 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Versatile Convolution Filters for Efficient Visual Recognition
Sep 20, 2021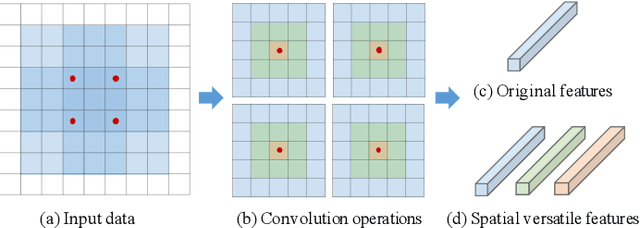
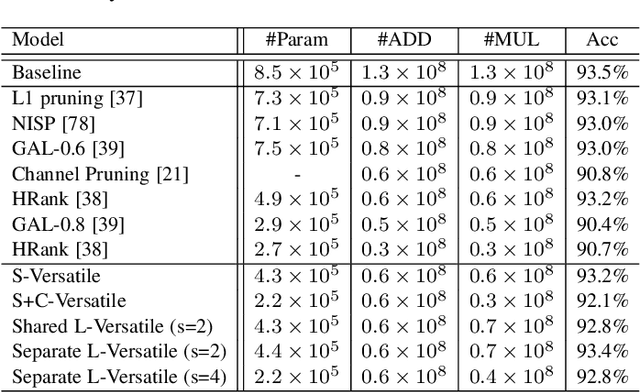
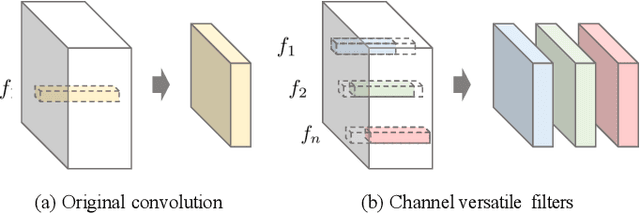
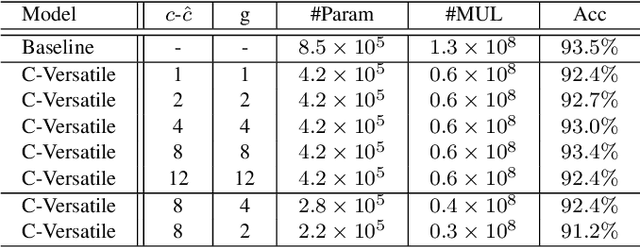
This paper introduces versatile filters to construct efficient convolutional neural networks that are widely used in various visual recognition tasks. Considering the demands of efficient deep learning techniques running on cost-effective hardware, a number of methods have been developed to learn compact neural networks. Most of these works aim to slim down filters in different ways, \eg,~investigating small, sparse or quantized filters. In contrast, we treat filters from an additive perspective. A series of secondary filters can be derived from a primary filter with the help of binary masks. These secondary filters all inherit in the primary filter without occupying more storage, but once been unfolded in computation they could significantly enhance the capability of the filter by integrating information extracted from different receptive fields. Besides spatial versatile filters, we additionally investigate versatile filters from the channel perspective. Binary masks can be further customized for different primary filters under orthogonal constraints. We conduct theoretical analysis on network complexity and an efficient convolution scheme is introduced. Experimental results on benchmark datasets and neural networks demonstrate that our versatile filters are able to achieve comparable accuracy as that of original filters, but require less memory and computation cost.
