 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Change Loy
Deep Animation Video Interpolation in the Wild
Apr 06, 2021
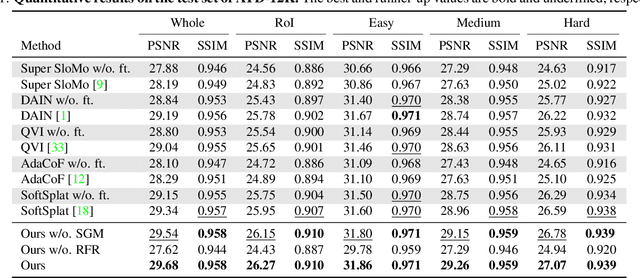

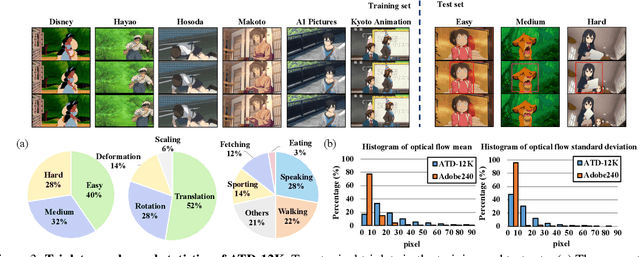
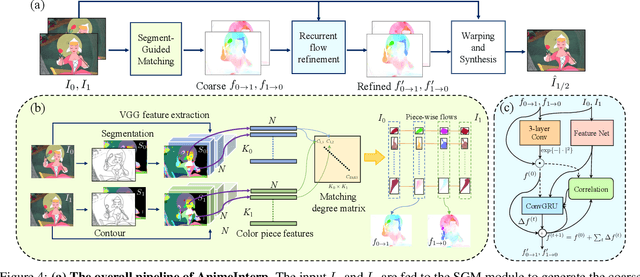
In the animation industry, cartoon videos are usually produced at low frame rate since hand drawing of such frames is costly and time-consuming. Therefore, it is desirable to develop computational models that can automatically interpolate the in-between animation frames. However, existing video interpolation methods fail to produce satisfying results on animation data. Compared to natural videos, animation videos possess two unique characteristics that make frame interpolation difficult: 1) cartoons comprise lines and smooth color pieces. The smooth areas lack textures and make it difficult to estimate accurate motions on animation videos. 2) cartoons express stories via exaggeration. Some of the motions are non-linear and extremely large. In this work, we formally define and study the animation video interpolation problem for the first time. To address the aforementioned challenges, we propose an effective framework, AnimeInterp, with two dedicated modules in a coarse-to-fine manner. Specifically, 1) Segment-Guided Matching resolves the "lack of textures" challenge by exploiting global matching among color pieces that are piece-wise coherent. 2) Recurrent Flow Refinement resolves the "non-linear and extremely large motion" challenge by recurrent predictions using a transformer-like architecture. To facilitate comprehensive training and evaluations, we build a large-scale animation triplet dataset, ATD-12K, which comprises 12,000 triplets with rich annotations. Extensive experiments demonstrate that our approach outperforms existing state-of-the-art interpolation methods for animation videos. Notably, AnimeInterp shows favorable perceptual quality and robustness for animation scenarios in the wild. The proposed dataset and code are available at https://github.com/lisiyao21/AnimeInterp/.
Domain Generalization: A Survey
Mar 31, 2021



Generalization to out-of-distribution (OOD) data is a capability natural to humans yet challenging for machines to reproduce. This is because most statistical learning algorithms strongly rely on the i.i.d.~assumption on source/target data, while in practice domain shift between source and target is common. Domain generalization (DG) aims to achieve OOD generalization by using only source data for model learning. Since first introduced in 2011, research in DG has made great progresses. In particular, intensive research in this topic has led to a broad spectrum of methodologies, e.g., those based on domain alignment, meta-learning, data augmentation, or ensemble learning, just to name a few; and has covered various applications such as object recognition, segmentation, action recognition, and person re-identification. In this paper, for the first time, a comprehensive literature review is provided to summarize the developments in DG in the past decade. Specifically, we first cover the background by formally defining DG and relating it to other research fields like domain adaptation and transfer learning. Second, we conduct a thorough review into existing methods and present a categorization based on their methodologies and motivations. Finally, we conclude this survey with insights and discussions on future research directions.
