 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Contrastive Learning for Robust Reasoning in VQA
Nov 21, 2022Multi-modal reasoning in visual question answering (VQA) has witnessed rapid progress recently. However, most reasoning models heavily rely on shortcuts learned from training data, which prevents their usage in challenging real-world scenarios. In this paper, we propose a simple but effective cross-modal contrastive learning strategy to get rid of the shortcut reasoning caused by imbalanced annotations and improve the overall performance. Different from existing contrastive learning with complex negative categories on coarse (Image, Question, Answer) triplet level, we leverage the correspondences between the language and image modalities to perform finer-grained cross-modal contrastive learning. We treat each Question-Answer (QA) pair as a whole, and differentiate between images that conform with it and those against it. To alleviate the issue of sampling bias, we further build connected graphs among images. For each positive pair, we regard the images from different graphs as negative samples and deduct the version of multi-positive contrastive learning. To our best knowledge, it is the first paper that reveals a general contrastive learning strategy without delicate hand-craft rules can contribute to robust VQA reasoning. Experiments on several mainstream VQA datasets demonstrate our superiority compared to the state of the arts. Code is available at \url{https://github.com/qizhust/cmcl_vqa_pl}.
SLLEN: Semantic-aware Low-light Image Enhancement Network
Nov 21, 2022How to effectively explore semantic feature is vital for low-light image enhancement (LLE). Existing methods usually utilize the semantic feature that is only drawn from the semantic map produced by high-level semantic segmentation network (SSN). However, if the semantic map is not accurately estimated, it would affect the high-level semantic feature (HSF) extraction, which accordingly interferes with LLE. In this paper, we develop a simple yet effective two-branch semantic-aware LLE network (SLLEN) that neatly integrates the random intermediate embedding feature (IEF) (i.e., the information extracted from the intermediate layer of semantic segmentation network) together with the HSF into a unified framework for better LLE. Specifically, for one branch, we utilize an attention mechanism to integrate HSF into low-level feature. For the other branch, we extract IEF to guide the adjustment of low-level feature using nonlinear transformation manner. Finally, semantic-aware features obtained from two branches are fused and decoded for image enhancement. It is worth mentioning that IEF has some randomness compared to HSF despite their similarity on semantic characteristics, thus its introduction can allow network to learn more possibilities by leveraging the latent relationships between the low-level feature and semantic feature, just like the famous saying "God rolls the dice" in Physics Nobel Prize 2022. Comparisons between the proposed SLLEN and other state-of-the-art techniques demonstrate the superiority of SLLEN with respect to LLE quality over all the comparable alternatives.
Adaptive Edge-to-Edge Interaction Learning for Point Cloud Analysis
Nov 20, 2022



Recent years have witnessed the great success of deep learning on various point cloud analysis tasks, e.g., classification and semantic segmentation. Since point cloud data is sparse and irregularly distributed, one key issue for point cloud data processing is extracting useful information from local regions. To achieve this, previous works mainly extract the points' features from local regions by learning the relation between each pair of adjacent points. However, these works ignore the relation between edges in local regions, which encodes the local shape information. Associating the neighbouring edges could potentially make the point-to-point relation more aware of the local structure and more robust. To explore the role of the relation between edges, this paper proposes a novel Adaptive Edge-to-Edge Interaction Learning module, which aims to enhance the point-to-point relation through modelling the edge-to-edge interaction in the local region adaptively. We further extend the module to a symmetric version to capture the local structure more thoroughly. Taking advantage of the proposed modules, we develop two networks for segmentation and shape classification tasks, respectively. Various experiments on several public point cloud datasets demonstrate the effectiveness of our method for point cloud analysis.
Unifying Flow, Stereo and Depth Estimation
Nov 10, 2022



We present a unified formulation and model for three motion and 3D perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation from posed images. Unlike previous specialized architectures for each specific task, we formulate all three tasks as a unified dense correspondence matching problem, which can be solved with a single model by directly comparing feature similarities. Such a formulation calls for discriminative feature representations, which we achieve using a Transformer, in particular the cross-attention mechanism. We demonstrate that cross-attention enables integration of knowledge from another image via cross-view interactions, which greatly improves the quality of the extracted features. Our unified model naturally enables cross-task transfer since the model architecture and parameters are shared across tasks. We outperform RAFT with our unified model on the challenging Sintel dataset, and our final model that uses a few additional task-specific refinement steps outperforms or compares favorably to recent state-of-the-art methods on 10 popular flow, stereo and depth datasets, while being simpler and more efficient in terms of model design and inference speed.