Voxel Transformer for 3D Object Detection
Sep 13, 2021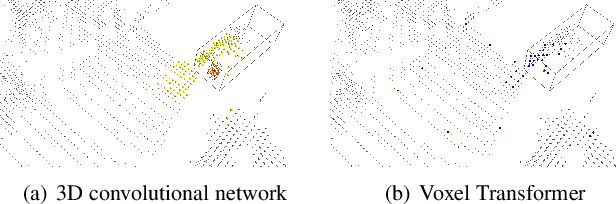
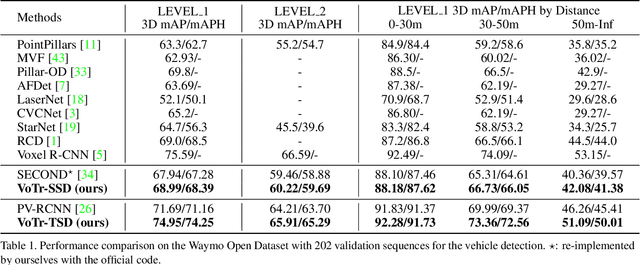
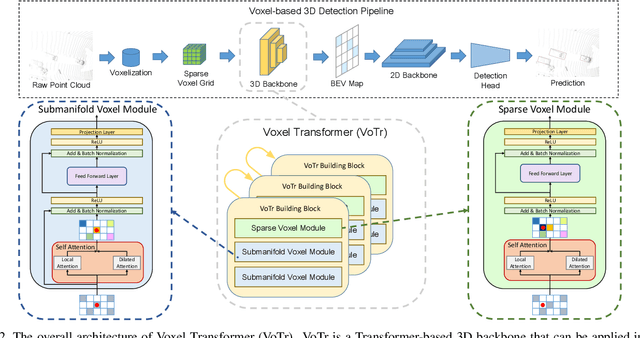
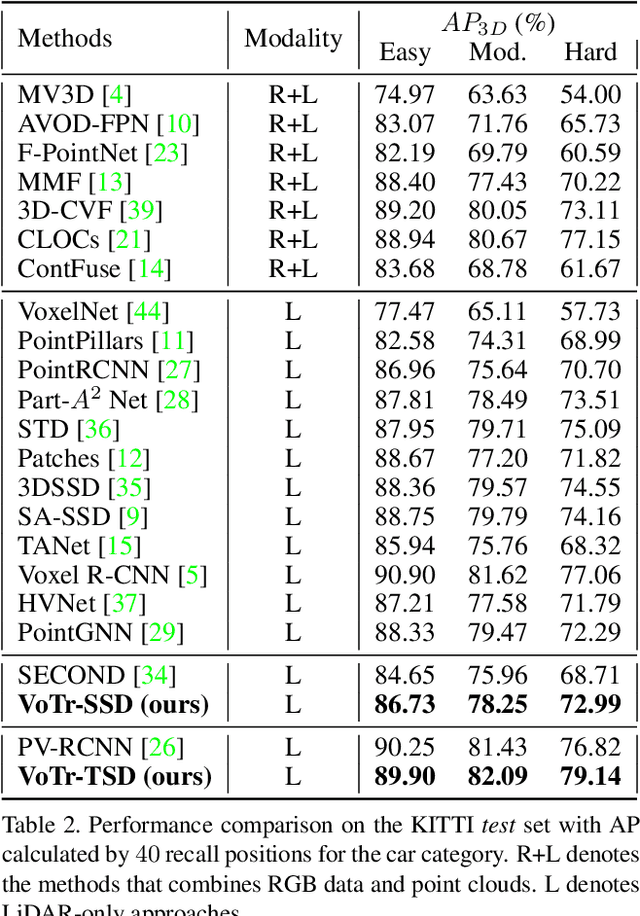
We present Voxel Transformer (VoTr), a novel and effective voxel-based Transformer backbone for 3D object detection from point clouds. Conventional 3D convolutional backbones in voxel-based 3D detectors cannot efficiently capture large context information, which is crucial for object recognition and localization, owing to the limited receptive fields. In this paper, we resolve the problem by introducing a Transformer-based architecture that enables long-range relationships between voxels by self-attention. Given the fact that non-empty voxels are naturally sparse but numerous, directly applying standard Transformer on voxels is non-trivial. To this end, we propose the sparse voxel module and the submanifold voxel module, which can operate on the empty and non-empty voxel positions effectively. To further enlarge the attention range while maintaining comparable computational overhead to the convolutional counterparts, we propose two attention mechanisms for multi-head attention in those two modules: Local Attention and Dilated Attention, and we further propose Fast Voxel Query to accelerate the querying process in multi-head attention. VoTr contains a series of sparse and submanifold voxel modules and can be applied in most voxel-based detectors. Our proposed VoTr shows consistent improvement over the convolutional baselines while maintaining computational efficiency on the KITTI dataset and the Waymo Open dataset.
