 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODESTRUCT: Code Agents over Structured Action Spaces
Apr 07, 2026LLM-based code agents treat repositories as unstructured text, applying edits through brittle string matching that frequently fails due to formatting drift or ambiguous patterns. We propose reframing the codebase as a structured action space where agents operate on named AST entities rather than text spans. Our framework, CODESTRUCT, provides readCode for retrieving complete syntactic units and editCode for applying syntax-validated transformations to semantic program elements. Evaluated on SWE-Bench Verified across six LLMs, CODESTRUCT improves Pass@1 accuracy by 1.2-5.0% while reducing token consumption by 12-38% for most models. Models that frequently fail to produce valid patches under text-based interfaces benefit most: GPT-5-nano improves by 20.8% as empty-patch failures drop from 46.6% to 7.2%. On CodeAssistBench, we observe consistent accuracy gains (+0.8-4.4%) with cost reductions up to 33%. Our results show that structure-aware interfaces offer a more reliable foundation for code agents.
TRAJEVAL: Decomposing Code Agent Trajectories for Fine-Grained Diagnosis
Mar 25, 2026Code agents can autonomously resolve GitHub issues, yet when they fail, current evaluation provides no visibility into where or why. Metrics such as Pass@1 collapse an entire execution into a single binary outcome, making it difficult to identify where and why the agent went wrong. To address this limitation, we introduce TRAJEVAL, a diagnostic framework that decomposes agent trajectories into three interpretable stages: search (file localization), read (function comprehension), and edit (modification targeting). For each stage, we compute precision and recall by comparing against reference patches. Analyzing 16,758 trajectories across three agent architectures and seven models, we find universal inefficiencies (all agents examine approximately 22x more functions than necessary) yet distinct failure modes: GPT-5 locates relevant code but targets edits incorrectly, while Qwen-32B fails at file discovery entirely. We validate that these diagnostics are predictive, achieving model-level Pass@1 prediction within 0.87-2.1% MAE, and actionable: real-time feedback based on trajectory signals improves two state-of-the-art models by 2.2-4.6 percentage points while reducing costs by 20-31%. These results demonstrate that our framework not only provides a more fine-grained analysis of agent behavior, but also translates diagnostic signals into tangible performance gains. More broadly, TRAJEVAL transforms agent evaluation beyond outcome-based benchmarking toward mechanism-driven diagnosis of agent success and failure.
Empowering Multi-Turn Tool-Integrated Reasoning with Group Turn Policy Optimization
Nov 18, 2025
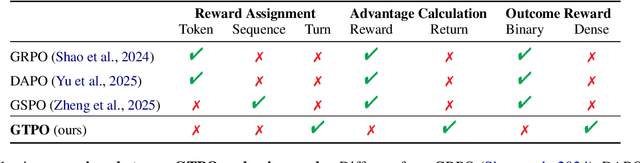
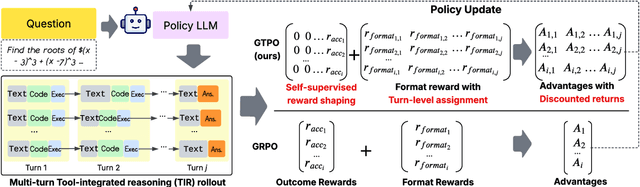
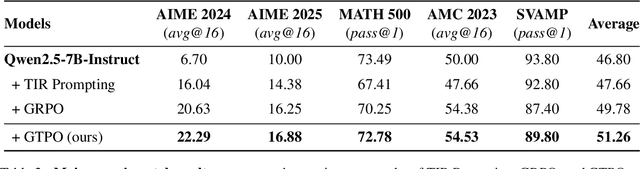
Training Large Language Models (LLMs) for multi-turn Tool-Integrated Reasoning (TIR) - where models iteratively reason, generate code, and verify through execution - remains challenging for existing reinforcement learning (RL) approaches. Current RL methods, exemplified by Group Relative Policy Optimization (GRPO), suffer from coarse-grained, trajectory-level rewards that provide insufficient learning signals for complex multi-turn interactions, leading to training stagnation. To address this issue, we propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces three key innovations: (1) turn-level reward assignment that provides fine-grained feedback for individual turns, (2) return-based advantage estimation where normalized discounted returns are calculated as advantages, and (3) self-supervised reward shaping that exploits self-supervision signals from generated code to densify sparse binary outcome-based rewards. Our comprehensive evaluation demonstrates that GTPO outperforms GRPO by 3.0% on average across diverse reasoning benchmarks, establishing its effectiveness for advancing complex mathematical reasoning in the real world.