Cherry Hypothesis: Identifying the Cherry on the Cake for Dynamic Networks
Nov 10, 2022



Dynamic networks have been extensively explored as they can considerably improve the model's representation power with acceptable computational cost. The common practice in implementing dynamic networks is to convert given static layers into fully dynamic ones where all parameters are dynamic and vary with the input. Recent studies empirically show the trend that the more dynamic layers contribute to ever-increasing performance. However, such a fully dynamic setting 1) may cause redundant parameters and high deployment costs, limiting the applicability of dynamic networks to a broader range of tasks and models, and more importantly, 2) contradicts the previous discovery in the human brain that \textit{when human brains process an attention-demanding task, only partial neurons in the task-specific areas are activated by the input, while the rest neurons leave in a baseline state.} Critically, there is no effort to understand and resolve the above contradictory finding, leaving the primal question -- to make the computational parameters fully dynamic or not? -- unanswered. The main contributions of our work are challenging the basic commonsense in dynamic networks, and, proposing and validating the \textsc{cherry hypothesis} -- \textit{A fully dynamic network contains a subset of dynamic parameters that when transforming other dynamic parameters into static ones, can maintain or even exceed the performance of the original network.} Technically, we propose a brain-inspired partially dynamic network, namely PAD-Net, to transform the redundant dynamic parameters into static ones. Also, we further design Iterative Mode Partition to partition the dynamic- and static-subnet, which alleviates the redundancy in traditional fully dynamic networks. Our hypothesis and method are comprehensively supported by large-scale experiments with typical advanced dynamic methods.
Rethinking Hierarchies in Pre-trained Plain Vision Transformer
Nov 08, 2022


Self-supervised pre-training vision transformer (ViT) via masked image modeling (MIM) has been proven very effective. However, customized algorithms should be carefully designed for the hierarchical ViTs, e.g., GreenMIM, instead of using the vanilla and simple MAE for the plain ViT. More importantly, since these hierarchical ViTs cannot reuse the off-the-shelf pre-trained weights of the plain ViTs, the requirement of pre-training them leads to a massive amount of computational cost, thereby incurring both algorithmic and computational complexity. In this paper, we address this problem by proposing a novel idea of disentangling the hierarchical architecture design from the self-supervised pre-training. We transform the plain ViT into a hierarchical one with minimal changes. Technically, we change the stride of linear embedding layer from 16 to 4 and add convolution (or simple average) pooling layers between the transformer blocks, thereby reducing the feature size from 1/4 to 1/32 sequentially. Despite its simplicity, it outperforms the plain ViT baseline in classification, detection, and segmentation tasks on ImageNet, MS COCO, Cityscapes, and ADE20K benchmarks, respectively. We hope this preliminary study could draw more attention from the community on developing effective (hierarchical) ViTs while avoiding the pre-training cost by leveraging the off-the-shelf checkpoints. The code and models will be released at https://github.com/ViTAE-Transformer/HPViT.
Adversarial Auto-Augment with Label Preservation: A Representation Learning Principle Guided Approach
Nov 02, 2022



Data augmentation is a critical contributing factor to the success of deep learning but heavily relies on prior domain knowledge which is not always available. Recent works on automatic data augmentation learn a policy to form a sequence of augmentation operations, which are still pre-defined and restricted to limited options. In this paper, we show that a prior-free autonomous data augmentation's objective can be derived from a representation learning principle that aims to preserve the minimum sufficient information of the labels. Given an example, the objective aims at creating a distant "hard positive example" as the augmentation, while still preserving the original label. We then propose a practical surrogate to the objective that can be optimized efficiently and integrated seamlessly into existing methods for a broad class of machine learning tasks, e.g., supervised, semi-supervised, and noisy-label learning. Unlike previous works, our method does not require training an extra generative model but instead leverages the intermediate layer representations of the end-task model for generating data augmentations. In experiments, we show that our method consistently brings non-trivial improvements to the three aforementioned learning tasks from both efficiency and final performance, either or not combined with strong pre-defined augmentations, e.g., on medical images when domain knowledge is unavailable and the existing augmentation techniques perform poorly. Code is available at: https://github.com/kai-wen-yang/LPA3}{https://github.com/kai-wen-yang/LPA3.