Network Pruning via Resource Reallocation
Mar 02, 2021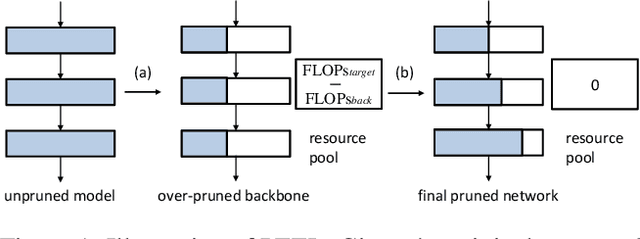
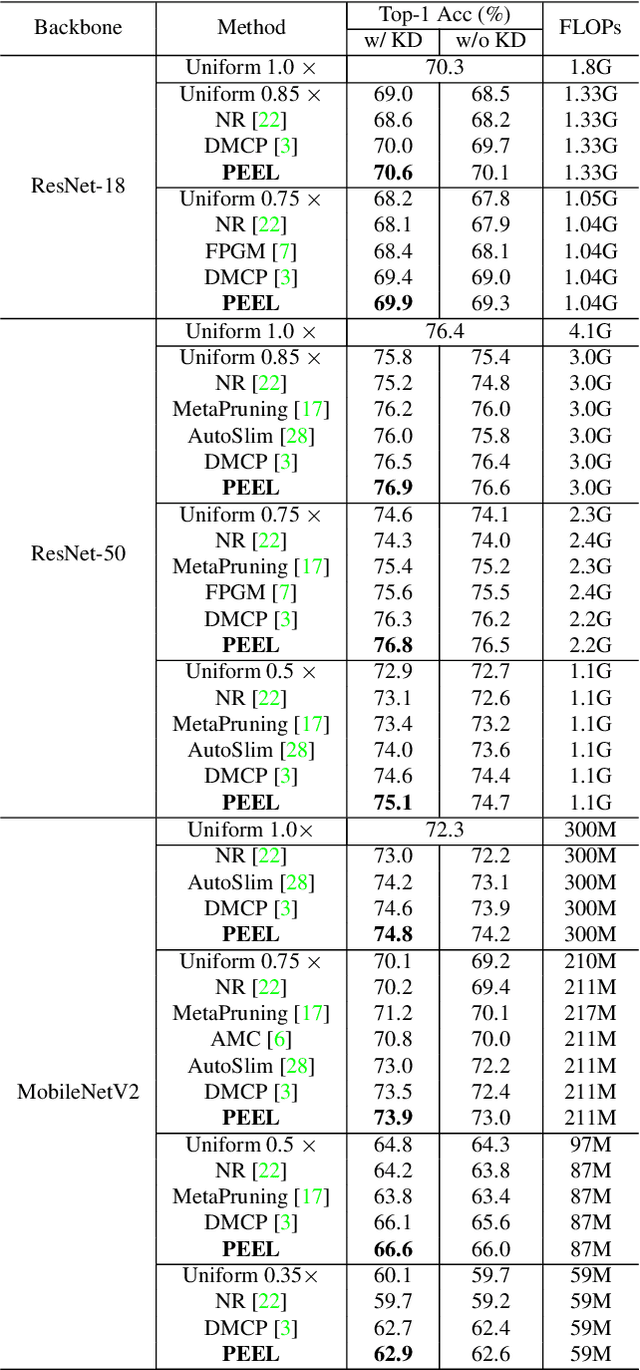
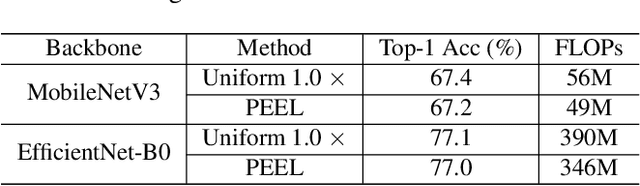
Channel pruning is broadly recognized as an effective approach to obtain a small compact model through eliminating unimportant channels from a large cumbersome network. Contemporary methods typically perform iterative pruning procedure from the original over-parameterized model, which is both tedious and expensive especially when the pruning is aggressive. In this paper, we propose a simple yet effective channel pruning technique, termed network Pruning via rEsource rEalLocation (PEEL), to quickly produce a desired slim model with negligible cost. Specifically, PEEL first constructs a predefined backbone and then conducts resource reallocation on it to shift parameters from less informative layers to more important layers in one round, thus amplifying the positive effect of these informative layers. To demonstrate the effectiveness of PEEL , we perform extensive experiments on ImageNet with ResNet-18, ResNet-50, MobileNetV2, MobileNetV3-small and EfficientNet-B0. Experimental results show that structures uncovered by PEEL exhibit competitive performance with state-of-the-art pruning algorithms under various pruning settings. Our code is available at https://github.com/cardwing/Codes-for-PEEL.
Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation
Mar 01, 2021
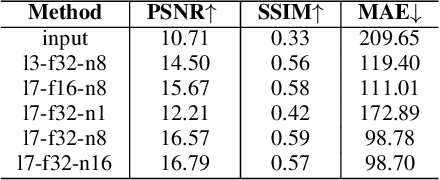
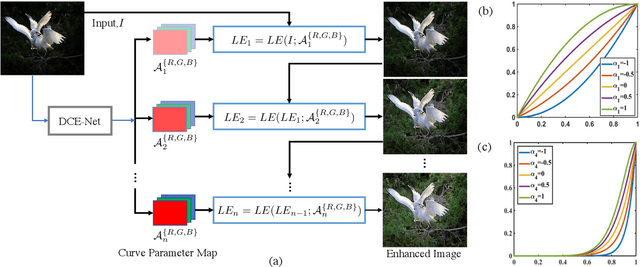
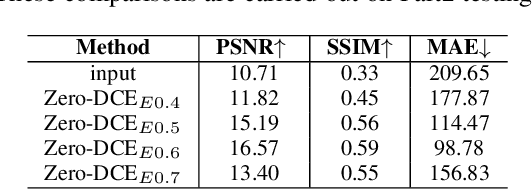
