 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Gao
Urban Generative Intelligence (UGI): A Foundational Platform for Agents in Embodied City Environment
Dec 19, 2023
Urban environments, characterized by their complex, multi-layered networks encompassing physical, social, economic, and environmental dimensions, face significant challenges in the face of rapid urbanization. These challenges, ranging from traffic congestion and pollution to social inequality, call for advanced technological interventions. Recent developments in big data, artificial intelligence, urban computing, and digital twins have laid the groundwork for sophisticated city modeling and simulation. However, a gap persists between these technological capabilities and their practical implementation in addressing urban challenges in an systemic-intelligent way. This paper proposes Urban Generative Intelligence (UGI), a novel foundational platform integrating Large Language Models (LLMs) into urban systems to foster a new paradigm of urban intelligence. UGI leverages CityGPT, a foundation model trained on city-specific multi-source data, to create embodied agents for various urban tasks. These agents, operating within a textual urban environment emulated by city simulator and urban knowledge graph, interact through a natural language interface, offering an open platform for diverse intelligent and embodied agent development. This platform not only addresses specific urban issues but also simulates complex urban systems, providing a multidisciplinary approach to understand and manage urban complexity. This work signifies a transformative step in city science and urban intelligence, harnessing the power of LLMs to unravel and address the intricate dynamics of urban systems. The code repository with demonstrations will soon be released here https://github.com/tsinghua-fib-lab/UGI.
Inverse Learning with Extremely Sparse Feedback for Recommendation
Nov 20, 2023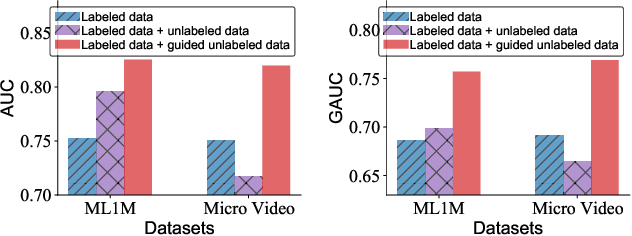
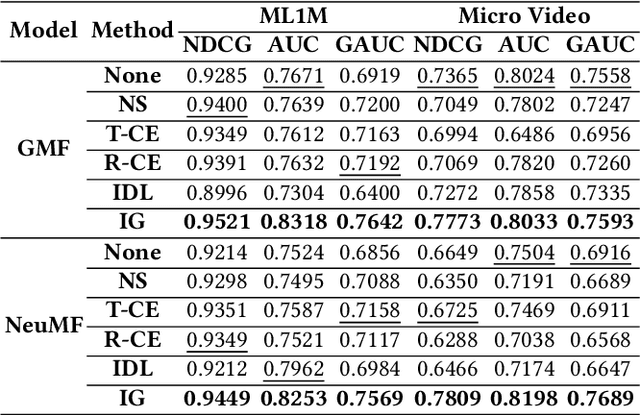
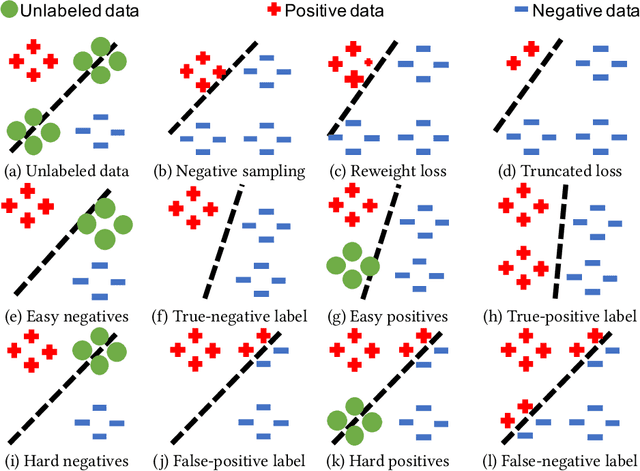
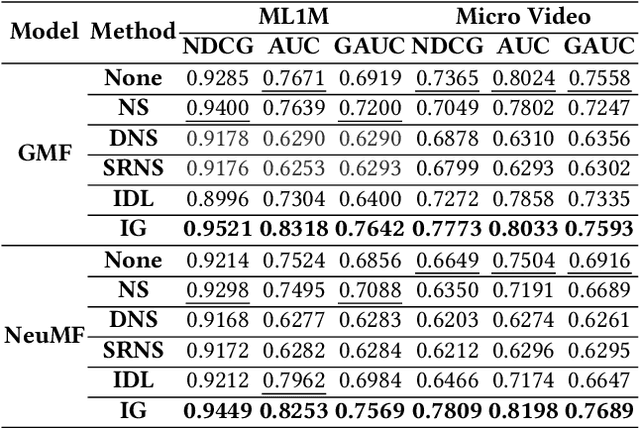
Modern personalized recommendation services often rely on user feedback, either explicit or implicit, to improve the quality of services. Explicit feedback refers to behaviors like ratings, while implicit feedback refers to behaviors like user clicks. However, in the scenario of full-screen video viewing experiences like Tiktok and Reels, the click action is absent, resulting in unclear feedback from