 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMA: Semantic-Difference Instruction-Grounding Mask Annotator for Text-Driven Image Manipulation Localization
May 27, 2026Text-driven image editing has advanced rapidly, but reliably localizing these manipulations requires image manipulation localization (IML) models trained on large pixel-annotated datasets, and there is still no low-cost way to obtain such training data at scale. We observe that these data already exist in disguise: public editing datasets contain millions of structurally identical (original, edited) pairs to IML training samples, lacking only pixel-level masks. Recovering these masks automatically is non-trivial: pixel differencing is overwhelmed by diffusion-induced perturbations across all pixels, and instruction-only grounding localizes only what the prompt describes, missing unintended editor side-effects. We propose SIGMA (Semantic-difference Instruction-Grounding Mask Annotator), which performs semantic-feature differencing in a vision foundation backbone and injects an instruction-derived spatial prior into this visual stream via bidirectional cross-modal refinement, amplifying the difference signal at intended-edit regions when the editor faithfully realizes user intent. SIGMA is trained in two complementary stages: Stage I supervises on inpainting masks; Stage II closes the diffusion-domain shift via VAE-roundtrip noise calibration, EMA self-training, and an edit-noise disentanglement loss. SIGMA outperforms existing automatic mask generators on five benchmarks (+12.20% F1, +11.16% IoU). When applied to public editing corpora, it produces a ~1.1M IML training set that improves six diverse detectors by +18.34% F1 across five datasets, turning previously unused editing data into a model-agnostic supervisory resource for IML. We'll release the full codebase as soon as the paper is accepted.
GGD-SLAM: Monocular 3DGS SLAM Powered by Generalizable Motion Model for Dynamic Environments
Apr 14, 2026Visual SLAM algorithms achieve significant improvements through the exploration of 3D Gaussian Splatting (3DGS) representations, particularly in generating high-fidelity dense maps. However, they depend on a static environment assumption and experience significant performance degradation in dynamic environments. This paper presents GGD-SLAM, a framework that employs a generalizable motion model to address the challenges of localization and dense mapping in dynamic environments - without predefined semantic annotations or depth input. Specifically, the proposed system employs a First-In-First-Out (FIFO) queue to manage incoming frames, facilitating dynamic semantic feature extraction through a sequential attention mechanism. This is integrated with a dynamic feature enhancer to separate static and dynamic components. Additionally, to minimize dynamic distractors' impact on the static components, we devise a method to fill occluded areas via static information sampling and design a distractor-adaptive Structure Similarity Index Measure (SSIM) loss tailored for dynamic environments, significantly enhancing the system's resilience. Experiments conducted on real-world dynamic datasets demonstrate that the proposed system achieves state-of-the-art performance in camera pose estimation and dense reconstruction in dynamic scenes.
NavCrafter: Exploring 3D Scenes from a Single Image
Apr 03, 2026Creating flexible 3D scenes from a single image is vital when direct 3D data acquisition is costly or impractical. We introduce NavCrafter, a novel framework that explores 3D scenes from a single image by synthesizing novel-view video sequences with camera controllability and temporal-spatial consistency. NavCrafter leverages video diffusion models to capture rich 3D priors and adopts a geometry-aware expansion strategy to progressively extend scene coverage. To enable controllable multi-view synthesis, we introduce a multi-stage camera control mechanism that conditions diffusion models with diverse trajectories via dual-branch camera injection and attention modulation. We further propose a collision-aware camera trajectory planner and an enhanced 3D Gaussian Splatting (3DGS) pipeline with depth-aligned supervision, structural regularization and refinement. Extensive experiments demonstrate that NavCrafter achieves state-of-the-art novel-view synthesis under large viewpoint shifts and substantially improves 3D reconstruction fidelity.