TASA: Deceiving Question Answering Models by Twin Answer Sentences Attack
Oct 27, 2022We present Twin Answer Sentences Attack (TASA), an adversarial attack method for question answering (QA) models that produces fluent and grammatical adversarial contexts while maintaining gold answers. Despite phenomenal progress on general adversarial attacks, few works have investigated the vulnerability and attack specifically for QA models. In this work, we first explore the biases in the existing models and discover that they mainly rely on keyword matching between the question and context, and ignore the relevant contextual relations for answer prediction. Based on two biases above, TASA attacks the target model in two folds: (1) lowering the model's confidence on the gold answer with a perturbed answer sentence; (2) misguiding the model towards a wrong answer with a distracting answer sentence. Equipped with designed beam search and filtering methods, TASA can generate more effective attacks than existing textual attack methods while sustaining the quality of contexts, in extensive experiments on five QA datasets and human evaluations.
Identifiability and Asymptotics in Learning Homogeneous Linear ODE Systems from Discrete Observations
Oct 12, 2022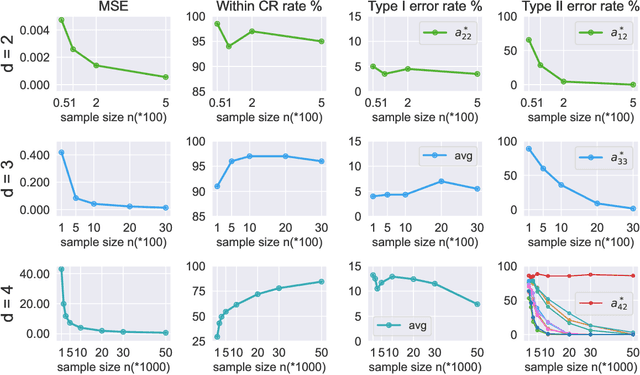
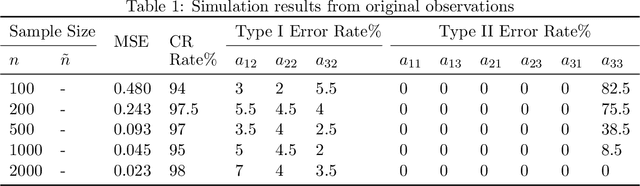
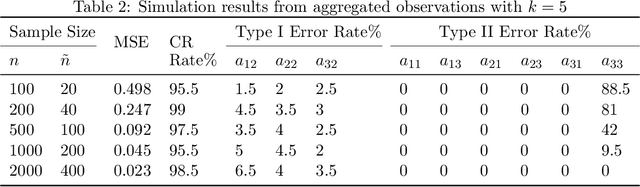
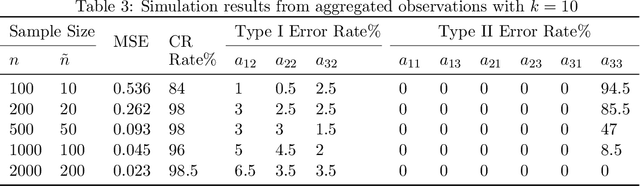
Ordinary Differential Equations (ODEs) have recently gained a lot of attention in machine learning. However, the theoretical aspects, e.g., identifiability and asymptotic properties of statistical estimation are still obscure. This paper derives a sufficient condition for the identifiability of homogeneous linear ODE systems from a sequence of equally-spaced error-free observations sampled from a single trajectory. When observations are disturbed by measurement noise, we prove that under mild conditions, the parameter estimator based on the Nonlinear Least Squares (NLS) method is consistent and asymptotic normal with $n^{-1/2}$ convergence rate. Based on the asymptotic normality property, we construct confidence sets for the unknown system parameters and propose a new method to infer the causal structure of the ODE system, i.e., inferring whether there is a causal link between system variables. Furthermore, we extend the results to degraded observations, including aggregated and time-scaled ones. To the best of our knowledge, our work is the first systematic study of the identifiability and asymptotic properties in learning linear ODE systems. We also construct simulations with various system dimensions to illustrate the established theoretical results.
