 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View UAV Geo-Localization with Precision-Focused Efficient Design: A Hierarchical Distillation Approach with Multi-view Refinement
Oct 26, 2025Cross-view geo-localization (CVGL) enables UAV localization by matching aerial images to geo-tagged satellite databases, which is critical for autonomous navigation in GNSS-denied environments. However, existing methods rely on resource-intensive fine-grained feature extraction and alignment, where multiple branches and modules significantly increase inference costs, limiting their deployment on edge devices. We propose Precision-Focused Efficient Design (PFED), a resource-efficient framework combining hierarchical knowledge transfer and multi-view representation refinement. This innovative method comprises two key components: 1) During training, Hierarchical Distillation paradigm for fast and accurate CVGL (HD-CVGL), coupled with Uncertainty-Aware Prediction Alignment (UAPA) to distill essential information and mitigate the data imbalance without incurring additional inference overhead. 2) During inference, an efficient Multi-view Refinement Module (MRM) leverages mutual information to filter redundant samples and effectively utilize the multi-view data. Extensive experiments show that PFED achieves state-of-the-art performance in both accuracy and efficiency, reaching 97.15\% Recall@1 on University-1652 while being over $5 \times$ more efficient in FLOPs and $3 \times$ faster than previous top methods. Furthermore, PFED runs at 251.5 FPS on the AGX Orin edge device, demonstrating its practical viability for real-time UAV applications. The project is available at https://github.com/SkyEyeLoc/PFED
Aixel: A Unified, Adaptive and Extensible System for AI-powered Data Analysis
Oct 14, 2025A growing trend in modern data analysis is the integration of data management with learning, guided by accuracy, latency, and cost requirements. In practice, applications draw data of different formats from many sources. In the meanwhile, the objectives and budgets change over time. Existing systems handle these applications across databases, analysis libraries, and tuning services. Such fragmentation leads to complex user interaction, limited adaptability, suboptimal performance, and poor extensibility across components. To address these challenges, we present Aixel, a unified, adaptive, and extensible system for AI-powered data analysis. The system organizes work across four layers: application, task, model, and data. The task layer provides a declarative interface to capture user intent, which is parsed into an executable operator plan. An optimizer compiles and schedules this plan to meet specified goals in accuracy, latency, and cost. The task layer coordinates the execution of data and model operators, with built-in support for reuse and caching to improve efficiency. The model layer offers versioned storage for index, metadata, tensors, and model artifacts. It supports adaptive construction, task-aligned drift detection, and safe updates that reuse shared components. The data layer provides unified data management capabilities, including indexing, constraint-aware discovery, task-aligned selection, and comprehensive feature management. With the above designed layers, Aixel delivers a user friendly, adaptive, efficient, and extensible system.
Laminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
Towards Reliable LLM-based Robot Planning via Combined Uncertainty Estimation
Oct 09, 2025



Large language models (LLMs) demonstrate advanced reasoning abilities, enabling robots to understand natural language instructions and generate high-level plans with appropriate grounding. However, LLM hallucinations present a significant challenge, often leading to overconfident yet potentially misaligned or unsafe plans. While researchers have explored uncertainty estimation to improve the reliability of LLM-based planning, existing studies have not sufficiently differentiated between epistemic and intrinsic uncertainty, limiting the effectiveness of uncertainty esti- mation. In this paper, we present Combined Uncertainty estimation for Reliable Embodied planning (CURE), which decomposes the uncertainty into epistemic and intrinsic uncertainty, each estimated separately. Furthermore, epistemic uncertainty is subdivided into task clarity and task familiarity for more accurate evaluation. The overall uncertainty assessments are obtained using random network distillation and multi-layer perceptron regression heads driven by LLM features. We validated our approach in two distinct experimental settings: kitchen manipulation and tabletop rearrangement experiments. The results show that, compared to existing methods, our approach yields uncertainty estimates that are more closely aligned with the actual execution outcomes.
Empowering Denoising Sequential Recommendation with Large Language Model Embeddings
Oct 05, 2025Sequential recommendation aims to capture user preferences by modeling sequential patterns in user-item interactions. However, these models are often influenced by noise such as accidental interactions, leading to suboptimal performance. Therefore, to reduce the effect of noise, some works propose explicitly identifying and removing noisy items. However, we find that simply relying on collaborative information may result in an over-denoising problem, especially for cold items. To overcome these limitations, we propose a novel framework: Interest Alignment for Denoising Sequential Recommendation (IADSR) which integrates both collaborative and semantic information. Specifically, IADSR is comprised of two stages: in the first stage, we obtain the collaborative and semantic embeddings of each item from a traditional sequential recommendation model and an LLM, respectively. In the second stage, we align the collaborative and semantic embeddings and then identify noise in the interaction sequence based on long-term and short-term interests captured in the collaborative and semantic modalities. Our extensive experiments on four public datasets validate the effectiveness of the proposed framework and its compatibility with different sequential recommendation systems.
WorldForge: Unlocking Emergent 3D/4D Generation in Video Diffusion Model via Training-Free Guidance
Sep 18, 2025