GEN3D: Generating Domain-Free 3D Scenes from a Single Image
Nov 18, 2025Despite recent advancements in neural 3D reconstruction, the dependence on dense multi-view captures restricts their broader applicability. Additionally, 3D scene generation is vital for advancing embodied AI and world models, which depend on diverse, high-quality scenes for learning and evaluation. In this work, we propose Gen3d, a novel method for generation of high-quality, wide-scope, and generic 3D scenes from a single image. After the initial point cloud is created by lifting the RGBD image, Gen3d maintains and expands its world model. The 3D scene is finalized through optimizing a Gaussian splatting representation. Extensive experiments on diverse datasets demonstrate the strong generalization capability and superior performance of our method in generating a world model and Synthesizing high-fidelity and consistent novel views.
ReLoc: A Restoration-Assisted Framework for Robust Image Tampering Localization
Nov 08, 2022



With the spread of tampered images, locating the tampered regions in digital images has drawn increasing attention. The existing image tampering localization methods, however, suffer from severe performance degradation when the tampered images are subjected to some post-processing, as the tampering traces would be distorted by the post-processing operations. The poor robustness against post-processing has become a bottleneck for the practical applications of image tampering localization techniques. In order to address this issue, this paper proposes a novel restoration-assisted framework for image tampering localization (ReLoc). The ReLoc framework mainly consists of an image restoration module and a tampering localization module. The key idea of ReLoc is to use the restoration module to recover a high-quality counterpart of the distorted tampered image, such that the distorted tampering traces can be re-enhanced, facilitating the tampering localization module to identify the tampered regions. To achieve this, the restoration module is optimized not only with the conventional constraints on image visual quality but also with a forensics-oriented objective function. Furthermore, the restoration module and the localization module are trained alternately, which can stabilize the training process and is beneficial for improving the performance. The proposed framework is evaluated by fighting against JPEG compression, the most commonly used post-processing. Extensive experimental results show that ReLoc can significantly improve the robustness against JPEG compression. The restoration module in a well-trained ReLoc model is transferable. Namely, it is still effective when being directly deployed with another tampering localization module.
DeeperForensics Challenge 2020 on Real-World Face Forgery Detection: Methods and Results
Feb 18, 2021
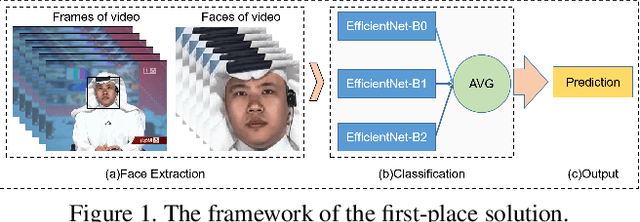
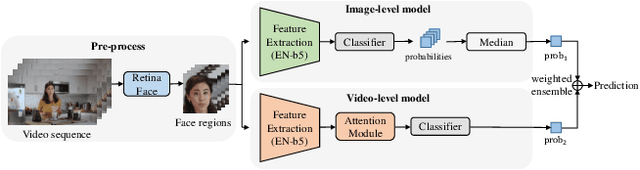
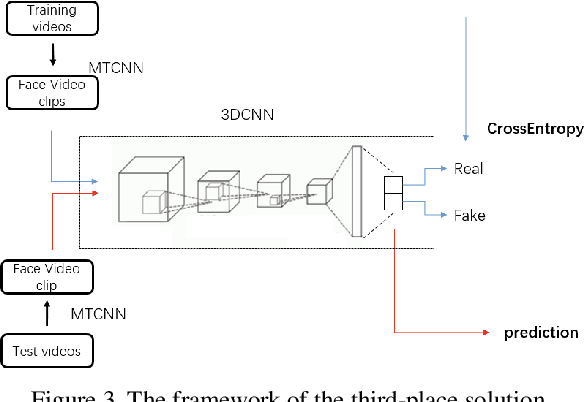
This paper reports methods and results in the DeeperForensics Challenge 2020 on real-world face forgery detection. The challenge employs the DeeperForensics-1.0 dataset, one of the most extensive publicly available real-world face forgery detection datasets, with 60,000 videos constituted by a total of 17.6 million frames. The model evaluation is conducted online on a high-quality hidden test set with multiple sources and diverse distortions. A total of 115 participants registered for the competition, and 25 teams made valid submissions. We will summarize the winning solutions and present some discussions on potential research directions.