This paper presents a novel method, Zero-Reference Deep Curve Estimation (Zero-DCE), which formulates light enhancement as a task of image-specific curve estimation with a deep network. Our method trains a lightweight deep network, DCE-Net, to estimate pixel-wise and high-order curves for dynamic range adjustment of a given image. The curve estimation is specially designed, considering pixel value range, monotonicity, and differentiability. Zero-DCE is appealing in its relaxed assumption on reference images, i.e., it does not require any paired or even unpaired data during training. This is achieved through a set of carefully formulated non-reference loss functions, which implicitly measure the enhancement quality and drive the learning of the network. Despite its simplicity, we show that it generalizes well to diverse lighting conditions. Our method is efficient as image enhancement can be achieved by an intuitive and simple nonlinear curve mapping. We further present an accelerated and light version of Zero-DCE, called Zero-DCE++, that takes advantage of a tiny network with just 10K parameters. Zero-DCE++ has a fast inference speed (1000/11 FPS on a single GPU/CPU for an image of size 1200*900*3) while keeping the enhancement performance of Zero-DCE. Extensive experiments on various benchmarks demonstrate the advantages of our method over state-of-the-art methods qualitatively and quantitatively. Furthermore, the potential benefits of our method to face detection in the dark are discussed. The source code will be made publicly available at https://li-chongyi.github.io/Proj_Zero-DCE++.html.