Recent video diffusion models demonstrate strong potential in spatial intelligence tasks due to their rich latent world priors. However, this potential is hindered by their limited controllability and geometric inconsistency, creating a gap between their strong priors and their practical use in 3D/4D tasks. As a result, current approaches often rely on retraining or fine-tuning, which risks degrading pretrained knowledge and incurs high computational costs. To address this, we propose WorldForge, a training-free, inference-time framework composed of three tightly coupled modules. Intra-Step Recursive Refinement introduces a recursive refinement mechanism during inference, which repeatedly optimizes network predictions within each denoising step to enable precise trajectory injection. Flow-Gated Latent Fusion leverages optical flow similarity to decouple motion from appearance in the latent space and selectively inject trajectory guidance into motion-related channels. Dual-Path Self-Corrective Guidance compares guided and unguided denoising paths to adaptively correct trajectory drift caused by noisy or misaligned structural signals. Together, these components inject fine-grained, trajectory-aligned guidance without training, achieving both accurate motion control and photorealistic content generation. Extensive experiments across diverse benchmarks validate our method's superiority in realism, trajectory consistency, and visual fidelity. This work introduces a novel plug-and-play paradigm for controllable video synthesis, offering a new perspective on leveraging generative priors for spatial intelligence.
EVDI++: Event-based Video Deblurring and Interpolation via Self-Supervised Learning
Sep 10, 2025



Frame-based cameras with extended exposure times often produce perceptible visual blurring and information loss between frames, significantly degrading video quality. To address this challenge, we introduce EVDI++, a unified self-supervised framework for Event-based Video Deblurring and Interpolation that leverages the high temporal resolution of event cameras to mitigate motion blur and enable intermediate frame prediction. Specifically, the Learnable Double Integral (LDI) network is designed to estimate the mapping relation between reference frames and sharp latent images. Then, we refine the coarse results and optimize overall training efficiency by introducing a learning-based division reconstruction module, enabling images to be converted with varying exposure intervals. We devise an adaptive parameter-free fusion strategy to obtain the final results, utilizing the confidence embedded in the LDI outputs of concurrent events. A self-supervised learning framework is proposed to enable network training with real-world blurry videos and events by exploring the mutual constraints among blurry frames, latent images, and event streams. We further construct a dataset with real-world blurry images and events using a DAVIS346c camera, demonstrating the generalizability of the proposed EVDI++ in real-world scenarios. Extensive experiments on both synthetic and real-world datasets show that our method achieves state-of-the-art performance in video deblurring and interpolation tasks.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
GraphMMP: A Graph Neural Network Model with Mutual Information and Global Fusion for Multimodal Medical Prognosis
Aug 24, 2025In the field of multimodal medical data analysis, leveraging diverse types of data and understanding their hidden relationships continues to be a research focus. The main challenges lie in effectively modeling the complex interactions between heterogeneous data modalities with distinct characteristics while capturing both local and global dependencies across modalities. To address these challenges, this paper presents a two-stage multimodal prognosis model, GraphMMP, which is based on graph neural networks. The proposed model constructs feature graphs using mutual information and features a global fusion module built on Mamba, which significantly boosts prognosis performance. Empirical results show that GraphMMP surpasses existing methods on datasets related to liver prognosis and the METABRIC study, demonstrating its effectiveness in multimodal medical prognosis tasks.
ERF-BA-TFD+: A Multimodal Model for Audio-Visual Deepfake Detection
Aug 24, 2025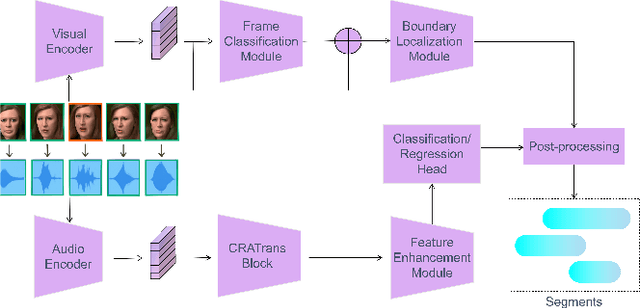
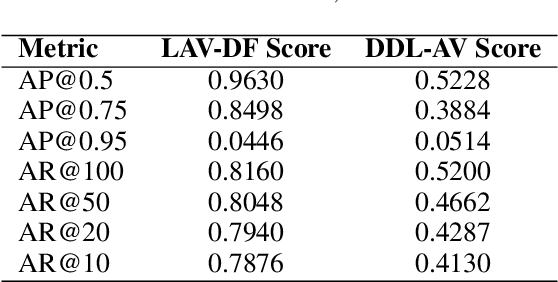
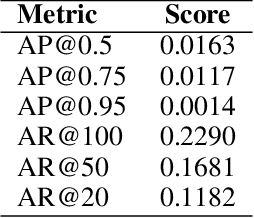
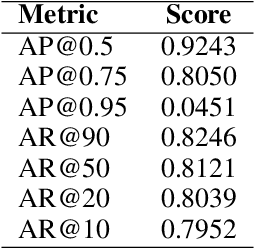
Deepfake detection is a critical task in identifying manipulated multimedia content. In real-world scenarios, deepfake content can manifest across multiple modalities, including audio and video. To address this challenge, we present ERF-BA-TFD+, a novel multimodal deepfake detection model that combines enhanced receptive field (ERF) and audio-visual fusion. Our model processes both audio and video features simultaneously, leveraging their complementary information to improve detection accuracy and robustness. The key innovation of ERF-BA-TFD+ lies in its ability to model long-range dependencies within the audio-visual input, allowing it to better capture subtle discrepancies between real and fake content. In our experiments, we evaluate ERF-BA-TFD+ on the DDL-AV dataset, which consists of both segmented and full-length video clips. Unlike previous benchmarks, which focused primarily on isolated segments, the DDL-AV dataset allows us to assess the model's performance in a more comprehensive and realistic setting. Our method achieves state-of-the-art results on this dataset, outperforming existing techniques in terms of both accuracy and processing speed. The ERF-BA-TFD+ model demonstrated its effectiveness in the "Workshop on Deepfake Detection, Localization, and Interpretability," Track 2: Audio-Visual Detection and Localization (DDL-AV), and won first place in this competition.