 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Reference (In-)Determinacy in Natural Language Inference
Feb 09, 2025



We revisit the reference determinacy (RD) assumption in the task of natural language inference (NLI), i.e., the premise and hypothesis are assumed to refer to the same context when human raters annotate a label. While RD is a practical assumption for constructing a new NLI dataset, we observe that current NLI models, which are typically trained solely on hypothesis-premise pairs created with the RD assumption, fail in downstream applications such as fact verification, where the input premise and hypothesis may refer to different contexts. To highlight the impact of this phenomenon in real-world use cases, we introduce RefNLI, a diagnostic benchmark for identifying reference ambiguity in NLI examples. In RefNLI, the premise is retrieved from a knowledge source (i.e., Wikipedia) and does not necessarily refer to the same context as the hypothesis. With RefNLI, we demonstrate that finetuned NLI models and few-shot prompted LLMs both fail to recognize context mismatch, leading to over 80% false contradiction and over 50% entailment predictions. We discover that the existence of reference ambiguity in NLI examples can in part explain the inherent human disagreements in NLI and provide insight into how the RD assumption impacts the NLI dataset creation process.
Entailed Between the Lines: Incorporating Implication into NLI
Jan 13, 2025Much of human communication depends on implication, conveying meaning beyond literal words to express a wider range of thoughts, intentions, and feelings. For models to better understand and facilitate human communication, they must be responsive to the text's implicit meaning. We focus on Natural Language Inference (NLI), a core tool for many language tasks, and find that state-of-the-art NLI models and datasets struggle to recognize a range of cases where entailment is implied, rather than explicit from the text. We formalize implied entailment as an extension of the NLI task and introduce the Implied NLI dataset (INLI) to help today's LLMs both recognize a broader variety of implied entailments and to distinguish between implicit and explicit entailment. We show how LLMs fine-tuned on INLI understand implied entailment and can generalize this understanding across datasets and domains.
Scalable and Domain-General Abstractive Proposition Segmentation
Jun 28, 2024Segmenting text into fine-grained units of meaning is important to a wide range of NLP applications. The default approach of segmenting text into sentences is often insufficient, especially since sentences are usually complex enough to include multiple units of meaning that merit separate treatment in the downstream task. We focus on the task of abstractive proposition segmentation: transforming text into simple, self-contained, well-formed sentences. Several recent works have demonstrated the utility of proposition segmentation with few-shot prompted LLMs for downstream tasks such as retrieval-augmented grounding and fact verification. However, this approach does not scale to large amounts of text and may not always extract all the facts from the input text. In this paper, we first introduce evaluation metrics for the task to measure several dimensions of quality. We then propose a scalable, yet accurate, proposition segmentation model. We model proposition segmentation as a supervised task by training LLMs on existing annotated datasets and show that training yields significantly improved results. We further show that by using the fine-tuned LLMs as teachers for annotating large amounts of multi-domain synthetic distillation data, we can train smaller student models with results similar to the teacher LLMs. We then demonstrate that our technique leads to effective domain generalization, by annotating data in two domains outside the original training data and evaluating on them. Finally, as a key contribution of the paper, we share an easy-to-use API for NLP practitioners to use.
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Jun 19, 2024Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
A synthetic data approach for domain generalization of NLI models
Feb 19, 2024



Natural Language Inference (NLI) remains an important benchmark task for LLMs. NLI datasets are a springboard for transfer learning to other semantic tasks, and NLI models are standard tools for identifying the faithfulness of model-generated text. There are several large scale NLI datasets today, and models have improved greatly by hill-climbing on these collections. Yet their realistic performance on out-of-distribution/domain data is less well-understood. We present an in-depth exploration of the problem of domain generalization of NLI models. We demonstrate a new approach for generating synthetic NLI data in diverse domains and lengths, so far not covered by existing training sets. The resulting examples have meaningful premises, the hypotheses are formed in creative ways rather than simple edits to a few premise tokens, and the labels have high accuracy. We show that models trained on this data ($685$K synthetic examples) have the best generalization to completely new downstream test settings. On the TRUE benchmark, a T5-small model trained with our data improves around $7\%$ on average compared to training on the best alternative dataset. The improvements are more pronounced for smaller models, while still meaningful on a T5 XXL model. We also demonstrate gains on test sets when in-domain training data is augmented with our domain-general synthetic data.
LAIT: Efficient Multi-Segment Encoding in Transformers with Layer-Adjustable Interaction
May 31, 2023