users, hence introducing noises in modeling training. Existing approaches on de-noising recommendation mainly focus on positive instances while ignoring the noise in a large amount of sampled negative feedback. In this paper, we propose a meta-learning method to annotate the unlabeled data from loss and gradient perspectives, which considers the noises in both positive and negative instances. Specifically, we first propose an Inverse Dual Loss (IDL) to boost the true label learning and prevent the false label learning. Then we further propose an Inverse Gradient (IG) method to explore the correct updating gradient and adjust the updating based on meta-learning. Finally, we conduct extensive experiments on both benchmark and industrial datasets where our proposed method can significantly improve AUC by 9.25% against state-of-the-art methods. Further analysis verifies the proposed inverse learning framework is model-agnostic and can improve a variety of recommendation backbones. The source code, along with the best hyper-parameter settings, is available at this link: https://github.com/Guanyu-Lin/InverseLearning.
Mixed Attention Network for Cross-domain Sequential Recommendation
Nov 14, 2023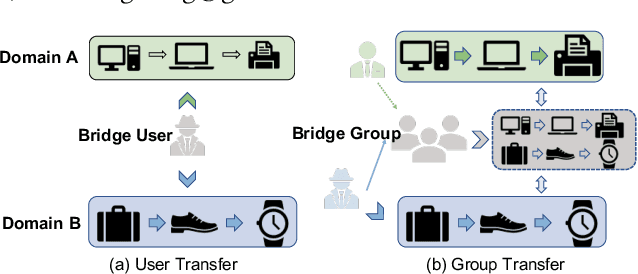
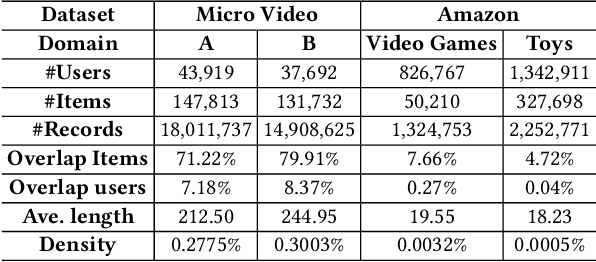
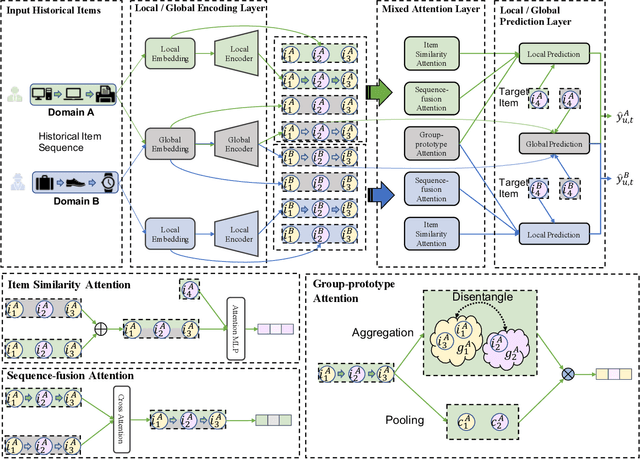
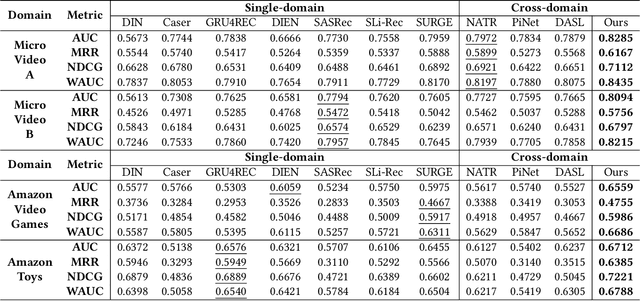
In modern recommender systems, sequential recommendation leverages chronological user behaviors to make effective next-item suggestions, which suffers from data sparsity issues, especially for new users. One promising line of work is the cross-domain recommendation, which trains models with data across multiple domains to improve the performance in data-scarce domains. Recent proposed cross-domain sequential recommendation models such as PiNet and DASL have a common drawback relying heavily on overlapped users in different domains, which limits their usage in practical recommender systems. In this paper, we propose a Mixed Attention Network (MAN) with local and global attention modules to extract the domain-specific and cross-domain information. Firstly, we propose a local/global encoding layer to capture the domain-specific/cross-domain sequential pattern. Then we propose a mixed attention layer with item similarity attention, sequence-fusion attention, and group-prototype attention to capture the local/global item similarity, fuse the local/global item sequence, and extract the user groups across different domains, respectively. Finally, we propose