 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Local Focusing Mechanism for Deepfake Detection Generalization
Aug 23, 2025The rapid advancement of deepfake generation techniques has intensified the need for robust and generalizable detection methods. Existing approaches based on reconstruction learning typically leverage deep convolutional networks to extract differential features. However, these methods show poor generalization across object categories (e.g., from faces to cars) and generation domains (e.g., from GANs to Stable Diffusion), due to intrinsic limitations of deep CNNs. First, models trained on a specific category tend to overfit to semantic feature distributions, making them less transferable to other categories, especially as network depth increases. Second, Global Average Pooling (GAP) compresses critical local forgery cues into a single vector, thus discarding discriminative patterns vital for real-fake classification. To address these issues, we propose a novel Local Focus Mechanism (LFM) that explicitly attends to discriminative local features for differentiating fake from real images. LFM integrates a Salience Network (SNet) with a task-specific Top-K Pooling (TKP) module to select the K most informative local patterns. To mitigate potential overfitting introduced by Top-K pooling, we introduce two regularization techniques: Rank-Based Linear Dropout (RBLD) and Random-K Sampling (RKS), which enhance the model's robustness. LFM achieves a 3.7 improvement in accuracy and a 2.8 increase in average precision over the state-of-the-art Neighboring Pixel Relationships (NPR) method, while maintaining exceptional efficiency at 1789 FPS on a single NVIDIA A6000 GPU. Our approach sets a new benchmark for cross-domain deepfake detection. The source code are available in https://github.com/lmlpy/LFM.git
Towards Efficient Pixel Labeling for Industrial Anomaly Detection and Localization
Jul 03, 2024



In the realm of practical Anomaly Detection (AD) tasks, manual labeling of anomalous pixels proves to be a costly endeavor. Consequently, many AD methods are crafted as one-class classifiers, tailored for training sets completely devoid of anomalies, ensuring a more cost-effective approach. While some pioneering work has demonstrated heightened AD accuracy by incorporating real anomaly samples in training, this enhancement comes at the price of labor-intensive labeling processes. This paper strikes the balance between AD accuracy and labeling expenses by introducing ADClick, a novel Interactive Image Segmentation (IIS) algorithm. ADClick efficiently generates "ground-truth" anomaly masks for real defective images, leveraging innovative residual features and meticulously crafted language prompts. Notably, ADClick showcases a significantly elevated generalization capacity compared to existing state-of-the-art IIS approaches. Functioning as an anomaly labeling tool, ADClick generates high-quality anomaly labels (AP $= 94.1\%$ on MVTec AD) based on only $3$ to $5$ manual click annotations per training image. Furthermore, we extend the capabilities of ADClick into ADClick-Seg, an enhanced model designed for anomaly detection and localization. By fine-tuning the ADClick-Seg model using the weak labels inferred by ADClick, we establish the state-of-the-art performances in supervised AD tasks (AP $= 86.4\%$ on MVTec AD and AP $= 78.4\%$, PRO $= 98.6\%$ on KSDD2).
Seeing Through the Clouds: Cloud Gap Imputation with Prithvi Foundation Model
Apr 30, 2024



Filling cloudy pixels in multispectral satellite imagery is essential for accurate data analysis and downstream applications, especially for tasks which require time series data. To address this issue, we compare the performance of a foundational Vision Transformer (ViT) model with a baseline Conditional Generative Adversarial Network (CGAN) model for missing value imputation in time series of multispectral satellite imagery. We randomly mask time series of satellite images using real-world cloud masks and train each model to reconstruct the missing pixels. The ViT model is fine-tuned from a pretrained model, while the CGAN is trained from scratch. Using quantitative evaluation metrics such as structural similarity index and mean absolute error as well as qualitative visual analysis, we assess imputation accuracy and contextual preservation.
A Novel Approach to Industrial Defect Generation through Blended Latent Diffusion Model with Online Adaptation
Feb 29, 2024



Effectively addressing the challenge of industrial Anomaly Detection (AD) necessitates an ample supply of defective samples, a constraint often hindered by their scarcity in industrial contexts. This paper introduces a novel algorithm designed to augment defective samples, thereby enhancing AD performance. The proposed method tailors the blended latent diffusion model for defect sample generation, employing a diffusion model to generate defective samples in the latent space. A feature editing process, controlled by a "trimap" mask and text prompts, refines the generated samples. The image generation inference process is structured into three stages: a free diffusion stage, an editing diffusion stage, and an online decoder adaptation stage. This sophisticated inference strategy yields high-quality synthetic defective samples with diverse pattern variations, leading to significantly improved AD accuracies based on the augmented training set. Specifically, on the widely recognized MVTec AD dataset, the proposed method elevates the state-of-the-art (SOTA) performance of AD with augmented data by 1.5%, 1.9%, and 3.1% for AD metrics AP, IAP, and IAP90, respectively. The implementation code of this work can be found at the GitHub repository https://github.com/GrandpaXun242/AdaBLDM.git
DART: Depth-Enhanced Accurate and Real-Time Background Matting
Feb 24, 2024



