained even with the highest-performing model, indicating that CrossCodeEval is also capable of assessing model's capability in leveraging extensive context to make better code completion. Finally, we benchmarked various methods in retrieving cross-file context, and show that CrossCodeEval can also be used to measure the capability of code retrievers.
Exploring Continual Learning for Code Generation Models
Jul 05, 2023



Large-scale code generation models such as Codex and CodeT5 have achieved impressive performance. However, libraries are upgraded or deprecated very frequently and re-training large-scale language models is computationally expensive. Therefore, Continual Learning (CL) is an important aspect that remains underexplored in the code domain. In this paper, we introduce a benchmark called CodeTask-CL that covers a wide range of tasks, including code generation, translation, summarization, and refinement, with different input and output programming languages. Next, on our CodeTask-CL benchmark, we compare popular CL techniques from NLP and Vision domains. We find that effective methods like Prompt Pooling (PP) suffer from catastrophic forgetting due to the unstable training of the prompt selection mechanism caused by stark distribution shifts in coding tasks. We address this issue with our proposed method, Prompt Pooling with Teacher Forcing (PP-TF), that stabilizes training by enforcing constraints on the prompt selection mechanism and leads to a 21.54% improvement over Prompt Pooling. Along with the benchmark, we establish a training pipeline that can be used for CL on code models, which we believe can motivate further development of CL methods for code models. Our code is available at https://github.com/amazon-science/codetaskcl-pptf
A Static Evaluation of Code Completion by Large Language Models
Jun 05, 2023



Large language models trained on code have shown great potential to increase productivity of software developers. Several execution-based benchmarks have been proposed to evaluate functional correctness of model-generated code on simple programming problems. Nevertheless, it is expensive to perform the same evaluation on complex real-world projects considering the execution cost. On the contrary, static analysis tools such as linters, which can detect errors without running the program, haven't been well explored for evaluating code generation models. In this work, we propose a static evaluation framework to quantify static errors in Python code completions, by leveraging Abstract Syntax Trees. Compared with execution-based evaluation, our method is not only more efficient, but also applicable to code in the wild. For experiments, we collect code context from open source repos to generate one million function bodies using public models. Our static analysis reveals that Undefined Name and Unused Variable are the most common errors among others made by language models. Through extensive studies, we also show the impact of sampling temperature, model size, and context on static errors in code completions.
Greener yet Powerful: Taming Large Code Generation Models with Quantization
Mar 09, 2023



ML-powered code generation aims to assist developers to write code in a more productive manner, by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have substantially pushed the boundary of code generation and achieved impressive performance. Despite their great power, the huge number of model parameters poses a significant threat to adapting them in a regular software development environment, where a developer might use a standard laptop or mid-size server to develop her code. Such large models incur significant resource usage (in terms of memory, latency, and dollars) as well as carbon footprint. Model compression is a promising approach to address these challenges. Several techniques are proposed to compress large pretrained models typically used for vision or textual data. Out of many available compression techniques, we identified that quantization is mostly applicable for code generation task as it does not require significant retraining cost. As quantization represents model parameters with lower-bit integer (e.g., int8), the model size and runtime latency would both benefit from such int representation. We extensively study the impact of quantized model on code generation tasks across different dimension: (i) resource usage and carbon footprint, (ii) accuracy, and (iii) robustness. To this end, through systematic experiments we find a recipe of quantization technique that could run even a $6$B model in a regular laptop without significant accuracy or robustness degradation. We further found the recipe is readily applicable to code summarization task as well.
ReCode: Robustness Evaluation of Code Generation Models
Dec 20, 2022



Code generation models have achieved impressive performance. However, they tend to be brittle as slight edits to a prompt could lead to very different generations; these robustness properties, critical for user experience when deployed in real-life applications, are not well understood. Most existing works on robustness in text or code tasks have focused on classification, while robustness in generation tasks is an uncharted area and to date there is no comprehensive benchmark for robustness in code generation. In this paper, we propose ReCode, a comprehensive robustness evaluation benchmark for code generation models. We customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format. They are carefully designed to be natural in real-life coding practice, preserve the original semantic meaning, and thus provide multifaceted assessments of a model's robustness performance. With human annotators, we verified that over 90% of the perturbed prompts do not alter the semantic meaning of the original prompt. In addition, we define robustness metrics for code generation models considering the worst-case behavior under each type of perturbation, taking advantage of the fact that executing the generated code can serve as objective evaluation. We demonstrate ReCode on SOTA models using HumanEval, MBPP, as well as function completion tasks derived from them. Interesting observations include: better robustness for CodeGen over InCoder and GPT-J; models are most sensitive to syntax perturbations; more challenging robustness evaluation on MBPP over HumanEval.
CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context
Dec 20, 2022



While pre-trained language models (LM) for code have achieved great success in code completion, they generate code conditioned only on the contents within the file, i.e., in-file context, but ignore the rich semantics in other files within the same project, i.e., cross-file context, a critical source of information that is especially useful in modern modular software development. Such overlooking constrains code language models' capacity in code completion, leading to unexpected behaviors such as generating hallucinated class member functions or function calls with unexpected arguments. In this work, we develop a cross-file context finder tool, CCFINDER, that effectively locates and retrieves the most relevant cross-file context. We propose CoCoMIC, a framework that incorporates cross-file context to learn the in-file and cross-file context jointly on top of pretrained code LMs. CoCoMIC successfully improves the existing code LM with a 19.30% relative increase in exact match and a 15.41% relative increase in identifier matching for code completion when the cross-file context is provided.