a local/global prediction layer to further evolve and combine the domain-specific and cross-domain interests. Experimental results on two real-world datasets (each with two domains) demonstrate the superiority of our proposed model. Further study also illustrates that our proposed method and components are model-agnostic and effective, respectively. The code and data are available at https://github.com/Guanyu-Lin/MAN.
Practical Membership Inference Attacks against Fine-tuned Large Language Models via Self-prompt Calibration
Nov 10, 2023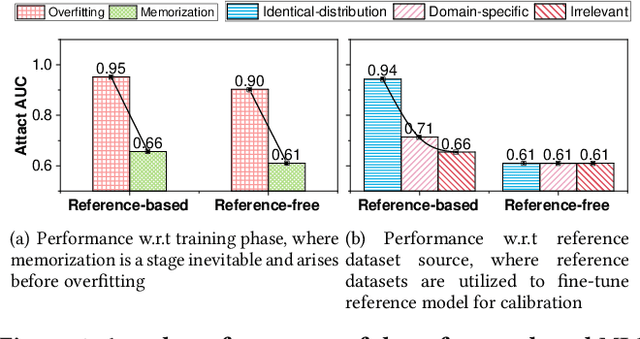

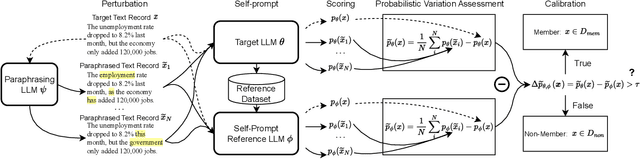
Membership Inference Attacks (MIA) aim to infer whether a target data record has been utilized for model training or not. Prior attempts have quantified the privacy risks of language models (LMs) via MIAs, but there is still no consensus on whether existing MIA algorithms can cause remarkable privacy leakage on practical Large Language Models (LLMs). Existing MIAs designed for LMs can be classified into two categories: reference-free and reference-based attacks. They are both based on the hypothesis that training records consistently strike a higher probability of being sampled. Nevertheless, this hypothesis heavily relies on the overfitting of target models, which will be mitigated by multiple regularization methods and the generalization of LLMs. The reference-based attack seems to achieve promising effectiveness in LLMs, which measures a more reliable membership signal by comparing the probability discrepancy between the target model and the reference model. However, the performance of reference-based attack is highly dependent on a reference dataset that closely resembles the training dataset, which is usually inaccessible in the practical scenario. Overall, existing MIAs are unable to effectively unveil privacy leakage over practical fine-tuned LLMs that are overfitting-free and private. We propose a Membership Inference Attack based on Self-calibrated Probabilistic Variation (SPV-MIA). Specifically, since memorization in LLMs is inevitable during the training process and occurs before overfitting, we introduce a more reliable membership signal, probabilistic variation, which is based on memorization rather than overfitting. Furthermore, we introduce a self-prompt approach, which constructs the dataset to fine-tune the reference model by prompting the target LLM itself. In this manner, the adversary can collect a dataset with a similar distribution from public APIs.