Matting with a static background, often referred to as ``Background Matting" (BGM), has garnered significant attention within the computer vision community due to its pivotal role in various practical applications like webcasting and photo editing. Nevertheless, achieving highly accurate background matting remains a formidable challenge, primarily owing to the limitations inherent in conventional RGB images. These limitations manifest in the form of susceptibility to varying lighting conditions and unforeseen shadows. In this paper, we leverage the rich depth information provided by the RGB-Depth (RGB-D) cameras to enhance background matting performance in real-time, dubbed DART. Firstly, we adapt the original RGB-based BGM algorithm to incorporate depth information. The resulting model's output undergoes refinement through Bayesian inference, incorporating a background depth prior. The posterior prediction is then translated into a "trimap," which is subsequently fed into a state-of-the-art matting algorithm to generate more precise alpha mattes. To ensure real-time matting capabilities, a critical requirement for many real-world applications, we distill the backbone of our model from a larger and more versatile BGM network. Our experiments demonstrate the superior performance of the proposed method. Moreover, thanks to the distillation operation, our method achieves a remarkable processing speed of 33 frames per second (fps) on a mid-range edge-computing device. This high efficiency underscores DART's immense potential for deployment in mobile applications}
Target before Shooting: Accurate Anomaly Detection and Localization under One Millisecond via Cascade Patch Retrieval
Aug 13, 2023



In this work, by re-examining the "matching" nature of Anomaly Detection (AD), we propose a new AD framework that simultaneously enjoys new records of AD accuracy and dramatically high running speed. In this framework, the anomaly detection problem is solved via a cascade patch retrieval procedure that retrieves the nearest neighbors for each test image patch in a coarse-to-fine fashion. Given a test sample, the top-K most similar training images are first selected based on a robust histogram matching process. Secondly, the nearest neighbor of each test patch is retrieved over the similar geometrical locations on those "global nearest neighbors", by using a carefully trained local metric. Finally, the anomaly score of each test image patch is calculated based on the distance to its "local nearest neighbor" and the "non-background" probability. The proposed method is termed "Cascade Patch Retrieval" (CPR) in this work. Different from the conventional patch-matching-based AD algorithms, CPR selects proper "targets" (reference images and locations) before "shooting" (patch-matching). On the well-acknowledged MVTec AD, BTAD and MVTec-3D AD datasets, the proposed algorithm consistently outperforms all the comparing SOTA methods by remarkable margins, measured by various AD metrics. Furthermore, CPR is extremely efficient. It runs at the speed of 113 FPS with the standard setting while its simplified version only requires less than 1 ms to process an image at the cost of a trivial accuracy drop. The code of CPR is available at https://github.com/flyinghu123/CPR.
Efficient Anomaly Detection with Budget Annotation Using Semi-Supervised Residual Transformer
Jun 06, 2023



Anomaly Detection is challenging as usually only the normal samples are seen during training and the detector needs to discover anomalies on-the-fly. The recently proposed deep-learning-based approaches could somehow alleviate the problem but there is still a long way to go in obtaining an industrial-class anomaly detector for real-world applications. On the other hand, in some particular AD tasks, a few anomalous samples are labeled manually for achieving higher accuracy. However, this performance gain is at the cost of considerable annotation efforts, which can be intractable in many practical scenarios. In this work, the above two problems are addressed in a unified framework. Firstly, inspired by the success of the patch-matching-based AD algorithms, we train a sliding vision transformer over the residuals generated by a novel position-constrained patch-matching. Secondly, the conventional pixel-wise segmentation problem is cast into a block-wise classification problem. Thus the sliding transformer can attain even higher accuracy with much less annotation labor. Thirdly, to further reduce the labeling cost, we propose to label the anomalous regions using only bounding boxes. The unlabeled regions caused by the weak labels are effectively exploited using a highly-customized semi-supervised learning scheme equipped with two novel data augmentation methods. The proposed method outperforms all the state-of-the-art approaches using all the evaluation metrics in both the unsupervised and supervised scenarios. On the popular MVTec-AD dataset, our SemiREST algorithm obtains the Average Precision (AP) of 81.2% in the unsupervised condition and 84.4% AP for supervised anomaly detection. Surprisingly, with the bounding-box-based semi-supervisions, SemiREST still outperforms the SOTA methods with full supervision (83.8% AP) on MVTec-AD.
Robust and Real-time Deep Tracking Via Multi-Scale Domain Adaptation
Jan 03, 2017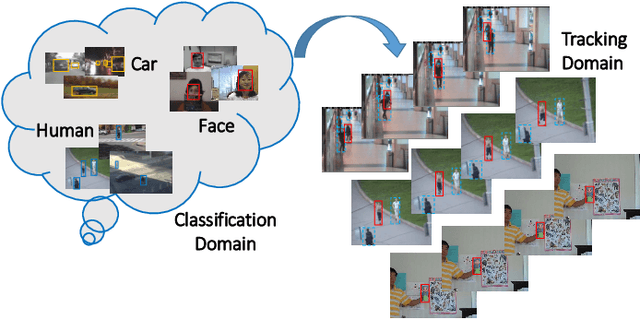