Pyramid R-CNN: Towards Better Performance and Adaptability for 3D Object Detection
Sep 06, 2021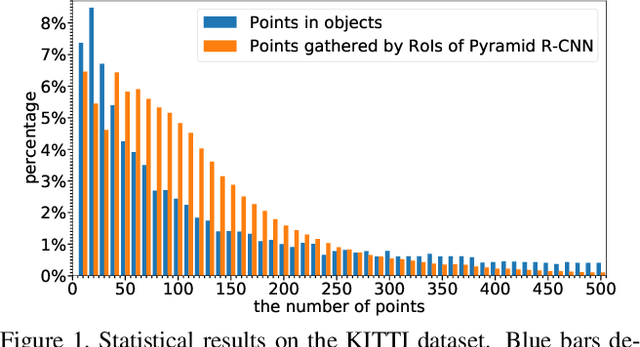
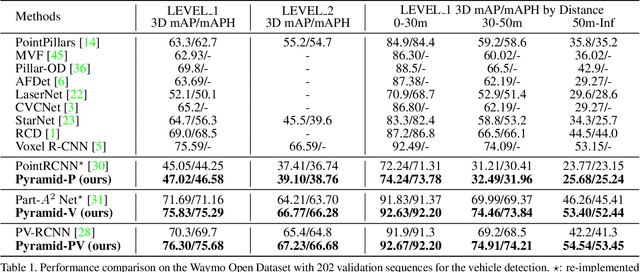
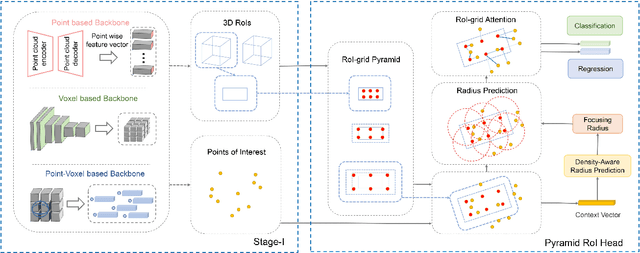

We present a flexible and high-performance framework, named Pyramid R-CNN, for two-stage 3D object detection from point clouds. Current approaches generally rely on the points or voxels of interest for RoI feature extraction on the second stage, but cannot effectively handle the sparsity and non-uniform distribution of those points, and this may result in failures in detecting objects that are far away. To resolve the problems, we propose a novel second-stage module, named pyramid RoI head, to adaptively learn the features from the sparse points of interest. The pyramid RoI head consists of three key components. Firstly, we propose the RoI-grid Pyramid, which mitigates the sparsity problem by extensively collecting points of interest for each RoI in a pyramid manner. Secondly, we propose RoI-grid Attention, a new operation that can encode richer information from sparse points by incorporating conventional attention-based and graph-based point operators into a unified formulation. Thirdly, we propose the Density-Aware Radius Prediction (DARP) module, which can adapt to different point density levels by dynamically adjusting the focusing range of RoIs. Combining the three components, our pyramid RoI head is robust to the sparse and imbalanced circumstances, and can be applied upon various 3D backbones to consistently boost the detection performance. Extensive experiments show that Pyramid R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI dataset and the Waymo Open dataset.
