 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNNF: An SNN-based Near-Sensor Noise Filter for Dynamic Vision Sensors
May 03, 2026Dynamic Vision Sensors (DVS) exhibit exceptional dynamic range and low power consumption, making them ideal for edge applications in the Internet of Video Things (IoVT). However, their output is often degraded by spurious Background Activity (BA) noise, leading to unnecessary computational overhead. This paper proposes SNNF, a near-sensor BA noise filter that integrates a compact Event-Based Binary Image (EBBI) representation, a parallel memory architecture, and a single-layer Spiking Neural Network (SNN) classifier. Trained on representative DVS data, the SNN distinguishes signal events from noise with an AUC of 0.89 on standard datasets. The binary-array-based EBBI eliminates timestamp dependency, significantly reducing memory footprint. Moreover, the SNN's spike-based computation replaces power-hungry multipliers with simple accumulation logic and minimizes inter-neuron data width, resulting in an extremely hardware-efficient design. FPGA implementation results show that SNNF reduces memory and logic resources to approximately 11% and 40%, respectively of state-of-the-art filters, while achieving a throughput of 29 Mega events per second (Meps). In a 65 nm CMOS ASIC implementation, SNNF achieves 44.4 Meps with an area and power consumption of only ~13% and <5% of the corresponding ANN-based designs. These results demonstrate that SNNF provides an excellent balance between filtering accuracy and hardware efficiency, making it highly suitable for resource-constrained, near-sensor deployment.
SRAM-Based Compute-in-Memory Accelerator for Linear-decay Spiking Neural Networks
Mar 13, 2026Spiking Neural Networks (SNNs) have emerged as a biologically inspired alternative to conventional deep networks, offering event-driven and energy-efficient computation. However, their throughput remains constrained by the serial update of neuron membrane states. While many hardware accelerators and Compute-in-Memory (CIM) architectures efficiently parallelize the synaptic operation (W x I) achieving O(1) complexity for matrix-vector multiplication, the subsequent state update step still requires O(N) time to refresh all neuron membrane potentials. This mismatch makes state update the dominant latency and energy bottleneck in SNN inference. To address this challenge, we propose an SRAM-based CIM for SNN with Linear Decay Leaky Integrate-and-Fire (LD-LIF) Neuron that co-optimizes algorithm and hardware. At the algorithmic level, we replace the conventional exponential membrane decay with a linear decay approximation, converting costly multiplications into simple additions while accuracy drops only around 1%. At the architectural level, we introduce an in-memory parallel update scheme that performs in-place decay directly within the SRAM array, eliminating the need for global sequential updates. Evaluated on benchmark SNN workloads, the proposed method achieves a 1.1 x to 16.7 x reduction of SOP energy consumption, while providing 15.9 x to 69 x more energy efficiency, with negligible accuracy loss relative to original decay models. This work highlights that beyond accelerating the (W x I) computation, optimizing state-update dynamics within CIM architectures is essential for scalable, low-power, and real-time neuromorphic processing.
MR. Guard: Multilingual Reasoning Guardrail using Curriculum Learning
Apr 21, 2025Large Language Models (LLMs) are susceptible to adversarial attacks such as jailbreaking, which can elicit harmful or unsafe behaviors. This vulnerability is exacerbated in multilingual setting, where multilingual safety-aligned data are often limited. Thus, developing a guardrail capable of detecting and filtering unsafe content across diverse languages is critical for deploying LLMs in real-world applications. In this work, we propose an approach to build a multilingual guardrail with reasoning. Our method consists of: (1) synthetic multilingual data generation incorporating culturally and linguistically nuanced variants, (2) supervised fine-tuning, and (3) a curriculum-guided Group Relative Policy Optimization (GRPO) framework that further improves performance. Experimental results demonstrate that our multilingual guardrail consistently outperforms recent baselines across both in-domain and out-of-domain languages. The multilingual reasoning capability of our guardrail enables it to generate multilingual explanations, which are particularly useful for understanding language-specific risks and ambiguities in multilingual content moderation.
Safety Monitoring for Learning-Enabled Cyber-Physical Systems in Out-of-Distribution Scenarios
Apr 18, 2025The safety of learning-enabled cyber-physical systems is compromised by the well-known vulnerabilities of deep neural networks to out-of-distribution (OOD) inputs. Existing literature has sought to monitor the safety of such systems by detecting OOD data. However, such approaches have limited utility, as the presence of an OOD input does not necessarily imply the violation of a desired safety property. We instead propose to directly monitor safety in a manner that is itself robust to OOD data. To this end, we predict violations of signal temporal logic safety specifications based on predicted future trajectories. Our safety monitor additionally uses a novel combination of adaptive conformal prediction and incremental learning. The former obtains probabilistic prediction guarantees even on OOD data, and the latter prevents overly conservative predictions. We evaluate the efficacy of the proposed approach in two case studies on safety monitoring: 1) predicting collisions of an F1Tenth car with static obstacles, and 2) predicting collisions of a race car with multiple dynamic obstacles. We find that adaptive conformal prediction obtains theoretical guarantees where other uncertainty quantification methods fail to do so. Additionally, combining adaptive conformal prediction and incremental learning for safety monitoring achieves high recall and timeliness while reducing loss in precision. We achieve these results even in OOD settings and outperform alternative methods.
Benchmarking LLM Guardrails in Handling Multilingual Toxicity
Oct 29, 2024