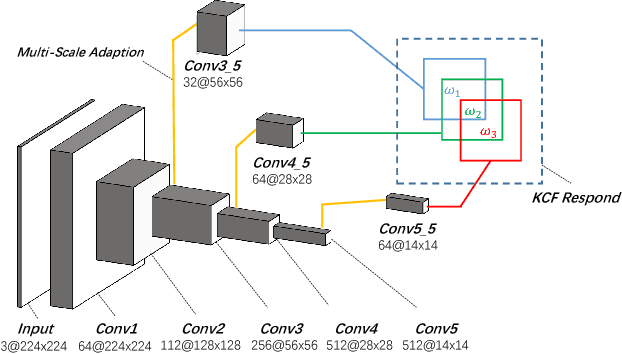
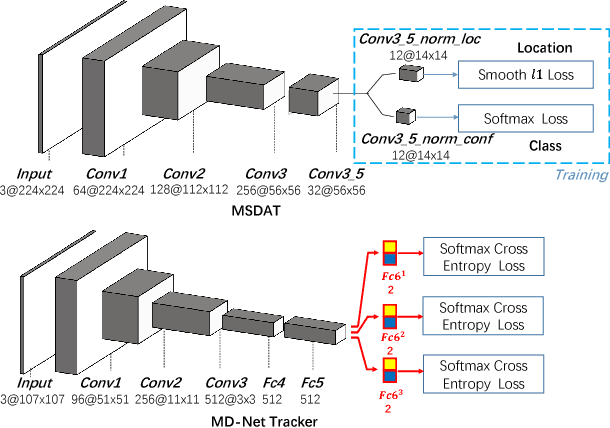
Visual tracking is a fundamental problem in computer vision. Recently, some deep-learning-based tracking algorithms have been achieving record-breaking performances. However, due to the high complexity of deep learning, most deep trackers suffer from low tracking speed, and thus are impractical in many real-world applications. Some new deep trackers with smaller network structure achieve high efficiency while at the cost of significant decrease on precision. In this paper, we propose to transfer the feature for image classification to the visual tracking domain via convolutional channel reductions. The channel reduction could be simply viewed as an additional convolutional layer with the specific task. It not only extracts useful information for object tracking but also significantly increases the tracking speed. To better accommodate the useful feature of the target in different scales, the adaptation filters are designed with different sizes. The yielded visual tracker is real-time and also illustrates the state-of-the-art accuracies in the experiment involving two well-adopted benchmarks with more than 100 test videos.
DeepTrack: Learning Discriminative Feature Representations Online for Robust Visual Tracking
Feb 28, 2015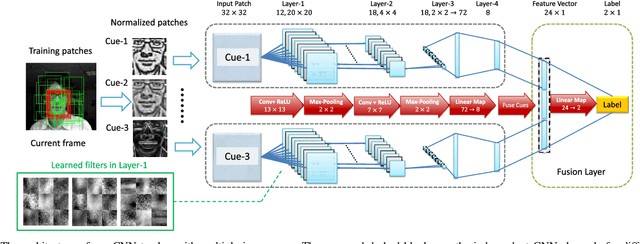
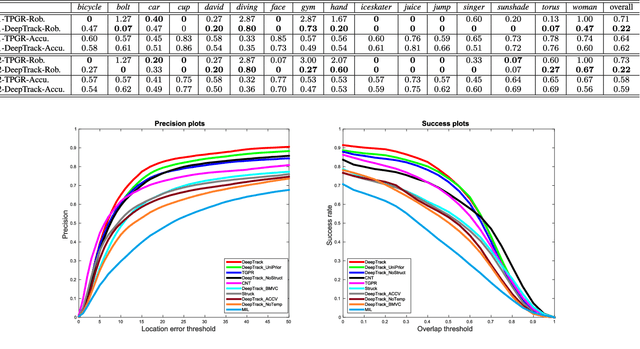
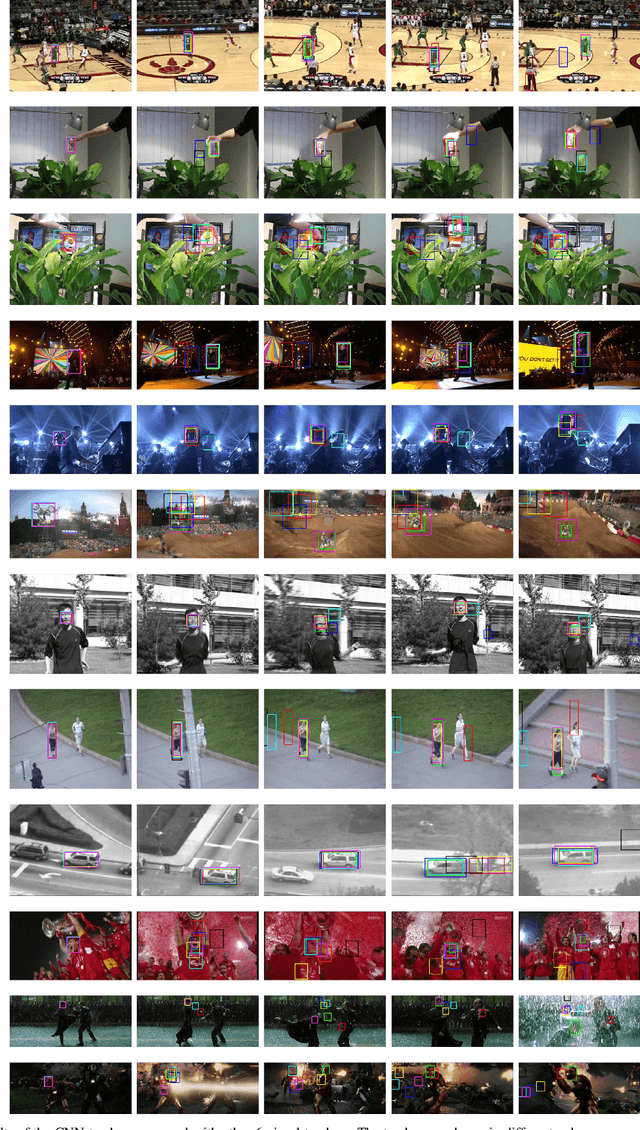