Greedy Network Enlarging
Aug 04, 2021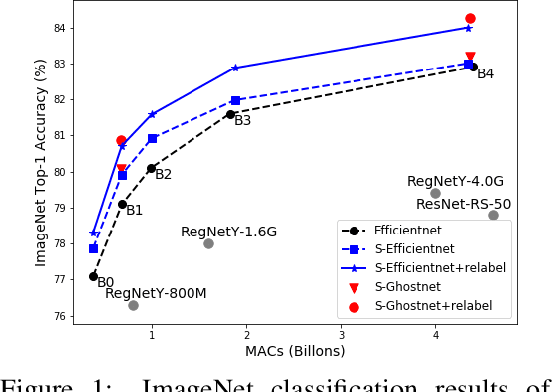
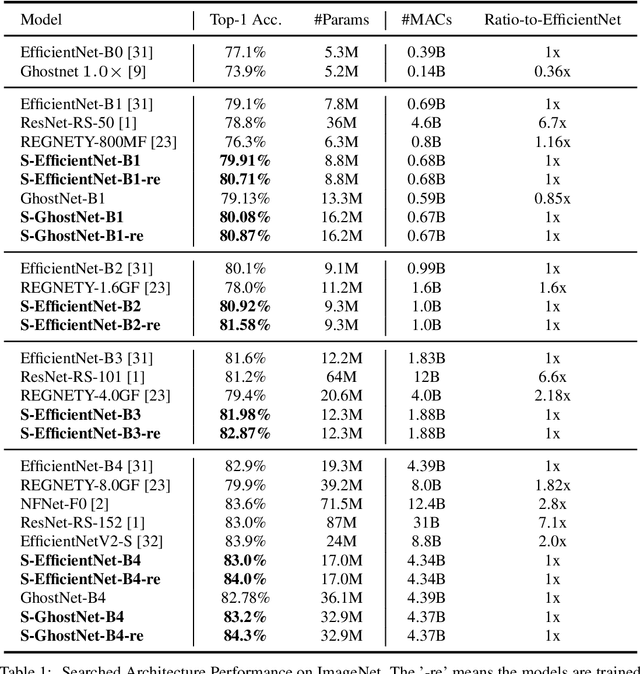
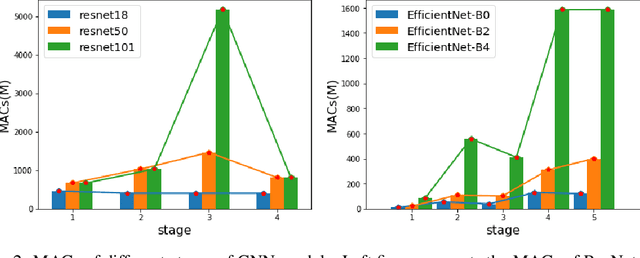
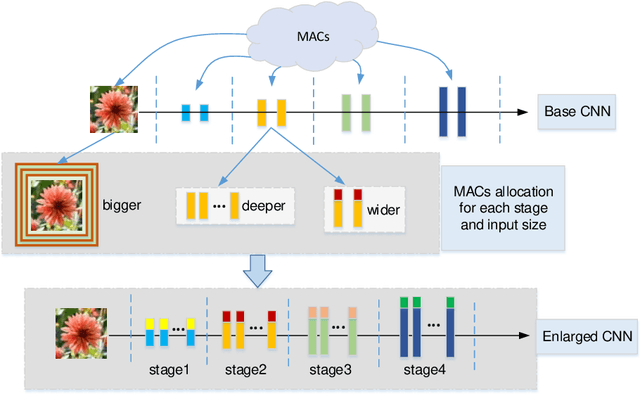
Recent studies on deep convolutional neural networks present a simple paradigm of architecture design, i.e., models with more MACs typically achieve better accuracy, such as EfficientNet and RegNet. These works try to enlarge all the stages in the model with one unified rule by sampling and statistical methods. However, we observe that some network architectures have similar MACs and accuracies, but their allocations on computations for different stages are quite different. In this paper, we propose to enlarge the capacity of CNN models by improving their width, depth and resolution on stage level. Under the assumption that the top-performing smaller CNNs are a proper subcomponent of the top-performing larger CNNs, we propose an greedy network enlarging method based on the reallocation of computations. With step-by-step modifying the computations on different stages, the enlarged network will be equipped with optimal allocation and utilization of MACs. On EfficientNet, our method consistently outperforms the performance of the original scaling method. In particular, with application of our method on GhostNet, we achieve state-of-the-art 80.9% and 84.3% ImageNet top-1 accuracies under the setting of 600M and 4.4B MACs, respectively.
