 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Matching based Sequential Recommender Model
May 22, 2025Generative models, particularly diffusion model, have emerged as powerful tools for sequential recommendation. However, accurately modeling user preferences remains challenging due to the noise perturbations inherent in the forward and reverse processes of diffusion-based methods. Towards this end, this study introduces FMRec, a Flow Matching based model that employs a straight flow trajectory and a modified loss tailored for the recommendation task. Additionally, from the diffusion-model perspective, we integrate a reconstruction loss to improve robustness against noise perturbations, thereby retaining user preferences during the forward process. In the reverse process, we employ a deterministic reverse sampler, specifically an ODE-based updating function, to eliminate unnecessary randomness, thereby ensuring that the generated recommendations closely align with user needs. Extensive evaluations on four benchmark datasets reveal that FMRec achieves an average improvement of 6.53% over state-of-the-art methods. The replication code is available at https://github.com/FengLiu-1/FMRec.
A Survey on Side Information-driven Session-based Recommendation: From a Data-centric Perspective
May 18, 2025Session-based recommendation is gaining increasing attention due to its practical value in predicting the intents of anonymous users based on limited behaviors. Emerging efforts incorporate various side information to alleviate inherent data scarcity issues in this task, leading to impressive performance improvements. The core of side information-driven session-based recommendation is the discovery and utilization of diverse data. In this survey, we provide a comprehensive review of this task from a data-centric perspective. Specifically, this survey commences with a clear formulation of the task. This is followed by a detailed exploration of various benchmarks rich in side information that are pivotal for advancing research in this field. Afterwards, we delve into how different types of side information enhance the task, underscoring data characteristics and utility. Moreover, we discuss the usage of various side information, including data encoding, data injection, and involved techniques. A systematic review of research progress is then presented, with the taxonomy by the types of side information. Finally, we summarize the current limitations and present the future prospects of this vibrant topic.
Short-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Apr 13, 2025Recent years have witnessed significant progress in large language models' (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs' reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs' reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
WritingBench: A Comprehensive Benchmark for Generative Writing
Mar 07, 2025Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework's validity is further demonstrated by its data curation capability, which enables 7B-parameter models to approach state-of-the-art (SOTA) performance. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.
MM-StoryAgent: Immersive Narrated Storybook Video Generation with a Multi-Agent Paradigm across Text, Image and Audio
Mar 07, 2025



The rapid advancement of large language models (LLMs) and artificial intelligence-generated content (AIGC) has accelerated AI-native applications, such as AI-based storybooks that automate engaging story production for children. However, challenges remain in improving story attractiveness, enriching storytelling expressiveness, and developing open-source evaluation benchmarks and frameworks. Therefore, we propose and opensource MM-StoryAgent, which creates immersive narrated video storybooks with refined plots, role-consistent images, and multi-channel audio. MM-StoryAgent designs a multi-agent framework that employs LLMs and diverse expert tools (generative models and APIs) across several modalities to produce expressive storytelling videos. The framework enhances story attractiveness through a multi-stage writing pipeline. In addition, it improves the immersive storytelling experience by integrating sound effects with visual, music and narrative assets. MM-StoryAgent offers a flexible, open-source platform for further development, where generative modules can be substituted. Both objective and subjective evaluation regarding textual story quality and alignment between modalities validate the effectiveness of our proposed MM-StoryAgent system. The demo and source code are available.
Origin-Destination Demand Prediction: An Urban Radiation and Attraction Perspective
Nov 29, 2024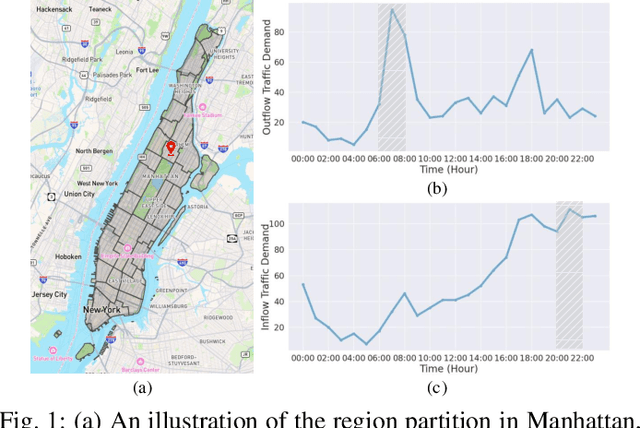
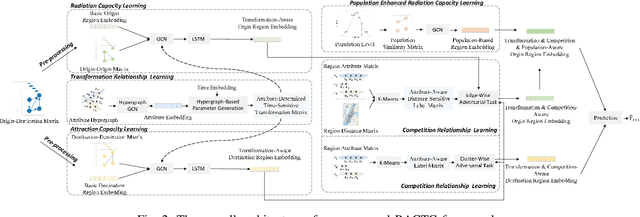
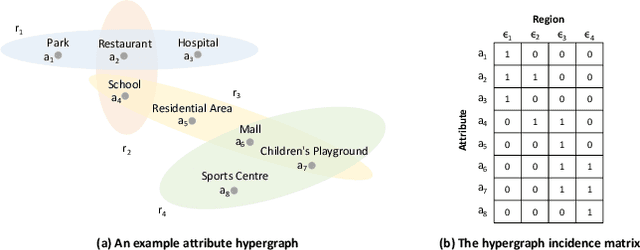
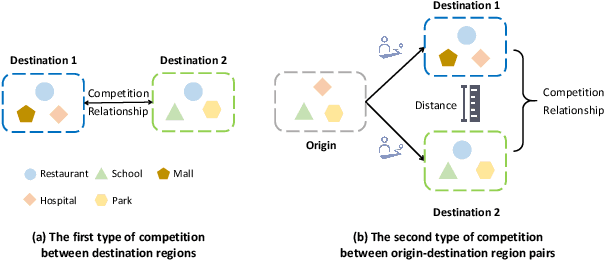
In recent years, origin-destination (OD) demand prediction has gained significant attention for its profound implications in urban development. Existing data-driven deep learning methods primarily focus on the spatial or temporal dependency between regions yet neglecting regions' fundamental functional difference. Though knowledge-driven physical methods have characterised regions' functions by their radiation and attraction capacities, these functions are defined on numerical factors like population without considering regions' intrinsic nominal attributes, e.g., a region is a residential or industrial district. Moreover, the complicated relationships between two types of capacities, e.g., the radiation capacity of a residential district in the morning will be transformed into the attraction capacity in the evening, are totally missing from physical methods. In this paper, we not only generalize the physical radiation and attraction capacities into the deep learning framework with the extended capability to fulfil regions' functions, but also present a new model that captures the relationships between two types of capacities. Specifically, we first model regions' radiation and attraction capacities using a bilateral branch network, each equipped with regions' attribute representations. We then describe the transformation relationship of different capacities of the same region using a hypergraph-based parameter generation method. We finally unveil the competition relationship of different regions with the same attraction capacity through cluster-based adversarial learning. Extensive experiments on two datasets demonstrate the consistent improvements of our method over the state-of-the-art baselines, as well as the good explainability of regions' functions using their nominal attributes.
ProFuser: Progressive Fusion of Large Language Models
Aug 09, 2024



