 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt2DeModel: Declarative Neuro-Symbolic Modeling with Natural Language
Jul 30, 2024



This paper presents a conversational pipeline for crafting domain knowledge for complex neuro-symbolic models through natural language prompts. It leverages large language models to generate declarative programs in the DomiKnowS framework. The programs in this framework express concepts and their relationships as a graph in addition to logical constraints between them. The graph, later, can be connected to trainable neural models according to those specifications. Our proposed pipeline utilizes techniques like dynamic in-context demonstration retrieval, model refinement based on feedback from a symbolic parser, visualization, and user interaction to generate the tasks' structure and formal knowledge representation. This approach empowers domain experts, even those not well-versed in ML/AI, to formally declare their knowledge to be incorporated in customized neural models in the DomiKnowS framework.
Consistent Joint Decision-Making with Heterogeneous Learning Models
Feb 06, 2024



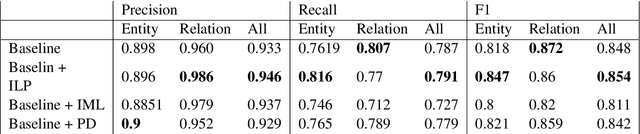
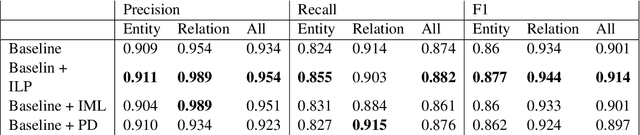
This paper introduces a novel decision-making framework that promotes consistency among decisions made by diverse models while utilizing external knowledge. Leveraging the Integer Linear Programming (ILP) framework, we map predictions from various models into globally normalized and comparable values by incorporating information about decisions' prior probability, confidence (uncertainty), and the models' expected accuracy. Our empirical study demonstrates the superiority of our approach over conventional baselines on multiple datasets.
* EACL 2024 Findings - Short Paper
GLUECons: A Generic Benchmark for Learning Under Constraints
Feb 16, 2023Recent research has shown that integrating domain knowledge into deep learning architectures is effective -- it helps reduce the amount of required data, improves the accuracy of the models' decisions, and improves the interpretability of models. However, the research community is missing a convened benchmark for systematically evaluating knowledge integration methods. In this work, we create a benchmark that is a collection of nine tasks in the domains of natural language processing and computer vision. In all cases, we model external knowledge as constraints, specify the sources of the constraints for each task, and implement various models that use these constraints. We report the results of these models using a new set of extended evaluation criteria in addition to the task performances for a more in-depth analysis. This effort provides a framework for a more comprehensive and systematic comparison of constraint integration techniques and for identifying related research challenges. It will facilitate further research for alleviating some problems of state-of-the-art neural models.
The Role of Semantic Parsing in Understanding Procedural Text
Feb 14, 2023



In this paper, we investigate whether symbolic semantic representations, extracted from deep semantic parsers, can help reasoning over the states of involved entities in a procedural text. We consider a deep semantic parser~(TRIPS) and semantic role labeling as two sources of semantic parsing knowledge. First, we propose PROPOLIS, a symbolic parsing-based procedural reasoning framework. Second, we integrate semantic parsing information into state-of-the-art neural models to conduct procedural reasoning. Our experiments indicate that explicitly incorporating such semantic knowledge improves procedural understanding. This paper presents new metrics for evaluating procedural reasoning tasks that clarify the challenges and identify differences among neural, symbolic, and integrated models.
CrisisLTLSum: A Benchmark for Local Crisis Event Timeline Extraction and Summarization
Oct 25, 2022



Social media has increasingly played a key role in emergency response: first responders can use public posts to better react to ongoing crisis events and deploy the necessary resources where they are most needed. Timeline extraction and abstractive summarization are critical technical tasks to leverage large numbers of social media posts about events. Unfortunately, there are few datasets for benchmarking technical approaches for those tasks. This paper presents CrisisLTLSum, the largest dataset of local crisis event timelines available to date. CrisisLTLSum contains 1,000 crisis event timelines across four domains: wildfires, local fires, traffic, and storms. We built CrisisLTLSum using a semi-automated cluster-then-refine approach to collect data from the public Twitter stream. Our initial experiments indicate a significant gap between the performance of strong baselines compared to the human performance on both tasks. Our dataset, code, and models are publicly available.