CMT: Convolutional Neural Networks Meet Vision Transformers
Jul 15, 2021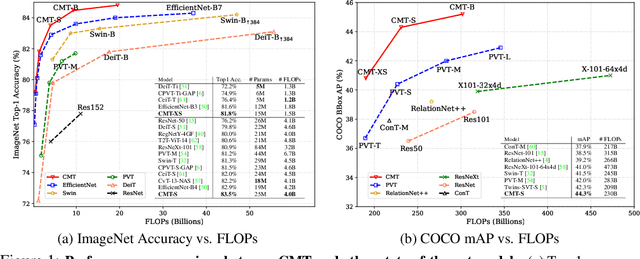
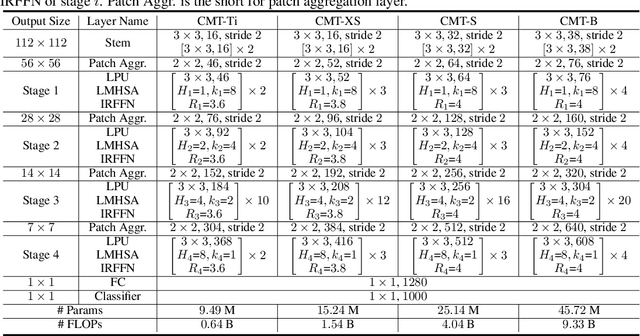
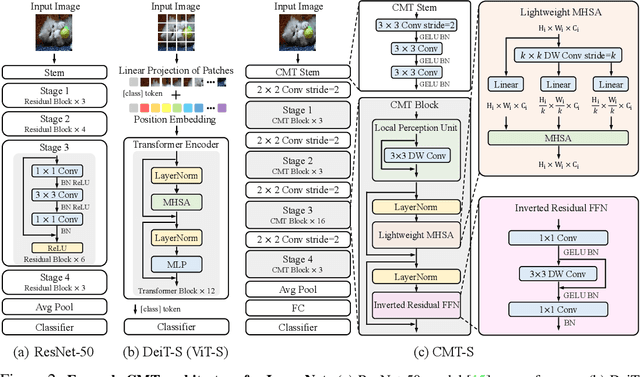
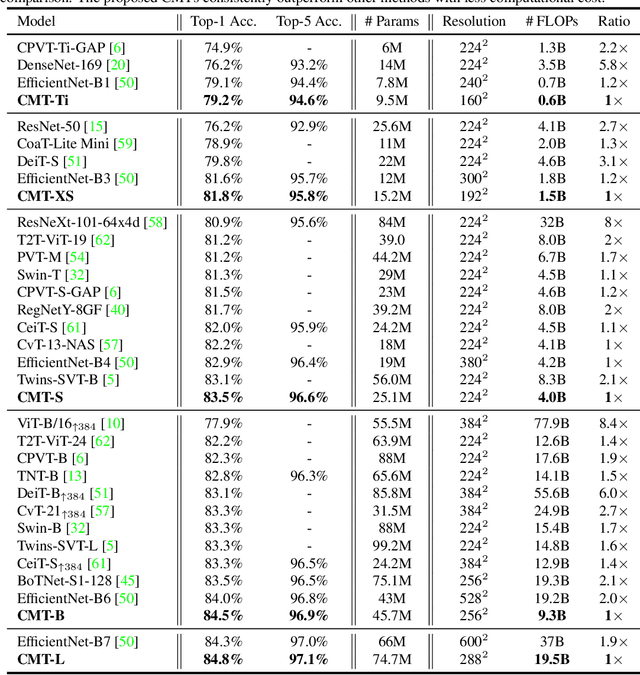
Vision transformers have been successfully applied to image recognition tasks due to their ability to capture long-range dependencies within an image. However, there are still gaps in both performance and computational cost between transformers and existing convolutional neural networks (CNNs). In this paper, we aim to address this issue and develop a network that can outperform not only the canonical transformers, but also the high-performance convolutional models. We propose a new transformer based hybrid network by taking advantage of transformers to capture long-range dependencies, and of CNNs to model local features. Furthermore, we scale it to obtain a family of models, called CMTs, obtaining much better accuracy and efficiency than previous convolution and transformer based models. In particular, our CMT-S achieves 83.5% top-1 accuracy on ImageNet, while being 14x and 2x smaller on FLOPs than the existing DeiT and EfficientNet, respectively. The proposed CMT-S also generalizes well on CIFAR10 (99.2%), CIFAR100 (91.7%), Flowers (98.7%), and other challenging vision datasets such as COCO (44.3% mAP), with considerably less computational cost.