Make Sharpness-Aware Minimization Stronger: A Sparsified Perturbation Approach
Oct 11, 2022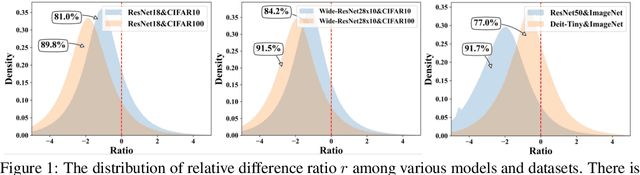
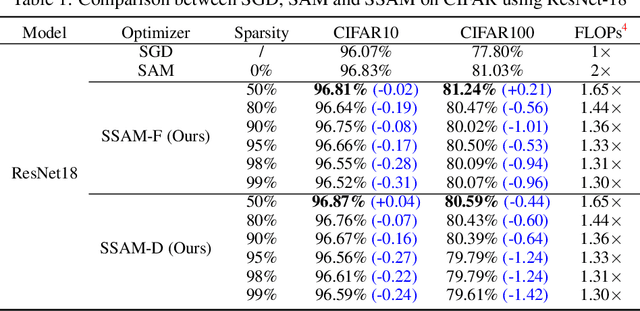
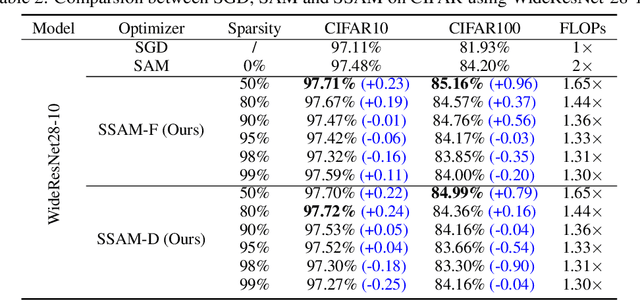
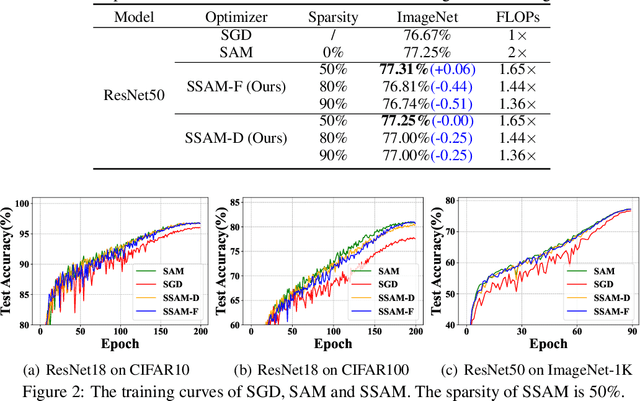
Deep neural networks often suffer from poor generalization caused by complex and non-convex loss landscapes. One of the popular solutions is Sharpness-Aware Minimization (SAM), which smooths the loss landscape via minimizing the maximized change of training loss when adding a perturbation to the weight. However, we find the indiscriminate perturbation of SAM on all parameters is suboptimal, which also results in excessive computation, i.e., double the overhead of common optimizers like Stochastic Gradient Descent (SGD). In this paper, we propose an efficient and effective training scheme coined as Sparse SAM (SSAM), which achieves sparse perturbation by a binary mask. To obtain the sparse mask, we provide two solutions which are based onFisher information and dynamic sparse training, respectively. In addition, we theoretically prove that SSAM can converge at the same rate as SAM, i.e., $O(\log T/\sqrt{T})$. Sparse SAM not only has the potential for training acceleration but also smooths the loss landscape effectively. Extensive experimental results on CIFAR10, CIFAR100, and ImageNet-1K confirm the superior efficiency of our method to SAM, and the performance is preserved or even better with a perturbation of merely 50% sparsity. Code is availiable at \url{https://github.com/Mi-Peng/Sparse-Sharpness-Aware-Minimization}.