Transformer encoders contextualize token representations by attending to all other tokens at each layer, leading to quadratic increase in compute effort with the input length. In practice, however, the input text of many NLP tasks can be seen as a sequence of related segments (e.g., the sequence of sentences within a passage, or the hypothesis and premise in NLI). While attending across these segments is highly beneficial for many tasks, we hypothesize that this interaction can be delayed until later encoding stages. To this end, we introduce Layer-Adjustable Interactions in Transformers (LAIT). Within LAIT, segmented inputs are first encoded independently, and then jointly. This partial two-tower architecture bridges the gap between a Dual Encoder's ability to pre-compute representations for segments and a fully self-attentive Transformer's capacity to model cross-segment attention. The LAIT framework effectively leverages existing pretrained Transformers and converts them into the hybrid of the two aforementioned architectures, allowing for easy and intuitive control over the performance-efficiency tradeoff. Experimenting on a wide range of NLP tasks, we find LAIT able to reduce 30-50% of the attention FLOPs on many tasks, while preserving high accuracy; in some practical settings, LAIT could reduce actual latency by orders of magnitude.
PropSegmEnt: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition
Dec 21, 2022The widely studied task of Natural Language Inference (NLI) requires a system to recognize whether one piece of text is textually entailed by another, i.e. whether the entirety of its meaning can be inferred from the other. In current NLI datasets and models, textual entailment relations are typically defined on the sentence- or paragraph-level. However, even a simple sentence often contains multiple propositions, i.e. distinct units of meaning conveyed by the sentence. As these propositions can carry different truth values in the context of a given premise, we argue for the need to recognize the textual entailment relation of each proposition in a sentence individually. We propose PropSegmEnt, a corpus of over 35K propositions annotated by expert human raters. Our dataset structure resembles the tasks of (1) segmenting sentences within a document to the set of propositions, and (2) classifying the entailment relation of each proposition with respect to a different yet topically-aligned document, i.e. documents describing the same event or entity. We establish strong baselines for the segmentation and entailment tasks. Through case studies on summary hallucination detection and document-level NLI, we demonstrate that our conceptual framework is potentially useful for understanding and explaining the compositionality of NLI labels.
Stretching Sentence-pair NLI Models to Reason over Long Documents and Clusters
Apr 15, 2022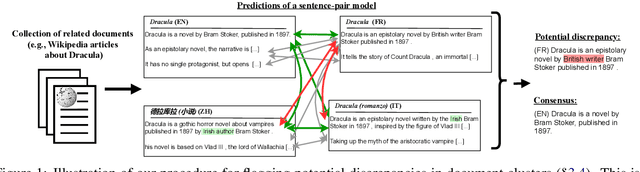

Natural Language Inference (NLI) has been extensively studied by the NLP community as a framework for estimating the semantic relation between sentence pairs. While early work identified certain biases in NLI models, recent advancements in modeling and datasets demonstrated promising performance. In this work, we further explore the direct zero-shot applicability of NLI models to real applications, beyond the sentence-pair setting they were trained on. First, we analyze the robustness of these models to longer and out-of-domain inputs. Then, we develop new aggregation methods to allow operating over full documents, reaching state-of-the-art performance on the ContractNLI dataset. Interestingly, we find NLI scores to provide strong retrieval signals, leading to more relevant evidence extractions compared to common similarity-based methods. Finally, we go further and investigate whole document clusters to identify both discrepancies and consensus among sources. In a test case, we find real inconsistencies between Wikipedia pages in different languages about the same topic.
BusTr: Predicting Bus Travel Times from Real-Time Traffic
Jul 02, 2020
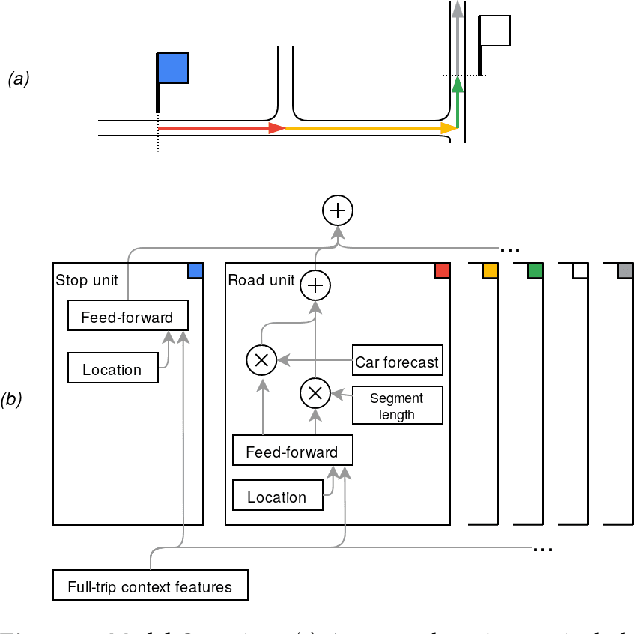