FASA: Feature Augmentation and Sampling Adaptation for Long-Tailed Instance Segmentation
Feb 25, 2021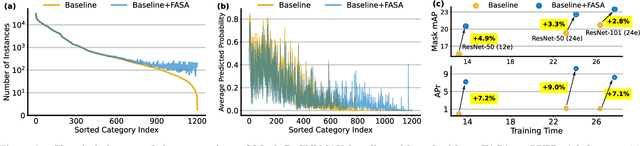
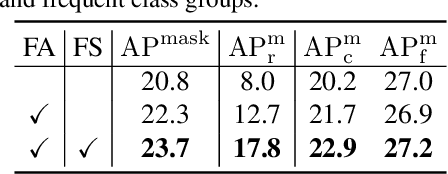
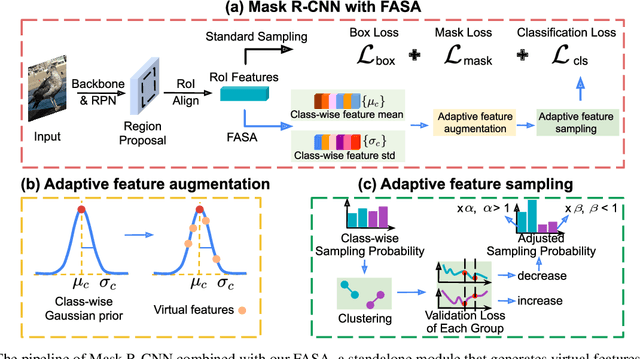
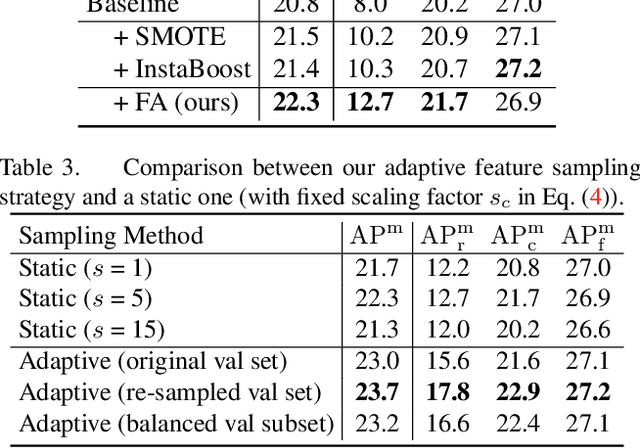
Recent methods for long-tailed instance segmentation still struggle on rare object classes with few training data. We propose a simple yet effective method, Feature Augmentation and Sampling Adaptation (FASA), that addresses the data scarcity issue by augmenting the feature space especially for rare classes. Both the Feature Augmentation (FA) and feature sampling components are adaptive to the actual training status -- FA is informed by the feature mean and variance of observed real samples from past iterations, and we sample the generated virtual features in a loss-adapted manner to avoid over-fitting. FASA does not require any elaborate loss design, and removes the need for inter-class transfer learning that often involves large cost and manually-defined head/tail class groups. We show FASA is a fast, generic method that can be easily plugged into standard or long-tailed segmentation frameworks, with consistent performance gains and little added cost. FASA is also applicable to other tasks like long-tailed classification with state-of-the-art performance. Code will be released.