With the ubiquity of Large Language Models (LLMs), guardrails have become crucial to detect and defend against toxic content. However, with the increasing pervasiveness of LLMs in multilingual scenarios, their effectiveness in handling multilingual toxic inputs remains unclear. In this work, we introduce a comprehensive multilingual test suite, spanning seven datasets and over ten languages, to benchmark the performance of state-of-the-art guardrails. We also investigates the resilience of guardrails against recent jailbreaking techniques, and assess the impact of in-context safety policies and language resource availability on guardrails' performance. Our findings show that existing guardrails are still ineffective at handling multilingual toxicity and lack robustness against jailbreaking prompts. This work aims to identify the limitations of guardrails and to build a more reliable and trustworthy LLMs in multilingual scenarios.
Understanding Calibration for Multilingual Question Answering Models
Nov 15, 2023



Multilingual pre-trained language models are incredibly effective at Question Answering (QA), a core task in Natural Language Understanding, achieving high accuracies on several multilingual benchmarks. However, little is known about how well they are calibrated. In this paper, we study the calibration properties of several pre-trained multilingual large language models (LLMs) on a variety of question-answering tasks. We perform extensive experiments, spanning both extractive and generative QA model designs and diverse languages, spanning both high-resource and low-resource ones. We study different dimensions of calibration in in-distribution, out-of-distribution, and cross-lingual transfer settings, and investigate strategies to improve it, including post-hoc methods and regularized fine-tuning. We demonstrate automatically translated data augmentation as a highly effective technique to improve model calibration. We also conduct a number of ablation experiments to study the effect of model size on calibration and how multilingual models compare with their monolingual counterparts for diverse tasks and languages.
Using Semantic Information for Defining and Detecting OOD Inputs
Feb 21, 2023



As machine learning models continue to achieve impressive performance across different tasks, the importance of effective anomaly detection for such models has increased as well. It is common knowledge that even well-trained models lose their ability to function effectively on out-of-distribution inputs. Thus, out-of-distribution (OOD) detection has received some attention recently. In the vast majority of cases, it uses the distribution estimated by the training dataset for OOD detection. We demonstrate that the current detectors inherit the biases in the training dataset, unfortunately. This is a serious impediment, and can potentially restrict the utility of the trained model. This can render the current OOD detectors impermeable to inputs lying outside the training distribution but with the same semantic information (e.g. training class labels). To remedy this situation, we begin by defining what should ideally be treated as an OOD, by connecting inputs with their semantic information content. We perform OOD detection on semantic information extracted from the training data of MNIST and COCO datasets and show that it not only reduces false alarms but also significantly improves the detection of OOD inputs with spurious features from the training data.
In and Out-of-Domain Text Adversarial Robustness via Label Smoothing
Dec 20, 2022



Recently it has been shown that state-of-the-art NLP models are vulnerable to adversarial attacks, where the predictions of a model can be drastically altered by slight modifications to the input (such as synonym substitutions). While several defense techniques have been proposed, and adapted, to the discrete nature of text adversarial attacks, the benefits of general-purpose regularization methods such as label smoothing for language models, have not been studied. In this paper, we study the adversarial robustness provided by various label smoothing strategies in foundational models for diverse NLP tasks in both in-domain and out-of-domain settings. Our experiments show that label smoothing significantly improves adversarial robustness in pre-trained models like BERT, against various popular attacks. We also analyze the relationship between prediction confidence and robustness, showing that label smoothing reduces over-confident errors on adversarial examples.
Memory Classifiers: Two-stage Classification for Robustness in Machine Learning
Jun 10, 2022
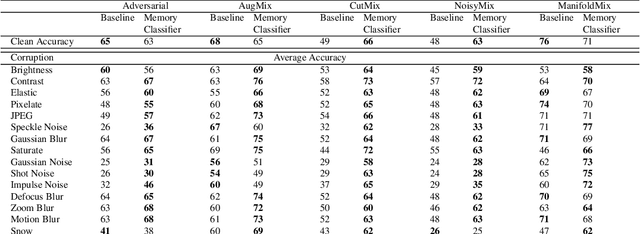
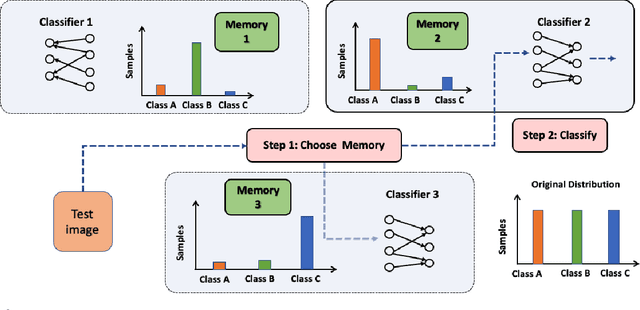
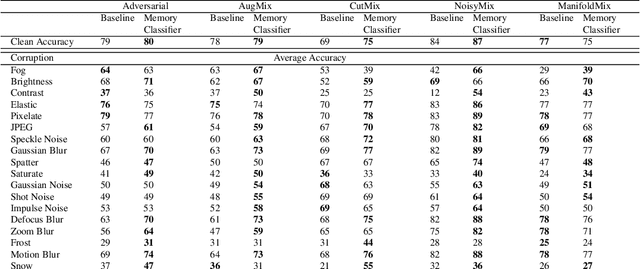
The performance of machine learning models can significantly degrade under distribution shifts of the data. We propose a new method for classification which can improve robustness to distribution shifts, by combining expert knowledge about the ``high-level" structure of the data with standard classifiers. Specifically, we introduce two-stage classifiers called \textit{memory classifiers}. First, these identify prototypical data points -- \textit{memories} -- to cluster the training data. This step is based on features designed with expert guidance; for instance, for image data they can be extracted using digital image processing algorithms. Then, within each cluster, we learn local classifiers based on finer discriminating features, via standard models like deep neural networks. We establish generalization bounds for memory classifiers. We illustrate in experiments that they can improve generalization and robustness to distribution shifts on image datasets. We show improvements which push beyond standard data augmentation techniques.