Breaking the Code: Security Assessment of AI Code Agents Through Systematic Jailbreaking Attacks
Oct 01, 2025Code-capable large language model (LLM) agents are increasingly embedded into software engineering workflows where they can read, write, and execute code, raising the stakes of safety-bypass ("jailbreak") attacks beyond text-only settings. Prior evaluations emphasize refusal or harmful-text detection, leaving open whether agents actually compile and run malicious programs. We present JAWS-BENCH (Jailbreaks Across WorkSpaces), a benchmark spanning three escalating workspace regimes that mirror attacker capability: empty (JAWS-0), single-file (JAWS-1), and multi-file (JAWS-M). We pair this with a hierarchical, executable-aware Judge Framework that tests (i) compliance, (ii) attack success, (iii) syntactic correctness, and (iv) runtime executability, moving beyond refusal to measure deployable harm. Using seven LLMs from five families as backends, we find that under prompt-only conditions in JAWS-0, code agents accept 61% of attacks on average; 58% are harmful, 52% parse, and 27% run end-to-end. Moving to single-file regime in JAWS-1 drives compliance to ~ 100% for capable models and yields a mean ASR (Attack Success Rate) ~ 71%; the multi-file regime (JAWS-M) raises mean ASR to ~ 75%, with 32% instantly deployable attack code. Across models, wrapping an LLM in an agent substantially increases vulnerability -- ASR raises by 1.6x -- because initial refusals are frequently overturned during later planning/tool-use steps. Category-level analyses identify which attack classes are most vulnerable and most readily deployable, while others exhibit large execution gaps. These findings motivate execution-aware defenses, code-contextual safety filters, and mechanisms that preserve refusal decisions throughout the agent's multi-step reasoning and tool use.
Fusion DeepONet: A Data-Efficient Neural Operator for Geometry-Dependent Hypersonic Flows on Arbitrary Grids
Jan 03, 2025Designing re-entry vehicles requires accurate predictions of hypersonic flow around their geometry. Rapid prediction of such flows can revolutionize vehicle design, particularly for morphing geometries. We evaluate advanced neural operator models such as Deep Operator Networks (DeepONet), parameter-conditioned U-Net, Fourier Neural Operator (FNO), and MeshGraphNet, with the objective of addressing the challenge of learning geometry-dependent hypersonic flow fields with limited data. Specifically, we compare the performance of these models for two grid types: uniform Cartesian and irregular grids. To train these models, we use 36 unique elliptic geometries for generating high-fidelity simulations with a high-order entropy-stable DGSEM solver, emphasizing the challenge of working with a scarce dataset. We evaluate and compare the four operator-based models for their efficacy in predicting hypersonic flow field around the elliptic body. Moreover, we develop a novel framework, called Fusion DeepONet, which leverages neural field concepts and generalizes effectively across varying geometries. Despite the scarcity of training data, Fusion DeepONet achieves performance comparable to parameter-conditioned U-Net on uniform grids while it outperforms MeshGraphNet and vanilla DeepONet on irregular, arbitrary grids. Fusion DeepONet requires significantly fewer trainable parameters as compared to U-Net, MeshGraphNet, and FNO, making it computationally efficient. We also analyze the basis functions of the Fusion DeepONet model using Singular Value Decomposition. This analysis reveals that Fusion DeepONet generalizes effectively to unseen solutions and adapts to varying geometries and grid points, demonstrating its robustness in scenarios with limited training data.
A Digital twin for Diesel Engines: Operator-infused PINNs with Transfer Learning for Engine Health Monitoring
Dec 16, 2024Improving diesel engine efficiency and emission reduction have been critical research topics. Recent government regulations have shifted this focus to another important area related to engine health and performance monitoring. Although the advancements in the use of deep learning methods for system monitoring have shown promising results in this direction, designing efficient methods suitable for field systems remains an open research challenge. The objective of this study is to develop a computationally efficient neural network-based approach for identifying unknown parameters of a mean value diesel engine model to facilitate physics-based health monitoring and maintenance forecasting. We propose a hybrid method combining physics informed neural networks, PINNs, and a deep neural operator, DeepONet to predict unknown parameters and gas flow dynamics in a diesel engine. The operator network predicts independent actuator dynamics learnt through offline training, thereby reducing the PINNs online computational cost. To address PINNs need for retraining with changing input scenarios, we propose two transfer learning (TL) strategies. The first strategy involves multi-stage transfer learning for parameter identification. While this method is computationally efficient as compared to online PINN training, improvements are required to meet field requirements. The second TL strategy focuses solely on training the output weights and biases of a subset of multi-head networks pretrained on a larger dataset, substantially reducing computation time during online prediction. We also evaluate our model for epistemic and aleatoric uncertainty by incorporating dropout in pretrained networks and Gaussian noise in the training dataset. This strategy offers a tailored, computationally inexpensive, and physics-based approach for parameter identification in diesel engine sub systems.