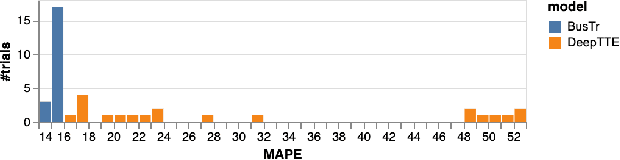
We present BusTr, a machine-learned model for translating road traffic forecasts into predictions of bus delays, used by Google Maps to serve the majority of the world's public transit systems where no official real-time bus tracking is provided. We demonstrate that our neural sequence model improves over DeepTTE, the state-of-the-art baseline, both in performance (-30% MAPE) and training stability. We also demonstrate significant generalization gains over simpler models, evaluated on longitudinal data to cope with a constantly evolving world.
Your Two Weeks of Fame and Your Grandmother's
Apr 19, 2012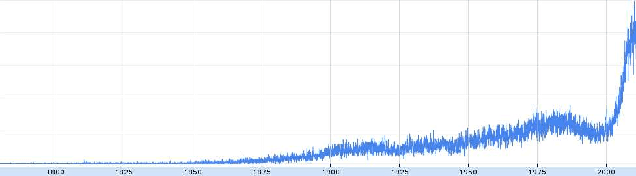
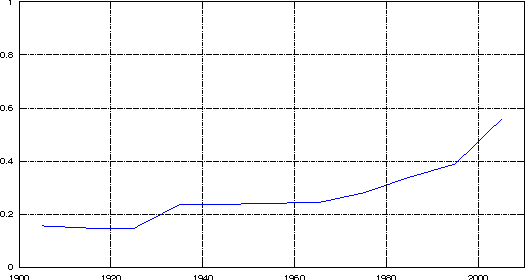
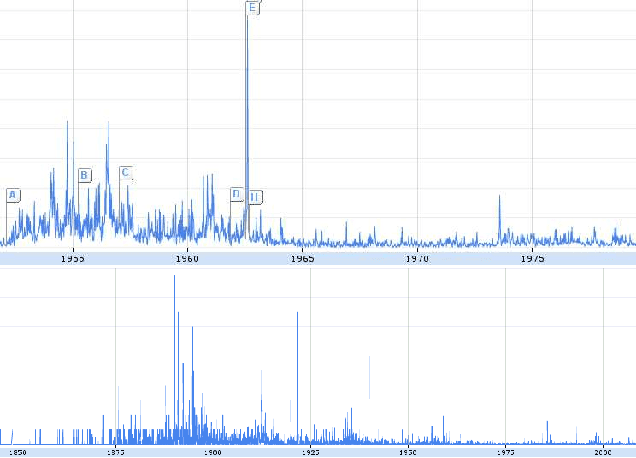
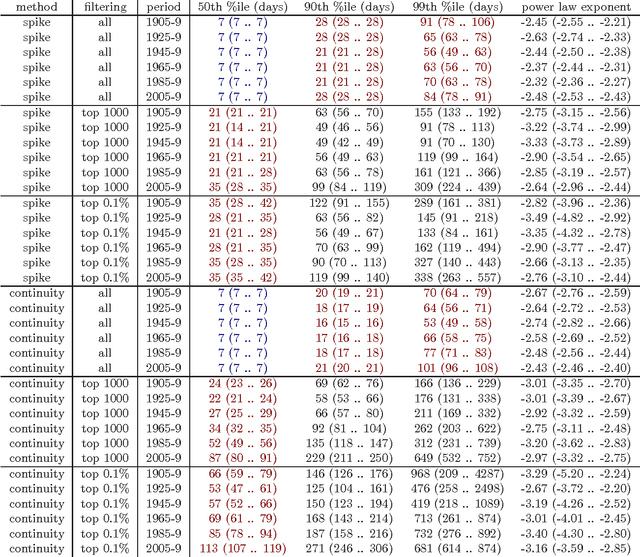
Did celebrity last longer in 1929, 1992 or 2009? We investigate the phenomenon of fame by mining a collection of news articles that spans the twentieth century, and also perform a side study on a collection of blog posts from the last 10 years. By analyzing mentions of personal names, we measure each person's time in the spotlight, using two simple metrics that evaluate, roughly, the duration of a single news story about a person, and the overall duration of public interest in a person. We watched the distribution evolve from 1895 to 2010, expecting to find significantly shortening fame durations, per the much popularly bemoaned shortening of society's attention spans and quickening of media's news cycles. Instead, we conclusively demonstrate that, through many decades of rapid technological and societal change, through the appearance of Twitter, communication satellites, and the Internet, fame durations did not decrease, neither for the typical case nor for the extremely famous, with the last statistically significant fame duration decreases coming in the early 20th century, perhaps from the spread of telegraphy and telephony. Furthermore, while median fame durations stayed persistently constant, for the most famous of the famous, as measured by either volume or duration of media attention, fame durations have actually trended gently upward since the 1940s, with statistically significant increases on 40-year timescales. Similar studies have been done with much shorter timescales specifically in the context of information spreading on Twitter and similar social networking sites. To the best of our knowledge, this is the first massive scale study of this nature that spans over a century of archived data, thereby allowing us to track changes across decades.