Stance Detection with Collaborative Role-Infused LLM-Based Agents
Oct 16, 2023
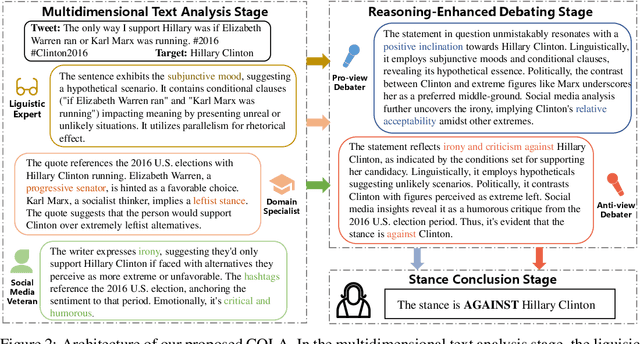
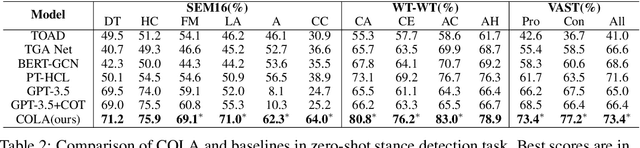
Stance detection automatically detects the stance in a text towards a target, vital for content analysis in web and social media research. Despite their promising capabilities, LLMs encounter challenges when directly applied to stance detection. First, stance detection demands multi-aspect knowledge, from deciphering event-related terminologies to understanding the expression styles in social media platforms. Second, stance detection requires advanced reasoning to infer authors' implicit viewpoints, as stance are often subtly embedded rather than overtly stated in the text. To address these challenges, we design a three-stage framework COLA (short for Collaborative rOle-infused LLM-based Agents) in which LLMs are designated distinct roles, creating a collaborative system where each role contributes uniquely. Initially, in the multidimensional text analysis stage, we configure the LLMs to act as a linguistic expert, a domain specialist, and a social media veteran to get a multifaceted analysis of texts, thus overcoming the first challenge. Next, in the reasoning-enhanced debating stage, for each potential stance, we designate a specific LLM-based agent to advocate for it, guiding the LLM to detect logical connections between text features and stance, tackling the second challenge. Finally, in the stance conclusion stage, a final decision maker agent consolidates prior insights to determine the stance. Our approach avoids extra annotated data and model training and is highly usable. We achieve state-of-the-art performance across multiple datasets. Ablation studies validate the effectiveness of each design role in handling stance detection. Further experiments have demonstrated the explainability and the versatility of our approach. Our approach excels in usability, accuracy, effectiveness, explainability and versatility, highlighting its value.
