 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget before Shooting: Accurate Anomaly Detection and Localization under One Millisecond via Cascade Patch Retrieval
Aug 13, 2023



In this work, by re-examining the "matching" nature of Anomaly Detection (AD), we propose a new AD framework that simultaneously enjoys new records of AD accuracy and dramatically high running speed. In this framework, the anomaly detection problem is solved via a cascade patch retrieval procedure that retrieves the nearest neighbors for each test image patch in a coarse-to-fine fashion. Given a test sample, the top-K most similar training images are first selected based on a robust histogram matching process. Secondly, the nearest neighbor of each test patch is retrieved over the similar geometrical locations on those "global nearest neighbors", by using a carefully trained local metric. Finally, the anomaly score of each test image patch is calculated based on the distance to its "local nearest neighbor" and the "non-background" probability. The proposed method is termed "Cascade Patch Retrieval" (CPR) in this work. Different from the conventional patch-matching-based AD algorithms, CPR selects proper "targets" (reference images and locations) before "shooting" (patch-matching). On the well-acknowledged MVTec AD, BTAD and MVTec-3D AD datasets, the proposed algorithm consistently outperforms all the comparing SOTA methods by remarkable margins, measured by various AD metrics. Furthermore, CPR is extremely efficient. It runs at the speed of 113 FPS with the standard setting while its simplified version only requires less than 1 ms to process an image at the cost of a trivial accuracy drop. The code of CPR is available at https://github.com/flyinghu123/CPR.
SegPrompt: Boosting Open-world Segmentation via Category-level Prompt Learning
Aug 12, 2023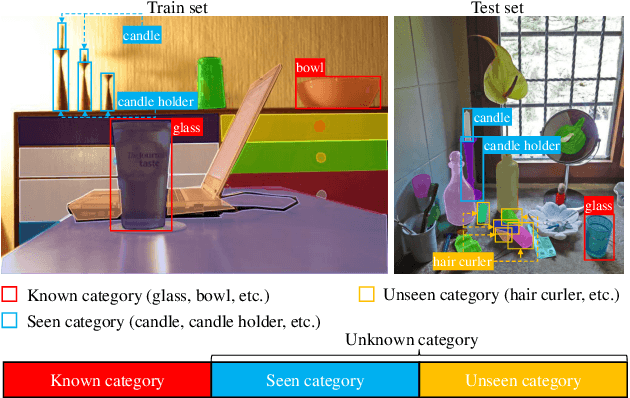

