 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparkle: Realizing Lively Instruction-Guided Video Background Replacement via Decoupled Guidance
May 07, 2026In recent years, open-source efforts like Senorita-2M have propelled video editing toward natural language instruction. However, current publicly available datasets predominantly focus on local editing or style transfer, which largely preserve the original scene structure and are easier to scale. In contrast, Background Replacement, a task central to creative applications such as film production and advertising, requires synthesizing entirely new, temporally consistent scenes while maintaining accurate foreground-background interactions, making large-scale data generation significantly more challenging. Consequently, this complex task remains largely underexplored due to a scarcity of high-quality training data. This gap is evident in poorly performing state-of-the-art models, e.g., Kiwi-Edit, because the primary open-source dataset that contains this task, i.e., OpenVE-3M, frequently produces static, unnatural backgrounds. In this paper, we trace this quality degradation to a lack of precise background guidance during data synthesis. Accordingly, we design a scalable pipeline that generates foreground and background guidance in a decoupled manner with strict quality filtering. Building on this pipeline, we introduce Sparkle, a dataset of ~140K video pairs spanning five common background-change themes, alongside Sparkle-Bench, the largest evaluation benchmark tailored for background replacement to date. Experiments demonstrate that our dataset and the model trained on it achieve substantially better performance than all existing baselines on both OpenVE-Bench and Sparkle-Bench. Our proposed dataset, benchmark, and model are fully open-sourced at https://showlab.github.io/Sparkle/.
Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
Mar 05, 2026Instruction-based video editing has witnessed rapid progress, yet current methods often struggle with precise visual control, as natural language is inherently limited in describing complex visual nuances. Although reference-guided editing offers a robust solution, its potential is currently bottlenecked by the scarcity of high-quality paired training data. To bridge this gap, we introduce a scalable data generation pipeline that transforms existing video editing pairs into high-fidelity training quadruplets, leveraging image generative models to create synthesized reference scaffolds. Using this pipeline, we construct RefVIE, a large-scale dataset tailored for instruction-reference-following tasks, and establish RefVIE-Bench for comprehensive evaluation. Furthermore, we propose a unified editing architecture, Kiwi-Edit, that synergizes learnable queries and latent visual features for reference semantic guidance. Our model achieves significant gains in instruction following and reference fidelity via a progressive multi-stage training curriculum. Extensive experiments demonstrate that our data and architecture establish a new state-of-the-art in controllable video editing. All datasets, models, and code is released at https://github.com/showlab/Kiwi-Edit.
Attention Retention for Continual Learning with Vision Transformers
Feb 05, 2026Continual learning (CL) empowers AI systems to progressively acquire knowledge from non-stationary data streams. However, catastrophic forgetting remains a critical challenge. In this work, we identify attention drift in Vision Transformers as a primary source of catastrophic forgetting, where the attention to previously learned visual concepts shifts significantly after learning new tasks. Inspired by neuroscientific insights into the selective attention in the human visual system, we propose a novel attention-retaining framework to mitigate forgetting in CL. Our method constrains attention drift by explicitly modifying gradients during backpropagation through a two-step process: 1) extracting attention maps of the previous task using a layer-wise rollout mechanism and generating instance-adaptive binary masks, and 2) when learning a new task, applying these masks to zero out gradients associated with previous attention regions, thereby preventing disruption of learned visual concepts. For compatibility with modern optimizers, the gradient masking process is further enhanced by scaling parameter updates proportionally to maintain their relative magnitudes. Experiments and visualizations demonstrate the effectiveness of our method in mitigating catastrophic forgetting and preserving visual concepts. It achieves state-of-the-art performance and exhibits robust generalizability across diverse CL scenarios.
Zoom-IQA: Image Quality Assessment with Reliable Region-Aware Reasoning
Jan 06, 2026Image Quality Assessment (IQA) is a long-standing problem in computer vision. Previous methods typically focus on predicting numerical scores without explanation or provide low-level descriptions lacking precise scores. Recent reasoning-based vision language models (VLMs) have shown strong potential for IQA, enabling joint generation of quality descriptions and scores. However, we notice that existing VLM-based IQA methods tend to exhibit unreliable reasoning due to their limited capability of integrating visual and textual cues. In this work, we introduce Zoom-IQA, a VLM-based IQA model to explicitly emulate key cognitive behaviors: uncertainty awareness, region reasoning, and iterative refinement. Specifically, we present a two-stage training pipeline: 1) supervised fine-tuning (SFT) on our Grounded-Rationale-IQA (GR-IQA) dataset to teach the model to ground its assessments in key regions; and 2) reinforcement learning (RL) for dynamic policy exploration, primarily stabilized by our KL-Coverage regularizer to prevent reasoning and scoring diversity collapse, and supported by a Progressive Re-sampling Strategy to mitigate annotation bias. Extensive experiments show that Zoom-IQA achieves improved robustness, explainability, and generalization. The application to downstream tasks, such as image restoration, further demonstrates the effectiveness of Zoom-IQA.