Large Language Model-Empowered Agents for Simulating Macroeconomic Activities
Oct 16, 2023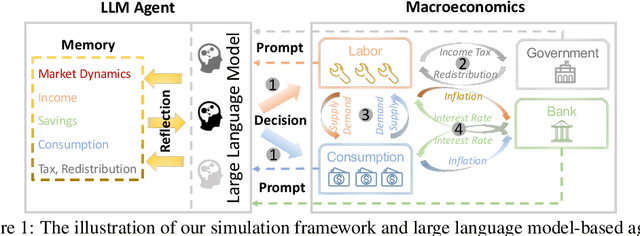
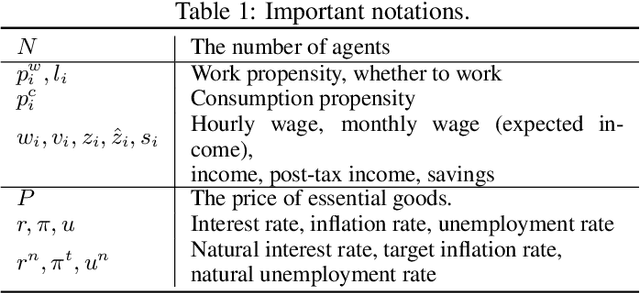
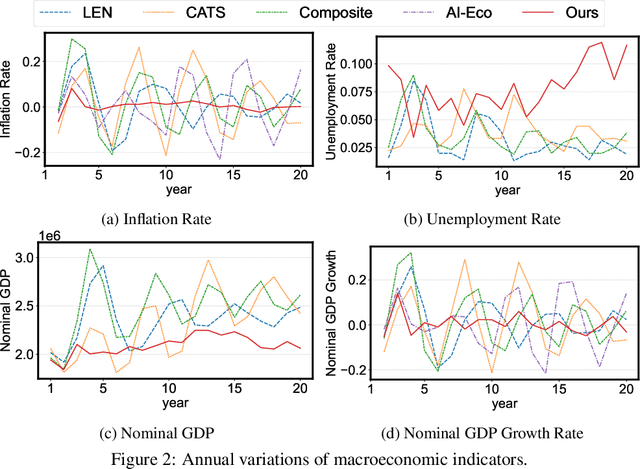
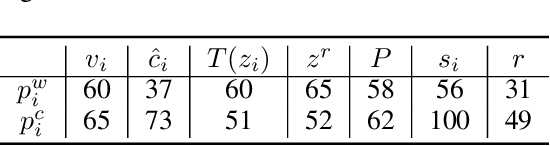
The advent of the Web has brought about a paradigm shift in traditional economics, particularly in the digital economy era, enabling the precise recording and analysis of individual economic behavior. This has led to a growing emphasis on data-driven modeling in macroeconomics. In macroeconomic research, Agent-based modeling (ABM) emerged as an alternative, evolving through rule-based agents, machine learning-enhanced decision-making, and, more recently, advanced AI agents. However, the existing works are suffering from three main challenges when endowing agents with human-like decision-making, including agent heterogeneity, the influence of macroeconomic trends, and multifaceted economic factors. Large language models (LLMs) have recently gained prominence in offering autonomous human-like characteristics. Therefore, leveraging LLMs in macroeconomic simulation presents an opportunity to overcome traditional limitations. In this work, we take an early step in introducing a novel approach that leverages LLMs in macroeconomic simulation. We design prompt-engineering-driven LLM agents to exhibit human-like decision-making and adaptability in the economic environment, with the abilities of perception, reflection, and decision-making to address the abovementioned challenges. Simulation experiments on macroeconomic activities show that LLM-empowered agents can make realistic work and consumption decisions and emerge more reasonable macroeconomic phenomena than existing rule-based or AI agents. Our work demonstrates the promising potential to simulate macroeconomics based on LLM and its human-like characteristics.
OmnimatteRF: Robust Omnimatte with 3D Background Modeling
Sep 14, 2023
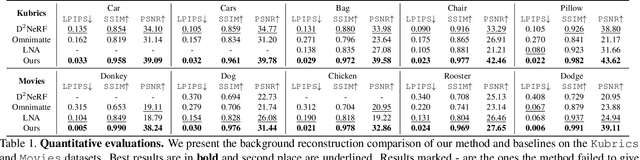
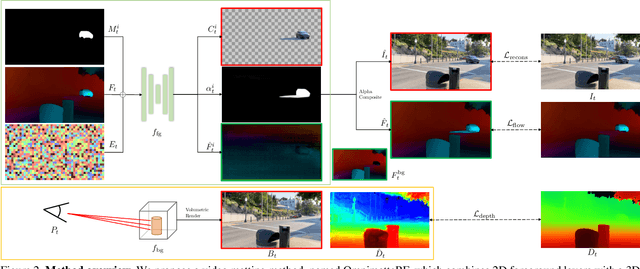

Video matting has broad applications, from adding interesting effects to casually captured movies to assisting video production professionals. Matting with associated effects such as shadows and reflections has also attracted increasing research activity, and methods like Omnimatte have been proposed to separate dynamic foreground objects of interest into their own layers. However, prior works represent video backgrounds as 2D image layers, limiting their capacity to express more complicated scenes, thus hindering application to real-world videos. In this paper, we propose a novel video matting method, OmnimatteRF, that combines dynamic 2D foreground layers and a 3D background model. The 2D layers preserve the details of the subjects, while the 3D background robustly reconstructs scenes in real-world videos. Extensive experiments demonstrate that our method reconstructs scenes with better quality on various videos.