DeeperForensics Challenge 2020 on Real-World Face Forgery Detection: Methods and Results
Feb 18, 2021
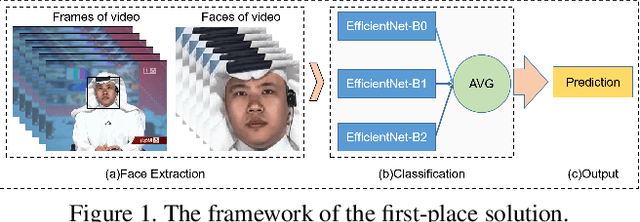
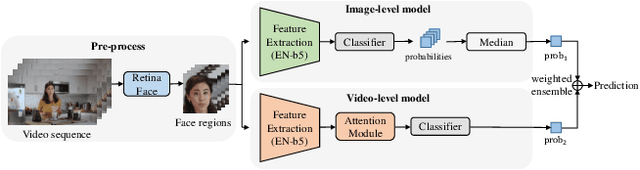
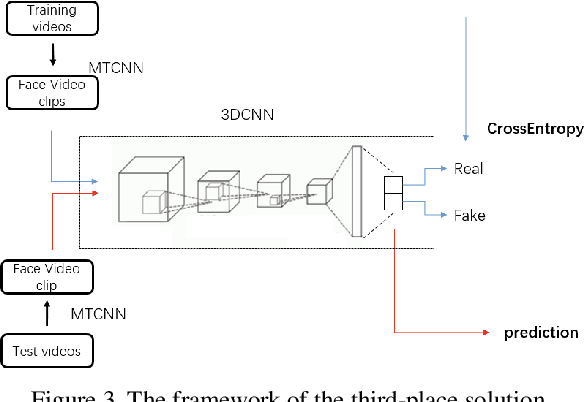
This paper reports methods and results in the DeeperForensics Challenge 2020 on real-world face forgery detection. The challenge employs the DeeperForensics-1.0 dataset, one of the most extensive publicly available real-world face forgery detection datasets, with 60,000 videos constituted by a total of 17.6 million frames. The model evaluation is conducted online on a high-quality hidden test set with multiple sources and diverse distortions. A total of 115 participants registered for the competition, and 25 teams made valid submissions. We will summarize the winning solutions and present some discussions on potential research directions.
Chasing the Tail in Monocular 3D Human Reconstruction with Prototype Memory
Dec 29, 2020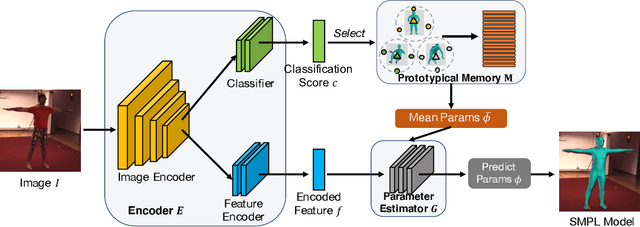
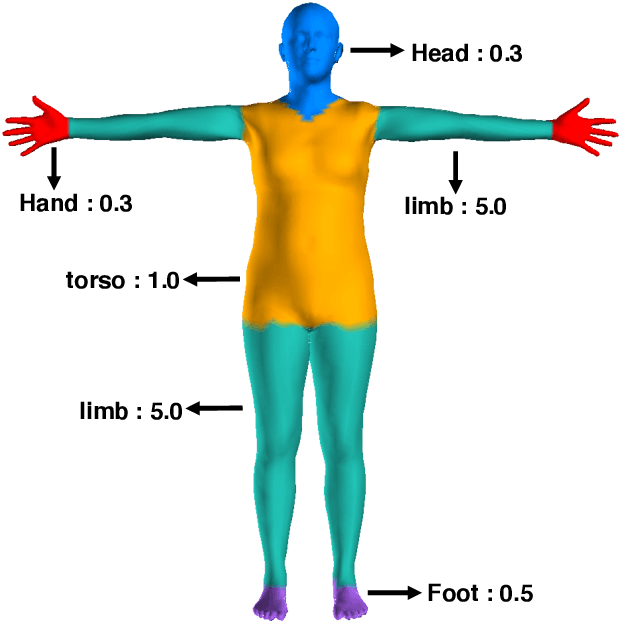

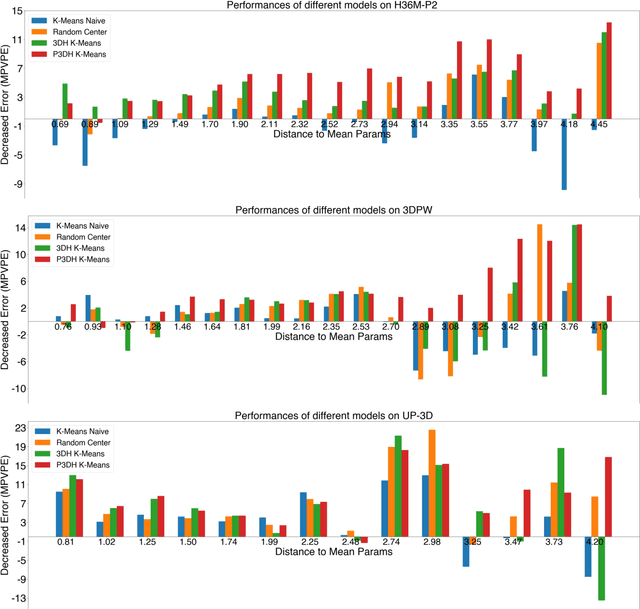
Deep neural networks have achieved great progress in single-image 3D human reconstruction. However, existing methods still fall short in predicting rare poses. The reason is that most of the current models perform regression based on a single human prototype, which is similar to common poses while far from the rare poses. In this work, we 1) identify and analyze this learning obstacle and 2) propose a prototype memory-augmented network, PM-Net, that effectively improves performances of predicting rare poses. The core of our framework is a memory module that learns and stores