Horizon-Length Prediction: Advancing Fill-in-the-Middle Capabilities for Code Generation with Lookahead Planning
Oct 04, 2024Fill-in-the-Middle (FIM) has become integral to code language models, enabling generation of missing code given both left and right contexts. However, the current FIM training paradigm, which reorders original training sequences and then performs regular next-token prediction (NTP), often leads to models struggling to generate content that aligns smoothly with the surrounding context. Crucially, while existing works rely on rule-based post-processing to circumvent this weakness, such methods are not practically usable in open-domain code completion tasks as they depend on restrictive, dataset-specific assumptions (e.g., generating the same number of lines as in the ground truth). Moreover, model performance on FIM tasks deteriorates significantly without these unrealistic assumptions. We hypothesize that NTP alone is insufficient for models to learn effective planning conditioned on the distant right context, a critical factor for successful code infilling. To overcome this, we propose Horizon-Length Prediction (HLP), a novel training objective that teaches models to predict the number of remaining middle tokens (i.e., horizon length) at each step. HLP advances FIM with lookahead planning, enabling models to inherently learn infilling boundaries for arbitrary left and right contexts without relying on dataset-specific post-processing. Our evaluation across different models and sizes shows that HLP significantly improves FIM performance by up to 24% relatively on diverse benchmarks, across file-level and repository-level, and without resorting to unrealistic post-processing methods. Furthermore, the enhanced planning capability gained through HLP boosts model performance on code reasoning. Importantly, HLP only incurs negligible training overhead and no additional inference cost, ensuring its practicality for real-world scenarios.
Learning Code Preference via Synthetic Evolution
Oct 04, 2024



Large Language Models (LLMs) have recently demonstrated remarkable coding capabilities. However, assessing code generation based on well-formed properties and aligning it with developer preferences remains challenging. In this paper, we explore two key questions under the new challenge of code preference learning: (i) How do we train models to predict meaningful preferences for code? and (ii) How do human and LLM preferences align with verifiable code properties and developer code tastes? To this end, we propose CodeFavor, a framework for training pairwise code preference models from synthetic evolution data, including code commits and code critiques. To evaluate code preferences, we introduce CodePrefBench, a benchmark comprising 1364 rigorously curated code preference tasks to cover three verifiable properties-correctness, efficiency, and security-along with human preference. Our evaluation shows that CodeFavor holistically improves the accuracy of model-based code preferences by up to 28.8%. Meanwhile, CodeFavor models can match the performance of models with 6-9x more parameters while being 34x more cost-effective. We also rigorously validate the design choices in CodeFavor via a comprehensive set of controlled experiments. Furthermore, we discover the prohibitive costs and limitations of human-based code preference: despite spending 23.4 person-minutes on each task, 15.1-40.3% of tasks remain unsolved. Compared to model-based preference, human preference tends to be more accurate under the objective of code correctness, while being sub-optimal for non-functional objectives.
Synergistic Learning with Multi-Task DeepONet for Efficient PDE Problem Solving
Aug 05, 2024Multi-task learning (MTL) is an inductive transfer mechanism designed to leverage useful information from multiple tasks to improve generalization performance compared to single-task learning. It has been extensively explored in traditional machine learning to address issues such as data sparsity and overfitting in neural networks. In this work, we apply MTL to problems in science and engineering governed by partial differential equations (PDEs). However, implementing MTL in this context is complex, as it requires task-specific modifications to accommodate various scenarios representing different physical processes. To this end, we present a multi-task deep operator network (MT-DeepONet) to learn solutions across various functional forms of source terms in a PDE and multiple geometries in a single concurrent training session. We introduce modifications in the branch network of the vanilla DeepONet to account for various functional forms of a parameterized coefficient in a PDE. Additionally, we handle parameterized geometries by introducing a binary mask in the branch network and incorporating it into the loss term to improve convergence and generalization to new geometry tasks. Our approach is demonstrated on three benchmark problems: (1) learning different functional forms of the source term in the Fisher equation; (2) learning multiple geometries in a 2D Darcy Flow problem and showcasing better transfer learning capabilities to new geometries; and (3) learning 3D parameterized geometries for a heat transfer problem and demonstrate the ability to predict on new but similar geometries. Our MT-DeepONet framework offers a novel approach to solving PDE problems in engineering and science under a unified umbrella based on synergistic learning that reduces the overall training cost for neural operators.
On Mitigating Code LLM Hallucinations with API Documentation
Jul 13, 2024



In this study, we address the issue of API hallucinations in various software engineering contexts. We introduce CloudAPIBench, a new benchmark designed to measure API hallucination occurrences. CloudAPIBench also provides annotations for frequencies of API occurrences in the public domain, allowing us to study API hallucinations at various frequency levels. Our findings reveal that Code LLMs struggle with low frequency APIs: for e.g., GPT-4o achieves only 38.58% valid low frequency API invocations. We demonstrate that Documentation Augmented Generation (DAG) significantly improves performance for low frequency APIs (increase to 47.94% with DAG) but negatively impacts high frequency APIs when using sub-optimal retrievers (a 39.02% absolute drop). To mitigate this, we propose to intelligently trigger DAG where we check against an API index or leverage Code LLMs' confidence scores to retrieve only when needed. We demonstrate that our proposed methods enhance the balance between low and high frequency API performance, resulting in more reliable API invocations (8.20% absolute improvement on CloudAPIBench for GPT-4o).