Alleviating Video-Length Effect for Micro-video Recommendation
Aug 31, 2023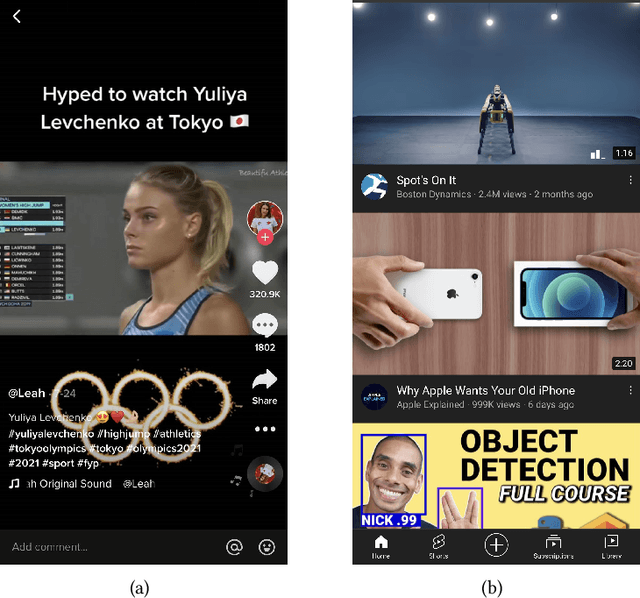

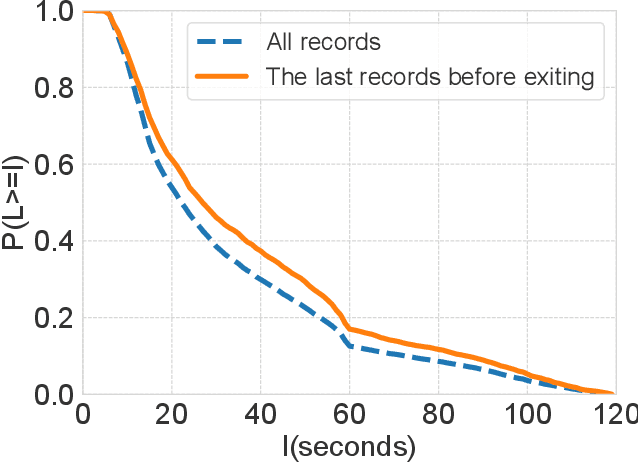
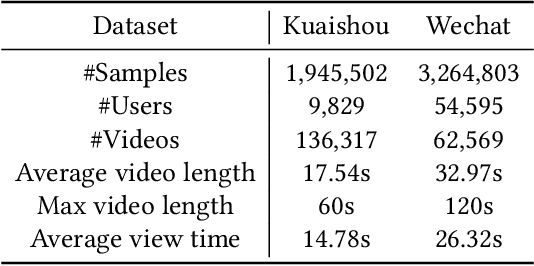
Micro-videos platforms such as TikTok are extremely popular nowadays. One important feature is that users no longer select interested videos from a set, instead they either watch the recommended video or skip to the next one. As a result, the time length of users' watching behavior becomes the most important signal for identifying preferences. However, our empirical data analysis has shown a video-length effect that long videos are easier to receive a higher value of average view time, thus adopting such view-time labels for measuring user preferences can easily induce a biased model that favors the longer videos. In this paper, we propose a Video Length Debiasing Recommendation (VLDRec) method to alleviate such an effect for micro-video recommendation. VLDRec designs the data labeling approach and the sample generation module that better capture user preferences in a view-time oriented manner. It further leverages the multi-task learning technique to jointly optimize the above samples with original biased ones. Extensive experiments show that VLDRec can improve the users' view time by 1.81% and 11.32% on two real-world datasets, given a recommendation list of a fixed overall video length, compared with the best baseline method. Moreover, VLDRec is also more effective in matching users' interests in terms of the video content.