DomiKnowS: A Library for Integration of Symbolic Domain Knowledge in Deep Learning
Aug 27, 2021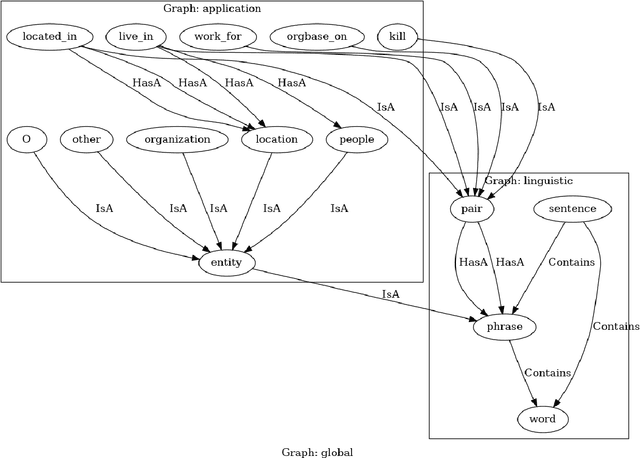

We demonstrate a library for the integration of domain knowledge in deep learning architectures. Using this library, the structure of the data is expressed symbolically via graph declarations and the logical constraints over outputs or latent variables can be seamlessly added to the deep models. The domain knowledge can be defined explicitly, which improves the models' explainability in addition to the performance and generalizability in the low-data regime. Several approaches for such an integration of symbolic and sub-symbolic models have been introduced; however, there is no library to facilitate the programming for such an integration in a generic way while various underlying algorithms can be used. Our library aims to simplify programming for such an integration in both training and inference phases while separating the knowledge representation from learning algorithms. We showcase various NLP benchmark tasks and beyond. The framework is publicly available at Github(https://github.com/HLR/DomiKnowS).
Time-Stamped Language Model: Teaching Language Models to Understand the Flow of Events
Apr 15, 2021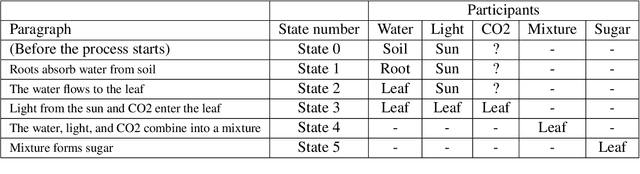
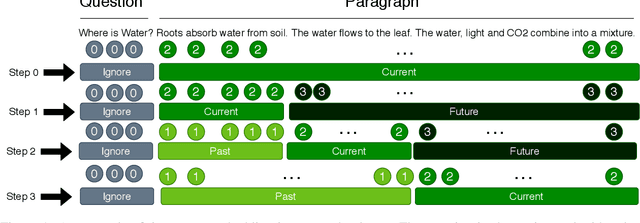
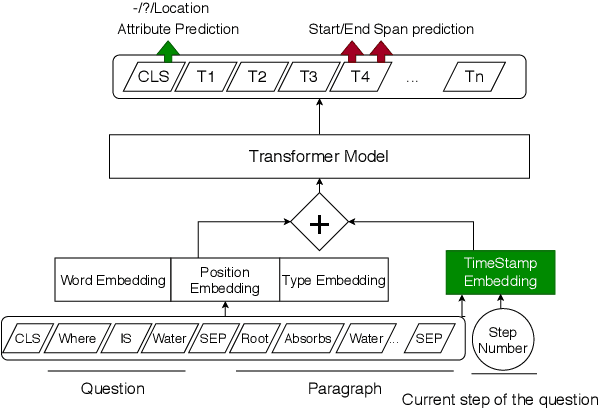
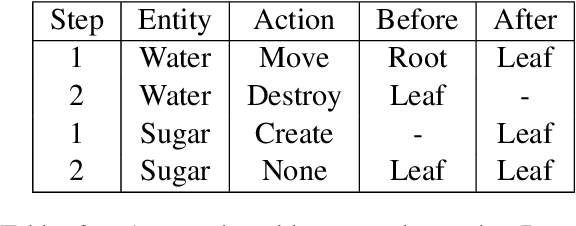
Tracking entities throughout a procedure described in a text is challenging due to the dynamic nature of the world described in the process. Firstly, we propose to formulate this task as a question answering problem. This enables us to use pre-trained transformer-based language models on other QA benchmarks by adapting those to the procedural text understanding. Secondly, since the transformer-based language models cannot encode the flow of events by themselves, we propose a Time-Stamped Language Model~(TSLM model) to encode event information in LMs architecture by introducing the timestamp encoding. Our model evaluated on the Propara dataset shows improvements on the published state-of-the-art results with a $3.1\%$ increase in F1 score. Moreover, our model yields better results on the location prediction task on the NPN-Cooking dataset. This result indicates that our approach is effective for procedural text understanding in general.