Deep neural networks, albeit their great success on feature learning in various computer vision tasks, are usually considered as impractical for online visual tracking because they require very long training time and a large number of training samples. In this work, we present an efficient and very robust tracking algorithm using a single Convolutional Neural Network (CNN) for learning effective feature representations of the target object, in a purely online manner. Our contributions are multifold: First, we introduce a novel truncated structural loss function that maintains as many training samples as possible and reduces the risk of tracking error accumulation. Second, we enhance the ordinary Stochastic Gradient Descent approach in CNN training with a robust sample selection mechanism. The sampling mechanism randomly generates positive and negative samples from different temporal distributions, which are generated by taking the temporal relations and label noise into account. Finally, a lazy yet effective updating scheme is designed for CNN training. Equipped with this novel updating algorithm, the CNN model is robust to some long-existing difficulties in visual tracking such as occlusion or incorrect detections, without loss of the effective adaption for significant appearance changes. In the experiment, our CNN tracker outperforms all compared state-of-the-art methods on two recently proposed benchmarks which in total involve over 60 video sequences. The remarkable performance improvement over the existing trackers illustrates the superiority of the feature representations which are learned
Totally Corrective Boosting for Regularized Risk Minimization
Dec 12, 2011Consideration of the primal and dual problems together leads to important new insights into the characteristics of boosting algorithms. In this work, we propose a general framework that can be used to design new boosting algorithms. A wide variety of machine learning problems essentially minimize a regularized risk functional. We show that the proposed boosting framework, termed CGBoost, can accommodate various loss functions and different regularizers in a totally-corrective optimization fashion. We show that, by solving the primal rather than the dual, a large body of totally-corrective boosting algorithms can actually be efficiently solved and no sophisticated convex optimization solvers are needed. We also demonstrate that some boosting algorithms like AdaBoost can be interpreted in our framework--even their optimization is not totally corrective. We empirically show that various boosting algorithms based on the proposed framework perform similarly on the UCIrvine machine learning datasets [1] that we have used in the experiments.