Towards Vehicle-to-everything Autonomous Driving: A Survey on Collaborative Perception
Aug 31, 2023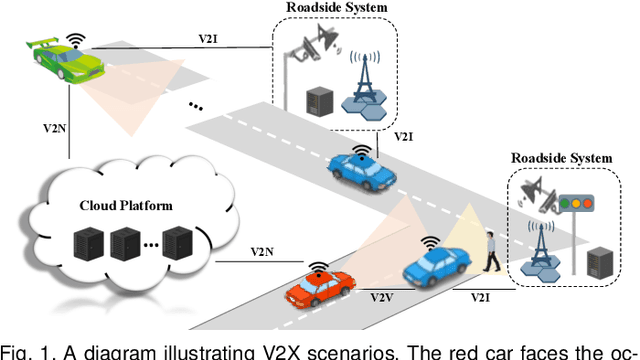
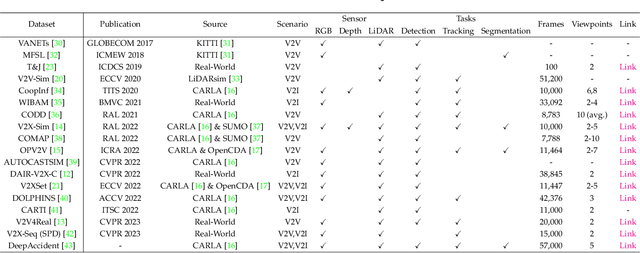
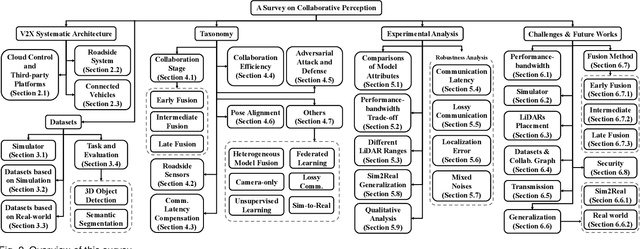
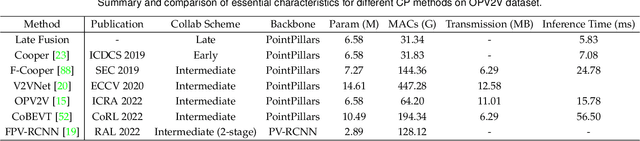
Vehicle-to-everything (V2X) autonomous driving opens up a promising direction for developing a new generation of intelligent transportation systems. Collaborative perception (CP) as an essential component to achieve V2X can overcome the inherent limitations of individual perception, including occlusion and long-range perception. In this survey, we provide a comprehensive review of CP methods for V2X scenarios, bringing a profound and in-depth understanding to the community. Specifically, we first introduce the architecture and workflow of typical V2X systems, which affords a broader perspective to understand the entire V2X system and the role of CP within it. Then, we thoroughly summarize and analyze existing V2X perception datasets and CP methods. Particularly, we introduce numerous CP methods from various crucial perspectives, including collaboration stages, roadside sensors placement, latency compensation, performance-bandwidth trade-off, attack/defense, pose alignment, etc. Moreover, we conduct extensive experimental analyses to compare and examine current CP methods, revealing some essential and unexplored insights. Specifically, we analyze the performance changes of different methods under different bandwidths, providing a deep insight into the performance-bandwidth trade-off issue. Also, we examine methods under different LiDAR ranges. To study the model robustness, we further investigate the effects of various simulated real-world noises on the performance of different CP methods, covering communication latency, lossy communication, localization errors, and mixed noises. In addition, we look into the sim-to-real generalization ability of existing CP methods. At last, we thoroughly discuss issues and challenges, highlighting promising directions for future efforts. Our codes for experimental analysis will be public at https://github.com/memberRE/Collaborative-Perception.