a set of 3D human prototypes capturing local distributions for either common poses or rare poses. With this formulation, the regression starts from a better initialization, which is relatively easier to converge. Extensive experiments on several widely employed datasets demonstrate the proposed framework's effectiveness compared to other state-of-the-art methods. Notably, our approach significantly improves the models' performances on rare poses while generating comparable results on other samples.
Focal Frequency Loss for Generative Models
Dec 23, 2020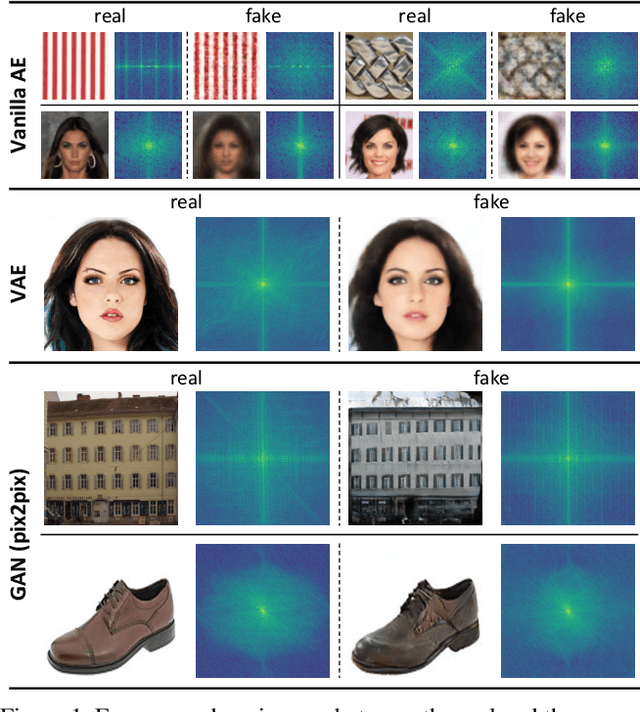
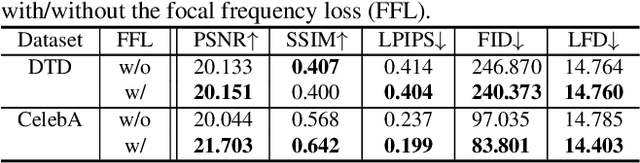

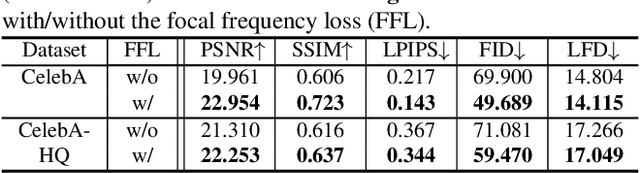
Despite the remarkable success of generative models in creating photorealistic images using deep neural networks, gaps could still exist between the real and generated images, especially in the frequency domain. In this study, we find that narrowing the frequency domain gap can ameliorate the image synthesis quality further. To this end, we propose the focal frequency loss, a novel objective function that brings optimization of generative models into the frequency domain. The proposed loss allows the model to dynamically focus on the frequency components that are hard to synthesize by down-weighting the easy frequencies. This objective function is complementary to existing spatial losses, offering great impedance against the loss of important frequency information due to the inherent crux of neural networks. We demonstrate the versatility and effectiveness of focal frequency loss to improve various baselines in both perceptual quality and quantitative performance.