The Empowerment of Science of Science by Large Language Models: New Tools and Methods
Nov 19, 2025Large language models (LLMs) have exhibited exceptional capabilities in natural language understanding and generation, image recognition, and multimodal tasks, charting a course towards AGI and emerging as a central issue in the global technological race. This manuscript conducts a comprehensive review of the core technologies that support LLMs from a user standpoint, including prompt engineering, knowledge-enhanced retrieval augmented generation, fine tuning, pretraining, and tool learning. Additionally, it traces the historical development of Science of Science (SciSci) and presents a forward looking perspective on the potential applications of LLMs within the scientometric domain. Furthermore, it discusses the prospect of an AI agent based model for scientific evaluation, and presents new research fronts detection and knowledge graph building methods with LLMs.
Multi-level Collaborative Distillation Meets Global Workspace Model: A Unified Framework for OCIL
Aug 12, 2025Online Class-Incremental Learning (OCIL) enables models to learn continuously from non-i.i.d. data streams and samples of the data streams can be seen only once, making it more suitable for real-world scenarios compared to offline learning. However, OCIL faces two key challenges: maintaining model stability under strict memory constraints and ensuring adaptability to new tasks. Under stricter memory constraints, current replay-based methods are less effective. While ensemble methods improve adaptability (plasticity), they often struggle with stability. To overcome these challenges, we propose a novel approach that enhances ensemble learning through a Global Workspace Model (GWM)-a shared, implicit memory that guides the learning of multiple student models. The GWM is formed by fusing the parameters of all students within each training batch, capturing the historical learning trajectory and serving as a dynamic anchor for knowledge consolidation. This fused model is then redistributed periodically to the students to stabilize learning and promote cross-task consistency. In addition, we introduce a multi-level collaborative distillation mechanism. This approach enforces peer-to-peer consistency among students and preserves historical knowledge by aligning each student with the GWM. As a result, student models remain adaptable to new tasks while maintaining previously learned knowledge, striking a better balance between stability and plasticity. Extensive experiments on three standard OCIL benchmarks show that our method delivers significant performance improvement for several OCIL models across various memory budgets.
AuthFace: Towards Authentic Blind Face Restoration with Face-oriented Generative Diffusion Prior
Oct 13, 2024



Blind face restoration (BFR) is a fundamental and challenging problem in computer vision. To faithfully restore high-quality (HQ) photos from poor-quality ones, recent research endeavors predominantly rely on facial image priors from the powerful pretrained text-to-image (T2I) diffusion models. However, such priors often lead to the incorrect generation of non-facial features and insufficient facial details, thus rendering them less practical for real-world applications. In this paper, we propose a novel framework, namely AuthFace that achieves highly authentic face restoration results by exploring a face-oriented generative diffusion prior. To learn such a prior, we first collect a dataset of 1.5K high-quality images, with resolutions exceeding 8K, captured by professional photographers. Based on the dataset, we then introduce a novel face-oriented restoration-tuning pipeline that fine-tunes a pretrained T2I model. Identifying key criteria of quality-first and photography-guided annotation, we involve the retouching and reviewing process under the guidance of photographers for high-quality images that show rich facial features. The photography-guided annotation system fully explores the potential of these high-quality photographic images. In this way, the potent natural image priors from pretrained T2I diffusion models can be subtly harnessed, specifically enhancing their capability in facial detail restoration. Moreover, to minimize artifacts in critical facial areas, such as eyes and mouth, we propose a time-aware latent facial feature loss to learn the authentic face restoration process. Extensive experiments on the synthetic and real-world BFR datasets demonstrate the superiority of our approach.