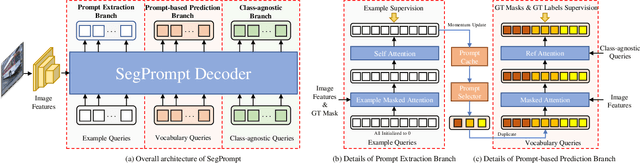

Current closed-set instance segmentation models rely on pre-defined class labels for each mask during training and evaluation, largely limiting their ability to detect novel objects. Open-world instance segmentation (OWIS) models address this challenge by detecting unknown objects in a class-agnostic manner. However, previous OWIS approaches completely erase category information during training to keep the model's ability to generalize to unknown objects. In this work, we propose a novel training mechanism termed SegPrompt that uses category information to improve the model's class-agnostic segmentation ability for both known and unknown categories. In addition, the previous OWIS training setting exposes the unknown classes to the training set and brings information leakage, which is unreasonable in the real world. Therefore, we provide a new open-world benchmark closer to a real-world scenario by dividing the dataset classes into known-seen-unseen parts. For the first time, we focus on the model's ability to discover objects that never appear in the training set images. Experiments show that SegPrompt can improve the overall and unseen detection performance by 5.6% and 6.1% in AR on our new benchmark without affecting the inference efficiency. We further demonstrate the effectiveness of our method on existing cross-dataset transfer and strongly supervised settings, leading to 5.5% and 12.3% relative improvement.
DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
Aug 11, 2023Current deep networks are very data-hungry and benefit from training on largescale datasets, which are often time-consuming to collect and annotate. By contrast, synthetic data can be generated infinitely using generative models such as DALL-E and diffusion models, with minimal effort and cost. In this paper, we present DatasetDM, a generic dataset generation model that can produce diverse synthetic images and the corresponding high-quality perception annotations (e.g., segmentation masks, and depth). Our method builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation. We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module. Training the decoder only needs less than 1% (around 100 images) manually labeled images, enabling the generation of an infinitely large annotated dataset. Then these synthetic data can be used for training various perception models for downstream tasks. To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation. Notably, it achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing). The project website and code can be found at https://weijiawu.github.io/DatasetDM_page/ and https://github.com/showlab/DatasetDM, respectively
FrozenRecon: Pose-free 3D Scene Reconstruction with Frozen Depth Models
Aug 10, 20233D scene reconstruction is a long-standing vision task. Existing approaches can be categorized into geometry-based and learning-based methods. The former leverages multi-view geometry but can face catastrophic failures due to the reliance on accurate pixel correspondence across views. The latter was proffered to mitigate these issues by learning 2D or 3D representation directly. However, without a large-scale video or 3D training data, it can hardly generalize to diverse real-world scenarios due to the presence of tens of millions or even billions of optimization parameters in the deep network. Recently, robust monocular depth estimation models trained with large-scale datasets have been proven to possess weak 3D geometry prior, but they are insufficient for reconstruction due to the unknown camera parameters, the affine-invariant property, and inter-frame inconsistency. Here, we propose a novel test-time optimization approach that can transfer the robustness of affine-invariant depth models such as LeReS to challenging diverse scenes while ensuring inter-frame consistency, with only dozens of parameters to optimize per video frame. Specifically, our approach involves freezing the pre-trained affine-invariant depth model's depth predictions, rectifying them by optimizing the unknown scale-shift values with a geometric consistency alignment module, and employing the resulting scale-consistent depth maps to robustly obtain camera poses and achieve dense scene reconstruction, even in low-texture regions. Experiments show that our method achieves state-of-the-art cross-dataset reconstruction on five zero-shot testing datasets.
CTVIS: Consistent Training for Online Video Instance Segmentation
Jul 24, 2023
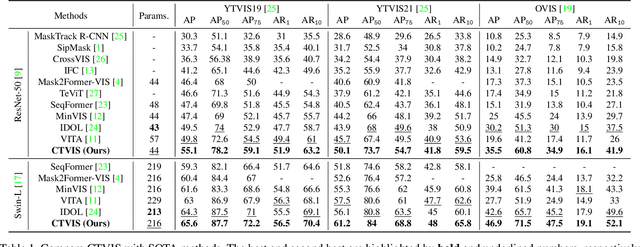
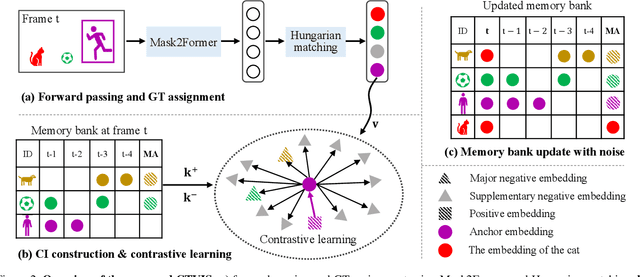
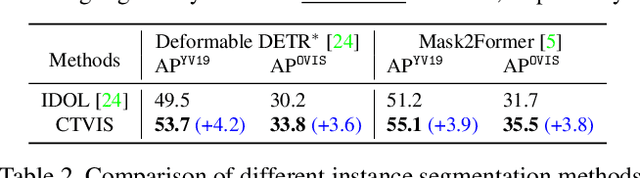
The discrimination of instance embeddings plays a vital role in associating instances across time for online video instance segmentation (VIS). Instance embedding learning is directly supervised by the contrastive loss computed upon the contrastive items (CIs), which are sets of anchor/positive/negative embeddings. Recent online VIS methods leverage CIs sourced from one reference frame only, which we argue is insufficient for learning highly discriminative embeddings. Intuitively, a possible strategy to enhance CIs is replicating the inference phase during training. To this end, we propose a simple yet effective training strategy, called Consistent Training for Online VIS (CTVIS), which devotes to aligning the training and inference pipelines in terms of building CIs. Specifically, CTVIS constructs CIs by referring inference the momentum-averaged embedding and the memory bank storage mechanisms, and adding noise to the relevant embeddings. Such an extension allows a reliable comparison between embeddings of current instances and the stable representations of historical instances, thereby conferring an advantage in modeling VIS challenges such as occlusion, re-identification, and deformation. Empirically, CTVIS outstrips the SOTA VIS models by up to +5.0 points on three VIS benchmarks, including YTVIS19 (55.1% AP), YTVIS21 (50.1% AP) and OVIS (35.5% AP). Furthermore, we find that pseudo-videos transformed from images can train robust models surpassing fully-supervised ones.
Metric3D: Towards Zero-shot Metric 3D Prediction from A Single Image
Jul 20, 2023