$S^3$: Sign-Sparse-Shift Reparametrization for Effective Training of Low-bit Shift Networks
Jul 07, 2021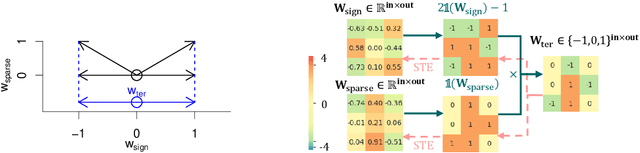



Shift neural networks reduce computation complexity by removing expensive multiplication operations and quantizing continuous weights into low-bit discrete values, which are fast and energy efficient compared to conventional neural networks. However, existing shift networks are sensitive to the weight initialization, and also yield a degraded performance caused by vanishing gradient and weight sign freezing problem. To address these issues, we propose S low-bit re-parameterization, a novel technique for training low-bit shift networks. Our method decomposes a discrete parameter in a sign-sparse-shift 3-fold manner. In this way, it efficiently learns a low-bit network with a weight dynamics similar to full-precision networks and insensitive to weight initialization. Our proposed training method pushes the boundaries of shift neural networks and shows 3-bit shift networks out-performs their full-precision counterparts in terms of top-1 accuracy on ImageNet.
SODA10M: Towards Large-Scale Object Detection Benchmark for Autonomous Driving
Jun 22, 2021

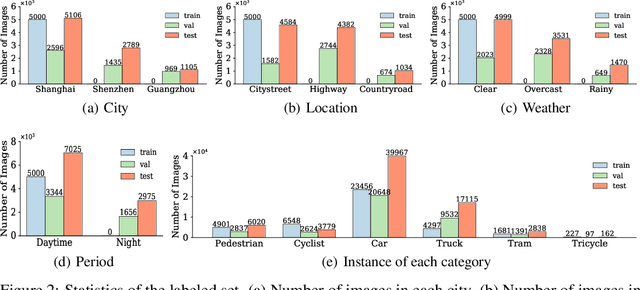
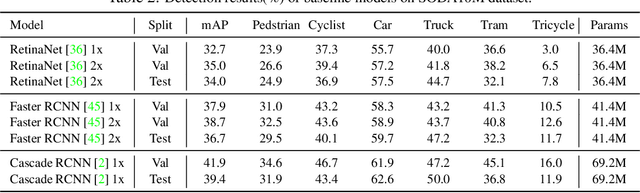
Aiming at facilitating a real-world, ever-evolving and scalable autonomous driving system, we present a large-scale benchmark for standardizing the evaluation of different self-supervised and semi-supervised approaches by learning from raw data, which is the first and largest benchmark to date. Existing autonomous driving systems heavily rely on `perfect' visual perception models (e.g., detection) trained using extensive annotated data to ensure the safety. However, it is unrealistic to elaborately label instances of all scenarios and circumstances (e.g., night, extreme weather, cities) when deploying a robust autonomous driving system. Motivated by recent powerful advances of self-supervised and semi-supervised learning, a promising direction is to learn a robust detection model by collaboratively exploiting large-scale unlabeled data and few labeled data. Existing dataset (e.g., KITTI, Waymo) either provides only a small amount of data or covers limited domains with full annotation, hindering the exploration of large-scale pre-trained models. Here, we release a Large-Scale Object Detection benchmark for Autonomous driving, named as SODA10M, containing 10 million unlabeled images and 20K images labeled with 6 representative object categories. To improve diversity, the images are collected every ten seconds per frame within 32 different cities under different weather conditions, periods and location scenes. We provide extensive experiments and deep analyses of existing supervised state-of-the-art detection models, popular self-supervised and semi-supervised approaches, and some insights about how to develop future models. The data and more up-to-date information have been released at https://soda-2d.github.io.