While fusing the capacities and advantages of various large language models (LLMs) offers a pathway to construct more powerful and versatile models, a fundamental challenge is to properly select advantageous model during the training. Existing fusion methods primarily focus on the training mode that uses cross entropy on ground truth in a teacher-forcing setup to measure a model's advantage, which may provide limited insight towards model advantage. In this paper, we introduce a novel approach that enhances the fusion process by incorporating both the training and inference modes. Our method evaluates model advantage not only through cross entropy during training but also by considering inference outputs, providing a more comprehensive assessment. To combine the two modes effectively, we introduce ProFuser to progressively transition from inference mode to training mode. To validate ProFuser's effectiveness, we fused three models, including vicuna-7b-v1.5, Llama-2-7b-chat, and mpt-7b-8k-chat, and demonstrated the improved performance in knowledge, reasoning, and safety compared to baseline methods.
Efficient Sparse Attention needs Adaptive Token Release
Jul 02, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide array of text-centric tasks. However, their `large' scale introduces significant computational and storage challenges, particularly in managing the key-value states of the transformer, which limits their wider applicability. Therefore, we propose to adaptively release resources from caches and rebuild the necessary key-value states. Particularly, we accomplish this by a lightweight controller module to approximate an ideal top-$K$ sparse attention. This module retains the tokens with the highest top-$K$ attention weights and simultaneously rebuilds the discarded but necessary tokens, which may become essential for future decoding. Comprehensive experiments in natural language generation and modeling reveal that our method is not only competitive with full attention in terms of performance but also achieves a significant throughput improvement of up to 221.8%. The code for replication is available on the https://github.com/WHUIR/ADORE.
Joint Demonstration and Preference Learning Improves Policy Alignment with Human Feedback
Jun 11, 2024Aligning human preference and value is an important requirement for building contemporary foundation models and embodied AI. However, popular approaches such as reinforcement learning with human feedback (RLHF) break down the task into successive stages, such as supervised fine-tuning (SFT), reward modeling (RM), and reinforcement learning (RL), each performing one specific learning task. Such a sequential approach results in serious issues such as significant under-utilization of data and distribution mismatch between the learned reward model and generated policy, which eventually lead to poor alignment performance. We develop a single stage approach named Alignment with Integrated Human Feedback (AIHF), capable of integrating both human preference and demonstration to train reward models and the policy. The proposed approach admits a suite of efficient algorithms, which can easily reduce to, and leverage, popular alignment algorithms such as RLHF and Directly Policy Optimization (DPO), and only requires minor changes to the existing alignment pipelines. We demonstrate the efficiency of the proposed solutions with extensive experiments involving alignment problems in LLMs and robotic control problems in MuJoCo. We observe that the proposed solutions outperform the existing alignment algorithms such as RLHF and DPO by large margins, especially when the amount of high-quality preference data is relatively limited.
Getting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
May 29, 2024



Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.