Reconstructing accurate 3D scenes from images is a long-standing vision task. Due to the ill-posedness of the single-image reconstruction problem, most well-established methods are built upon multi-view geometry. State-of-the-art (SOTA) monocular metric depth estimation methods can only handle a single camera model and are unable to perform mixed-data training due to the metric ambiguity. Meanwhile, SOTA monocular methods trained on large mixed datasets achieve zero-shot generalization by learning affine-invariant depths, which cannot recover real-world metrics. In this work, we show that the key to a zero-shot single-view metric depth model lies in the combination of large-scale data training and resolving the metric ambiguity from various camera models. We propose a canonical camera space transformation module, which explicitly addresses the ambiguity problems and can be effortlessly plugged into existing monocular models. Equipped with our module, monocular models can be stably trained with over 8 million images with thousands of camera models, resulting in zero-shot generalization to in-the-wild images with unseen camera settings. Experiments demonstrate SOTA performance of our method on 7 zero-shot benchmarks. Notably, our method won the championship in the 2nd Monocular Depth Estimation Challenge. Our method enables the accurate recovery of metric 3D structures on randomly collected internet images, paving the way for plausible single-image metrology. The potential benefits extend to downstream tasks, which can be significantly improved by simply plugging in our model. For example, our model relieves the scale drift issues of monocular-SLAM (Fig. 1), leading to high-quality metric scale dense mapping. The code is available at https://github.com/YvanYin/Metric3D.
Generative Prompt Model for Weakly Supervised Object Localization
Jul 19, 2023Weakly supervised object localization (WSOL) remains challenging when learning object localization models from image category labels. Conventional methods that discriminatively train activation models ignore representative yet less discriminative object parts. In this study, we propose a generative prompt model (GenPromp), defining the first generative pipeline to localize less discriminative object parts by formulating WSOL as a conditional image denoising procedure. During training, GenPromp converts image category labels to learnable prompt embeddings which are fed to a generative model to conditionally recover the input image with noise and learn representative embeddings. During inference, enPromp combines the representative embeddings with discriminative embeddings (queried from an off-the-shelf vision-language model) for both representative and discriminative capacity. The combined embeddings are finally used to generate multi-scale high-quality attention maps, which facilitate localizing full object extent. Experiments on CUB-200-2011 and ILSVRC show that GenPromp respectively outperforms the best discriminative models by 5.2% and 5.6% (Top-1 Loc), setting a solid baseline for WSOL with the generative model. Code is available at https://github.com/callsys/GenPromp.
Learning Conditional Attributes for Compositional Zero-Shot Learning
Jun 14, 2023



Compositional Zero-Shot Learning (CZSL) aims to train models to recognize novel compositional concepts based on learned concepts such as attribute-object combinations. One of the challenges is to model attributes interacted with different objects, e.g., the attribute ``wet" in ``wet apple" and ``wet cat" is different. As a solution, we provide analysis and argue that attributes are conditioned on the recognized object and input image and explore learning conditional attribute embeddings by a proposed attribute learning framework containing an attribute hyper learner and an attribute base learner. By encoding conditional attributes, our model enables to generate flexible attribute embeddings for generalization from seen to unseen compositions. Experiments on CZSL benchmarks, including the more challenging C-GQA dataset, demonstrate better performances compared with other state-of-the-art approaches and validate the importance of learning conditional attributes. Code is available at https://github.com/wqshmzh/CANet-CZSL
SegViTv2: Exploring Efficient and Continual Semantic Segmentation with Plain Vision Transformers
Jun 09, 2023We explore the capability of plain Vision Transformers (ViTs) for semantic segmentation using the encoder-decoder framework and introduce SegViTv2. In our work, we implement the decoder with the global attention mechanism inherent in ViT backbones and propose the lightweight Attention-to-Mask module that effectively converts the global attention map into semantic masks for high-quality segmentation results. Our decoder can outperform the most commonly-used decoder UpperNet in various ViT backbones while consuming only about 5\% of the computational cost. For the encoder, we address the concern of the relatively high computational cost in the ViT-based encoders and propose a Shrunk++ structure that incorporates edge-aware query-based down-sampling (EQD) and query-based up-sampling (QU) modules. The Shrunk++ structure reduces the computational cost of the encoder by up to $50\%$ while maintaining competitive performance. Furthermore, due to the flexibility of our ViT-based architecture, SegVit can be easily extended to semantic segmentation under the setting of continual learning, achieving nearly zero forgetting. Experiments show that our proposed SegViT outperforms recent segmentation methods on three popular benchmarks including ADE20k, COCO-Stuff-10k and PASCAL-Context datasets. The code is available through the following link: \url{https://github.com/zbwxp/SegVit}.
A Dynamic Feature Interaction Framework for Multi-task Visual Perception
Jun 08, 2023Multi-task visual perception has a wide range of applications in scene understanding such as autonomous driving. In this work, we devise an efficient unified framework to solve multiple common perception tasks, including instance segmentation, semantic segmentation, monocular 3D detection, and depth estimation. Simply sharing the same visual feature representations for these tasks impairs the performance of tasks, while independent task-specific feature extractors lead to parameter redundancy and latency. Thus, we design two feature-merge branches to learn feature basis, which can be useful to, and thus shared by, multiple perception tasks. Then, each task takes the corresponding feature basis as the input of the prediction task head to fulfill a specific task. In particular, one feature merge branch is designed for instance-level recognition the other for dense predictions. To enhance inter-branch communication, the instance branch passes pixel-wise spatial information of each instance to the dense branch using efficient dynamic convolution weighting. Moreover, a simple but effective dynamic routing mechanism is proposed to isolate task-specific features and leverage common properties among tasks. Our proposed framework, termed D2BNet, demonstrates a unique approach to parameter-efficient predictions for multi-task perception. In addition, as tasks benefit from co-training with each other, our solution achieves on par results on partially labeled settings on nuScenes and outperforms previous works for 3D detection and depth estimation on the Cityscapes dataset with full supervision.