One Million Scenes for Autonomous Driving: ONCE Dataset
Jun 21, 2021
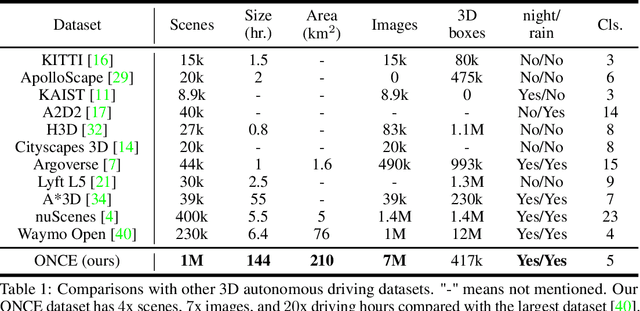
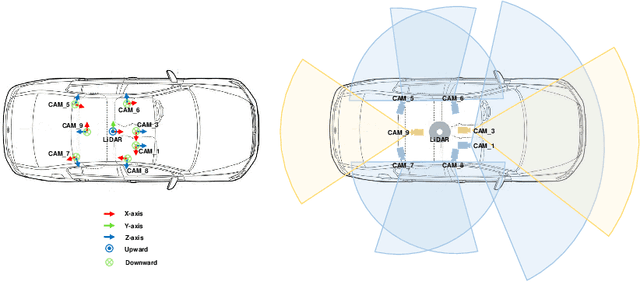

Current perception models in autonomous driving have become notorious for greatly relying on a mass of annotated data to cover unseen cases and address the long-tail problem. On the other hand, learning from unlabeled large-scale collected data and incrementally self-training powerful recognition models have received increasing attention and may become the solutions of next-generation industry-level powerful and robust perception models in autonomous driving. However, the research community generally suffered from data inadequacy of those essential real-world scene data, which hampers the future exploration of fully/semi/self-supervised methods for 3D perception. In this paper, we introduce the ONCE (One millioN sCenEs) dataset for 3D object detection in the autonomous driving scenario. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images. The data is selected from 144 driving hours, which is 20x longer than the largest 3D autonomous driving dataset available (e.g. nuScenes and Waymo), and it is collected across a range of different areas, periods and weather conditions. To facilitate future research on exploiting unlabeled data for 3D detection, we additionally provide a benchmark in which we reproduce and evaluate a variety of self-supervised and semi-supervised methods on the ONCE dataset. We conduct extensive analyses on those methods and provide valuable observations on their performance related to the scale of used data. Data, code, and more information are available at https://once-for-auto-driving.github.io/index.html.