Multi-Modality Cut and Paste for 3D Object Detection
Dec 23, 2020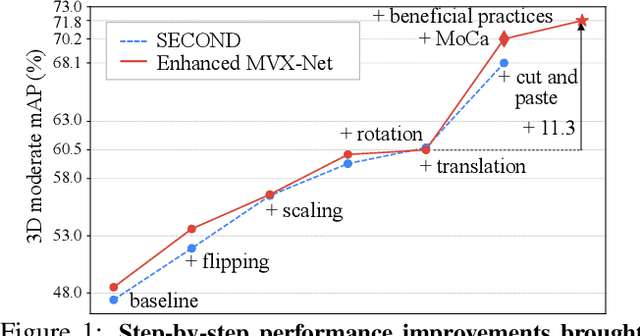
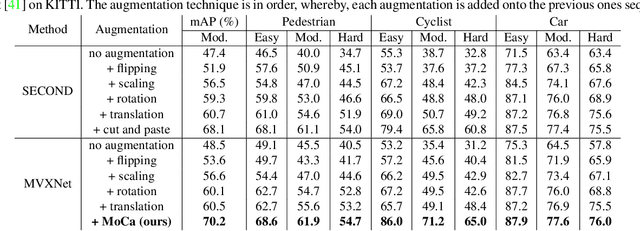
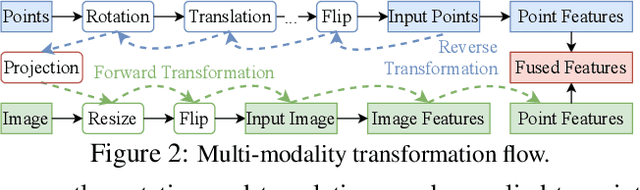
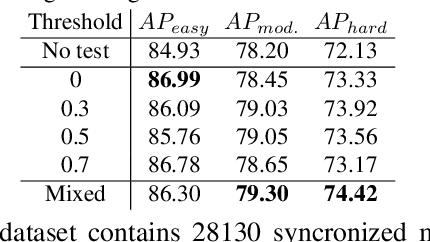
Three-dimensional (3D) object detection is essential in autonomous driving. There are observations that multi-modality methods based on both point cloud and imagery features perform only marginally better or sometimes worse than approaches that solely use single-modality point cloud. This paper investigates the reason behind this counter-intuitive phenomenon through a careful comparison between augmentation techniques used by single modality and multi-modality methods. We found that existing augmentations practiced in single-modality detection are equally useful for multi-modality detection. Then we further present a new multi-modality augmentation approach, Multi-mOdality Cut and pAste (MoCa). MoCa boosts detection performance by cutting point cloud and imagery patches of ground-truth objects and pasting them into different scenes in a consistent manner while avoiding collision between objects. We also explore beneficial architecture design and optimization practices in implementing a good multi-modality detector. Without using ensemble of detectors, our multi-modality detector achieves new state-of-the-art performance on nuScenes dataset and competitive performance on KITTI 3D benchmark. Our method also wins the best PKL award in the 3rd nuScenes detection challenge. Code and models will be released at https://github.com/open-mmlab/mmdetection3d.