SpartQA: : A Textual Question Answering Benchmark for Spatial Reasoning
Apr 12, 2021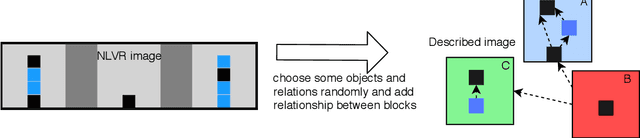
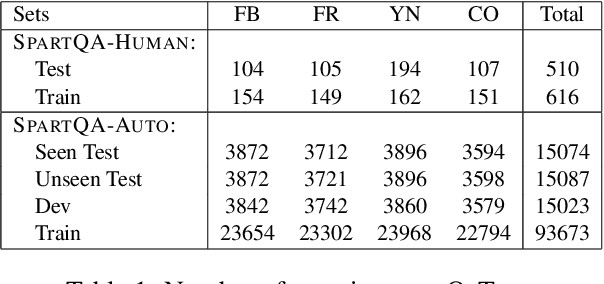
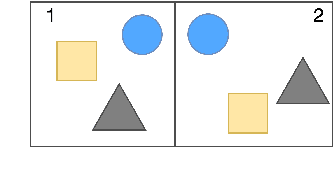
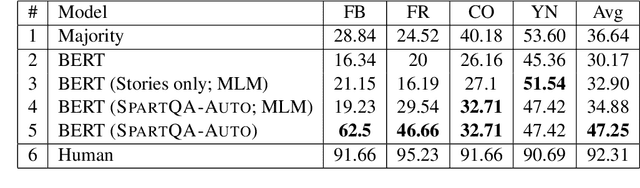
This paper proposes a question-answering (QA) benchmark for spatial reasoning on natural language text which contains more realistic spatial phenomena not covered by prior work and is challenging for state-of-the-art language models (LM). We propose a distant supervision method to improve on this task. Specifically, we design grammar and reasoning rules to automatically generate a spatial description of visual scenes and corresponding QA pairs. Experiments show that further pretraining LMs on these automatically generated data significantly improves LMs' capability on spatial understanding, which in turn helps to better solve two external datasets, bAbI, and boolQ. We hope that this work can foster investigations into more sophisticated models for spatial reasoning over text.
Latent Alignment of Procedural Concepts in Multimodal Recipes
Jan 12, 2021

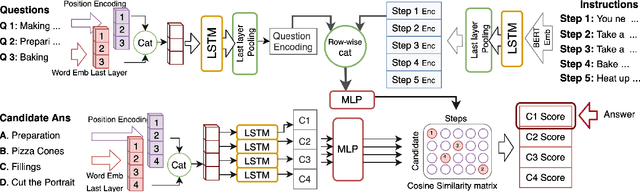
We propose a novel alignment mechanism to deal with procedural reasoning on a newly released multimodal QA dataset, named RecipeQA. Our model is solving the textual cloze task which is a reading comprehension on a recipe containing images and instructions. We exploit the power of attention networks, cross-modal representations, and a latent alignment space between instructions and candidate answers to solve the problem. We introduce constrained max-pooling which refines the max-pooling operation on the alignment matrix to impose disjoint constraints among the outputs of the model. Our evaluation result indicates a 19\% improvement over the baselines.