Universal Adder Neural Networks
Jun 10, 2021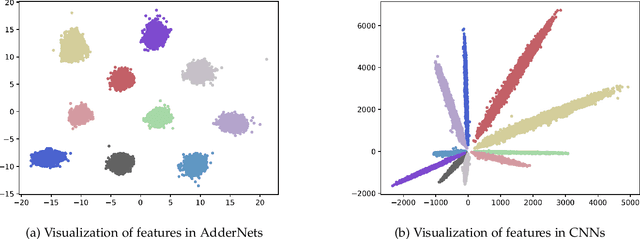

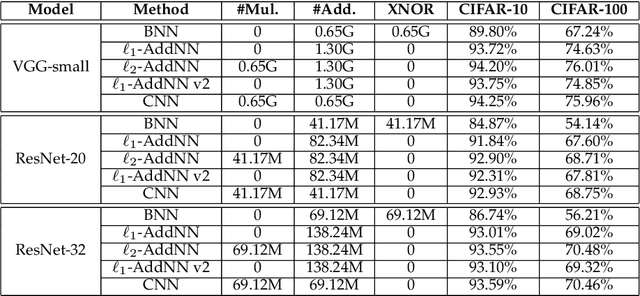

Compared with cheap addition operation, multiplication operation is of much higher computation complexity. The widely-used convolutions in deep neural networks are exactly cross-correlation to measure the similarity between input feature and convolution filters, which involves massive multiplications between float values. In this paper, we present adder networks (AdderNets) to trade these massive multiplications in deep neural networks, especially convolutional neural networks (CNNs), for much cheaper additions to reduce computation costs. In AdderNets, we take the $\ell_1$-norm distance between filters and input feature as the output response. The influence of this new similarity measure on the optimization of neural network have been thoroughly analyzed. To achieve a better performance, we develop a special training approach for AdderNets by investigating the $\ell_p$-norm. We then propose an adaptive learning rate strategy to enhance the training procedure of AdderNets according to the magnitude of each neuron's gradient. As a result, the proposed AdderNets can achieve 75.7% Top-1 accuracy 92.3% Top-5 accuracy using ResNet-50 on the ImageNet dataset without any multiplication in convolutional layer. Moreover, we develop a theoretical foundation for AdderNets, by showing that both the single hidden layer AdderNet and the width-bounded deep AdderNet with ReLU activation functions are universal function approximators. These results match those of the traditional neural networks using the more complex multiplication units. An approximation bound for AdderNets with a single hidden layer is also presented.
Winograd Algorithm for AdderNet
May 12, 2021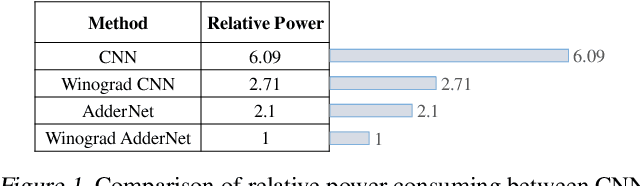
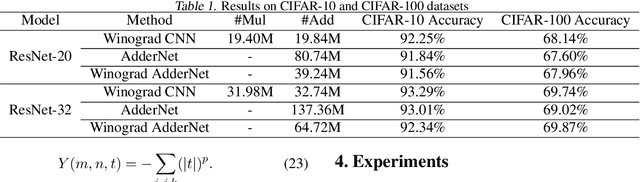
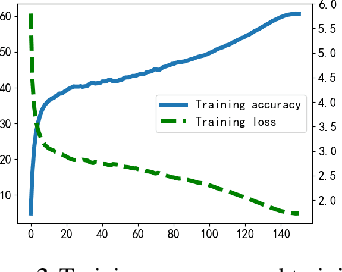
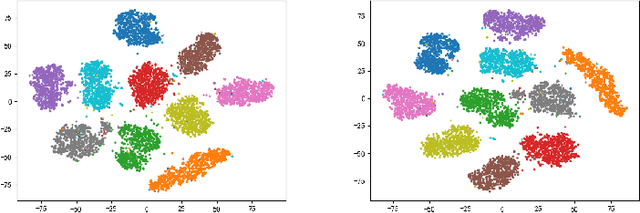
Adder neural network (AdderNet) is a new kind of deep model that replaces the original massive multiplications in convolutions by additions while preserving the high performance. Since the hardware complexity of additions is much lower than that of multiplications, the overall energy consumption is thus reduced significantly. To further optimize the hardware overhead of using AdderNet, this paper studies the winograd algorithm, which is a widely used fast algorithm for accelerating convolution and saving the computational costs. Unfortunately, the conventional Winograd algorithm cannot be directly applied to AdderNets since the distributive law in multiplication is not valid for the l1-norm. Therefore, we replace the element-wise multiplication in the Winograd equation by additions and then develop a new set of transform matrixes that can enhance the representation ability of output features to maintain the performance. Moreover, we propose the l2-to-l1 training strategy to mitigate the negative impacts caused by formal inconsistency. Experimental results on both FPGA and benchmarks show that the new method can further reduce the energy consumption without affecting the accuracy of the original AdderNet.