EvLight++: Low-Light Video Enhancement with an Event Camera: A Large-Scale Real-World Dataset, Novel Method, and More
Aug 29, 2024



Event cameras offer significant advantages for low-light video enhancement, primarily due to their high dynamic range. Current research, however, is severely limited by the absence of large-scale, real-world, and spatio-temporally aligned event-video datasets. To address this, we introduce a large-scale dataset with over 30,000 pairs of frames and events captured under varying illumination. This dataset was curated using a robotic arm that traces a consistent non-linear trajectory, achieving spatial alignment precision under 0.03mm and temporal alignment with errors under 0.01s for 90% of the dataset. Based on the dataset, we propose \textbf{EvLight++}, a novel event-guided low-light video enhancement approach designed for robust performance in real-world scenarios. Firstly, we design a multi-scale holistic fusion branch to integrate structural and textural information from both images and events. To counteract variations in regional illumination and noise, we introduce Signal-to-Noise Ratio (SNR)-guided regional feature selection, enhancing features from high SNR regions and augmenting those from low SNR regions by extracting structural information from events. To incorporate temporal information and ensure temporal coherence, we further introduce a recurrent module and temporal loss in the whole pipeline. Extensive experiments on our and the synthetic SDSD dataset demonstrate that EvLight++ significantly outperforms both single image- and video-based methods by 1.37 dB and 3.71 dB, respectively. To further explore its potential in downstream tasks like semantic segmentation and monocular depth estimation, we extend our datasets by adding pseudo segmentation and depth labels via meticulous annotation efforts with foundation models. Experiments under diverse low-light scenes show that the enhanced results achieve a 15.97% improvement in mIoU for semantic segmentation.
Towards Robust Event-guided Low-Light Image Enhancement: A Large-Scale Real-World Event-Image Dataset and Novel Approach
Apr 01, 2024Event camera has recently received much attention for low-light image enhancement (LIE) thanks to their distinct advantages, such as high dynamic range. However, current research is prohibitively restricted by the lack of large-scale, real-world, and spatial-temporally aligned event-image datasets. To this end, we propose a real-world (indoor and outdoor) dataset comprising over 30K pairs of images and events under both low and normal illumination conditions. To achieve this, we utilize a robotic arm that traces a consistent non-linear trajectory to curate the dataset with spatial alignment precision under 0.03mm. We then introduce a matching alignment strategy, rendering 90% of our dataset with errors less than 0.01s. Based on the dataset, we propose a novel event-guided LIE approach, called EvLight, towards robust performance in real-world low-light scenes. Specifically, we first design the multi-scale holistic fusion branch to extract holistic structural and textural information from both events and images. To ensure robustness against variations in the regional illumination and noise, we then introduce a Signal-to-Noise-Ratio (SNR)-guided regional feature selection to selectively fuse features of images from regions with high SNR and enhance those with low SNR by extracting regional structure information from events. Extensive experiments on our dataset and the synthetic SDSD dataset demonstrate our EvLight significantly surpasses the frame-based methods. Code and datasets are available at https://vlislab22.github.io/eg-lowlight/.
CoLeCLIP: Open-Domain Continual Learning via Joint Task Prompt and Vocabulary Learning
Mar 15, 2024
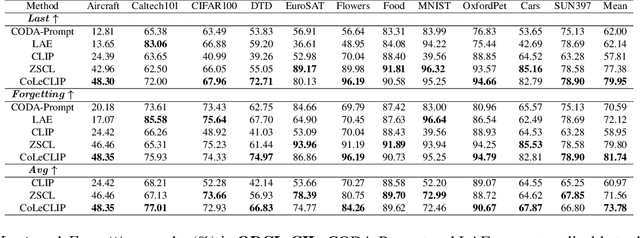


This paper explores the problem of continual learning (CL) of vision-language models (VLMs) in open domains, where the models need to perform continual updating and inference on a streaming of datasets from diverse seen and unseen domains with novel classes. Such a capability is crucial for various applications in open environments, e.g., AI assistants, autonomous driving systems, and robotics. Current CL studies mostly focus on closed-set scenarios in a single domain with known classes. Large pre-trained VLMs like CLIP have demonstrated superior zero-shot recognition ability, and a number of recent studies leverage this ability to mitigate catastrophic forgetting in CL, but they focus on closed-set CL in a single domain dataset. Open-domain CL of large VLMs is significantly more challenging due to 1) large class correlations and domain gaps across the datasets and 2) the forgetting of zero-shot knowledge in the pre-trained VLMs in addition to the knowledge learned from the newly adapted datasets. In this work we introduce a novel approach, termed CoLeCLIP, that learns an open-domain CL model based on CLIP. It addresses these challenges by a joint learning of a set of task prompts and a cross-domain class vocabulary. Extensive experiments on 11 domain datasets show that CoLeCLIP outperforms state-of-the-art methods for open-domain CL under both task- and class-incremental learning settings.