* Published in ALVR 2020, a workshop in ACL 2020
Hybrid-Learning approach toward situation recognition and handling
Jun 24, 2019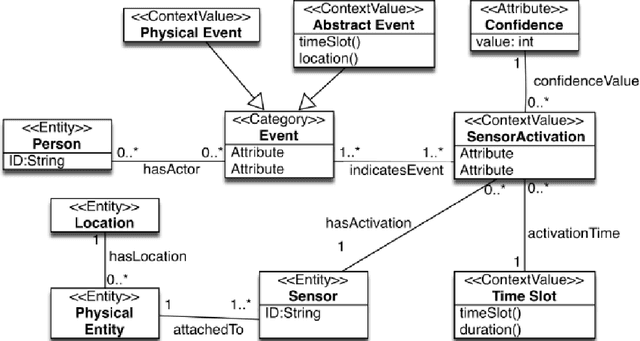
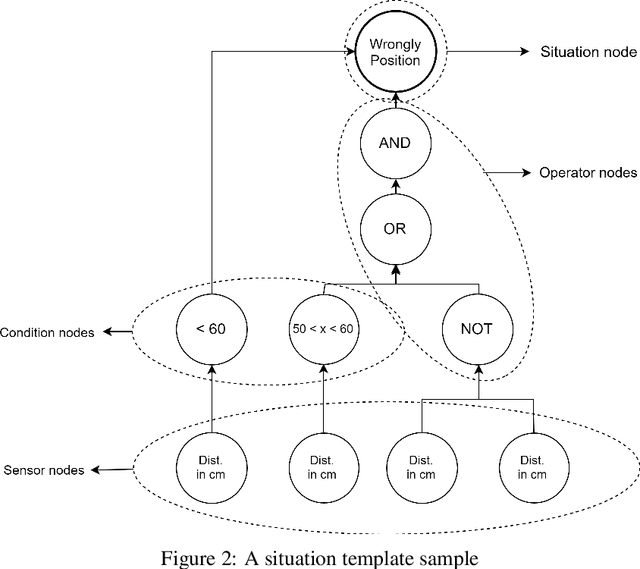
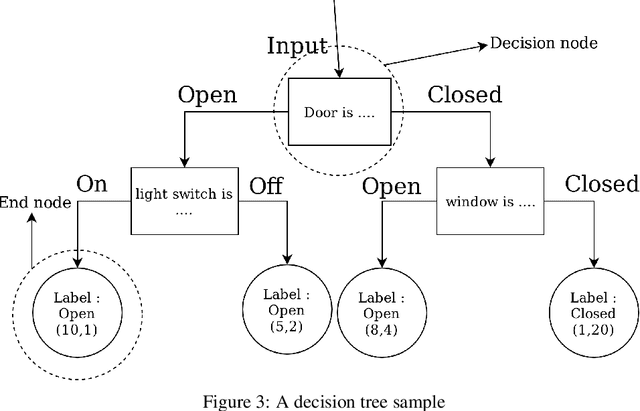
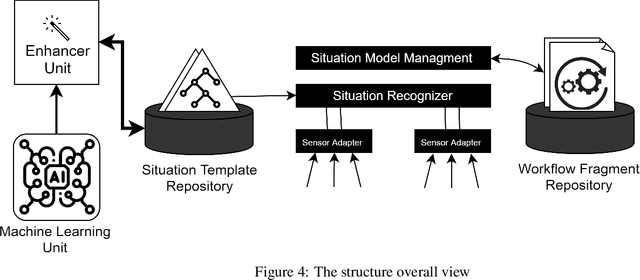
The success of smart environments largely depends on their smartness of understanding the environments' ongoing situations. Accordingly, this task is an essence to smart environment central processors. Obtaining knowledge from the environment is often through sensors, and the response to a particular circumstance is offered by actuators. This can be improved by getting user feedback, and capturing environmental changes. Machine learning techniques and semantic reasoning tools are widely used in this area to accomplish the goal of interpretation. In this paper, we have proposed a hybrid approach utilizing both machine learning and semantic reasoning tools to derive a better understanding from sensors. This method uses situation templates jointly with a decision tree to adapt the system knowledge to the environment. To test this approach we have used a simulation process which has resulted in a better precision for detecting situations in an ongoing environment involving living agents while capturing its dynamic nature.